Quantization: bài toán dịch thuật 70 năm tuổi mà mọi AI engineer đều đang dùng mà không biết
Từ Lloyd-Max 1957 đến GPTQ 2023 — lịch sử, toán học, và code chi tiết của quantization. Bạn đang dùng Q4_K_M mỗi ngày nhưng có hiểu bên trong là gì không?

Lần đầu tiên mình nghe đến khái niệm quantization là năm 2018, khi đang cố nhét một con model object detection vào cái Jetson TX2 cho cuộc thi Cuộc Đua Số năm đó. Mình làm theo cách ngây thơ nhất có thể: cast toàn bộ weight từ FP32 sang INT8, không calibration, không scale factor, không hiểu gì cả — cứ .to(torch.int8) rồi chạy. Kết quả: accuracy tụt gần nửa.
Từ đó đến giờ, mình vẫn dùng quantization — nhưng theo kiểu khác. Suốt gần hai năm chạy local LLM, mình download hàng chục file GGUF (format đóng gói model đã quantized của llama.cpp — chuẩn de facto cho local LLM) với đủ loại suffix: Q4_K_M, Q5_K_S, Q8_0. Mình biết Q4 nhẹ hơn Q8, biết K_M "cân bằng" hơn K_S, biết rằng nếu VRAM không đủ thì cứ giảm bit xuống. Mình dùng quantization như dùng thuốc — tin rằng nó hoạt động, đọc liều lượng trên nhãn, rồi nuốt. Không bao giờ hỏi tại sao cái thuốc này chữa được bệnh mà cái kia thì không.
Cho đến tuần trước, khi mình ngồi viết bài về TurboQuant — paper nén KV cache của Google — và phải giải thích Lloyd-Max quantizer cho người đọc. Mình gõ được nửa đoạn rồi dừng lại, vì nhận ra mình đang giải thích một thứ mà chính mình chỉ hiểu nửa vời. Mình biết Lloyd-Max "tối ưu hơn uniform quantization", nhưng tối ưu theo nghĩa nào? Mình biết GPTQ "dùng Hessian", nhưng Hessian ở đây làm gì cụ thể? Mình biết INT4 "mất precision", nhưng precision mất ở đâu, bao nhiêu, và có đo được không?
Thế là mình dừng viết TurboQuant, mở một tab mới, và bắt đầu đào từ đầu. Từ paper gốc của Stuart Lloyd năm 1957. Từ lý thuyết thông tin của Shannon. Từ cái bài toán mà — hóa ra — đã tồn tại trước khi máy tính cá nhân ra đời.
Và cái mình tìm được thú vị hơn mình tưởng nhiều. Quantization không phải là "nén model cho bớt nặng". Nó là một bài toán dịch thuật — dịch từ ngôn ngữ liên tục (floating point) sang ngôn ngữ rời rạc (integer) mà không mất nghĩa. Và giống mọi bài toán dịch, cách bạn chọn từ điển quyết định tất cả.
Bài này là companion piece cho bài TurboQuant. Nếu bạn đọc bài đó và thắc mắc "Lloyd-Max là gì? Tại sao phân phối lại quan trọng? Uniform quantization hoạt động ra sao?" — bài này trả lời tất cả. Và nếu bạn chưa đọc bài TurboQuant, đọc bài này trước rồi quay lại đọc — mình cá bạn sẽ thấy nhiều thứ hơn.
Quantization là gì, thật sự?

Hầu hết mọi giải thích về quantization bắt đầu bằng "giảm số bit để tiết kiệm bộ nhớ". Đúng, nhưng đó là mô tả hệ quả, không phải bản chất. Giống như nói "dịch thuật là chuyển từ tiếng này sang tiếng khác" — không sai, nhưng bỏ qua toàn bộ phần khó: làm sao giữ được nghĩa?
Quantization, ở cốt lõi, là việc ánh xạ một tập vô hạn (các số thực) vào một tập hữu hạn (các số nguyên). Bạn có một giá trị liên tục — ví dụ 0.37248 — và bạn phải "dịch" nó thành một trong $2^b$ giá trị rời rạc có sẵn, với $b$ là số bit bạn có. Với 8 bit, bạn có 256 lựa chọn. Với 4 bit, bạn có 16. Với 2 bit, bạn có 4.
Bạn đã gặp quantization từ lâu rồi mà không biết. Khi bạn nghe nhạc qua file digital, mỗi sample âm thanh là một giá trị liên tục (biên độ sóng âm) được quantize thành 16-bit integer (CD audio) hoặc 24-bit (studio). Khi bạn chụp ảnh, mỗi pixel là cường độ ánh sáng liên tục được quantize thành 8-bit per channel (0-255 RGB). Máy ảnh, microphone, sensor nhiệt độ — tất cả đều quantize. Con người sống trong thế giới analog, máy tính sống trong thế giới digital. Quantization là cầu nối.
Formally, một quantizer $Q$ gồm hai phần:
Encoder — quyết định giá trị đầu vào $x$ thuộc "bucket" nào:
$$\text{encode}(x) = i \quad \text{sao cho } x \in [b_{i-1}, b_i)$$
Decoder — gán mỗi bucket một giá trị đại diện (centroid/reconstruction value):
$$\text{decode}(i) = c_i$$
Kết hợp lại:
$$Q(x) = c_i \quad \text{where } i = \arg\min_j |x - c_j|$$
Và câu hỏi cốt lõi — câu hỏi mà 70 năm qua người ta vẫn đang trả lời — là: đặt các boundary $b_i$ ở đâu, đặt các centroid $c_i$ ở đâu, để distortion nhỏ nhất?
$$D = \mathbb{E}\left[(X - Q(X))^2\right]$$
Distortion là mean squared error trung bình giữa giá trị gốc và giá trị sau khi quantize. Bạn muốn nó càng nhỏ càng tốt. Và cái cách bạn minimize nó — cách bạn chọn "từ điển" — là toàn bộ cuộc chơi.
Uniform quantization: cách đơn giản nhất, và tại sao nó thường đủ tốt

Cách tiếp cận đầu tiên mà ai cũng nghĩ ra: chia đều khoảng giá trị thành $2^b$ phần bằng nhau. Đây gọi là uniform quantization, và nó đơn giản đến mức bạn có thể implement trong 10 dòng Python.
Ý tưởng: tìm giá trị nhỏ nhất và lớn nhất trong data, chia khoảng đó thành $2^b$ bucket cách đều, rồi map mỗi giá trị về bucket gần nhất. Cụ thể, bạn cần hai tham số:
Scale factor — kích thước của mỗi bucket:
$$s = \frac{x_{\max} - x_{\min}}{2^b - 1}$$
Zero-point — offset để map khoảng giá trị gốc về khoảng integer:
$$z = \text{round}\left(-\frac{x_{\min}}{s}\right)$$
Quantize (float → int):
$$x_q = \text{clamp}\left(\text{round}\left(\frac{x}{s}\right) + z, \; 0, \; 2^b - 1\right)$$
Dequantize (int → float xấp xỉ):
$$\hat{x} = s \cdot (x_q - z)$$
Đó là tất cả. Toàn bộ phép quantize gói gọn trong bốn phương trình. $s$ và $z$ là metadata — bạn lưu chúng kèm theo data quantized để có thể dequantize lại.
Có hai biến thể chính:
Symmetric quantization: ép zero-point = 0, map khoảng $[-r, r]$ với $r = \max(|x_{\max}|, |x_{\min}|)$. Đơn giản hơn, hardware-friendly, nhưng nếu data lệch về một phía (ví dụ toàn dương sau ReLU), bạn lãng phí nửa khoảng giá trị.
Asymmetric quantization: dùng cả zero-point, map đúng khoảng $[x_{\min}, x_{\max}]$. Tận dụng tốt hơn dải giá trị nhưng cần thêm phép tính khi inference.
Để bạn thấy nó đơn giản thế nào trong code:
import torch
def uniform_quantize(x: torch.Tensor, bits: int = 8):
"""Asymmetric uniform quantization."""
x_min, x_max = x.min(), x.max()
qmin, qmax = 0, 2**bits - 1
# Scale và zero-point
scale = (x_max - x_min) / (qmax - qmin)
zero_point = torch.round(-x_min / scale).clamp(qmin, qmax)
# Quantize: float -> int
x_q = torch.clamp(torch.round(x / scale) + zero_point, qmin, qmax).to(torch.int8)
# Dequantize: int -> float (xấp xỉ)
x_deq = scale * (x_q.float() - zero_point)
return x_q, x_deq, scale, zero_point
# Thử với một tensor weight giả
torch.manual_seed(42)
w = torch.randn(1000) # Gaussian, giống weight distribution thật
w_q, w_deq, s, z = uniform_quantize(w, bits=4) # 4-bit quantization
error = (w - w_deq).abs().mean()
print(f"4-bit | Scale: {s:.4f} | Mean abs error: {error:.4f}")
# Output: 4-bit | Scale: 0.0479 | Mean abs error: 0.0129
w_q8, w_deq8, s8, z8 = uniform_quantize(w, bits=8)
error8 = (w - w_deq8).abs().mean()
print(f"8-bit | Scale: {s8:.6f} | Mean abs error: {error8:.6f}")
# Output: 8-bit | Scale: 0.002991 | Mean abs error: 0.000747
Hai điều đáng chú ý từ output. Thứ nhất, 8-bit quantize một tensor Gaussian gần như lossless — error trung bình 0.00075, tức 0.075% so với standard deviation. Đó là lý do INT8 inference hoạt động tốt đến vậy cho hầu hết model: phân phối weight trong neural network thường khá Gaussian, và 256 bucket chia đều là quá đủ.
Thứ hai, khi giảm xuống 4-bit, error nhảy lên 17 lần (0.0129 vs 0.00075). Chỉ 16 bucket cho toàn bộ dải giá trị. Nếu weight của bạn có outlier — vài giá trị cực lớn hoặc cực nhỏ — uniform quantization sẽ kéo scale ra rộng, và 14/16 bucket sẽ dồn vào vùng giữa nơi có ít data. Bạn mất resolution ở chỗ quan trọng nhất.
Đây là lúc bạn bắt đầu cần thứ gì đó thông minh hơn.
Granularity: một scale cho tất cả, hay mỗi nhóm một scale?

Trước khi nói đến non-uniform quantization, có một trick đơn giản hơn mà thực tế dùng rất nhiều: thay đổi granularity — tức là thay vì dùng một cặp $(s, z)$ cho toàn bộ tensor, bạn dùng nhiều cặp $(s, z)$ cho từng phần nhỏ hơn.
Per-tensor quantization: một scale, một zero-point cho toàn bộ ma trận weight. Nhanh nhất, ít metadata nhất, nhưng nếu channel 0 có range [-0.1, 0.1] còn channel 42 có range [-3.0, 3.0], bạn bắt cả hai dùng chung scale → channel 0 mất gần hết precision.
Per-channel quantization: mỗi output channel (mỗi hàng trong weight matrix) có scale và zero-point riêng. Standard cho CNN inference, vì mỗi filter có dynamic range khác nhau. PyTorch quantization dùng cách này mặc định.
Per-group quantization: chia mỗi hàng thành các nhóm $G$ phần tử, mỗi nhóm có scale riêng. GPTQ và AWQ mặc định dùng $G = 128$. Đây là sweet spot giữa accuracy và overhead — bạn thêm $2/G$ metadata per element (scale + zero-point cho mỗi group), nhưng đổi lại mỗi nhóm 128 giá trị được quantize với range sát thực tế hơn.
Để thấy sự khác biệt:
import torch
def per_tensor_quantize(W, bits=4):
"""Quantize toàn bộ tensor với 1 scale."""
s = (W.max() - W.min()) / (2**bits - 1)
z = torch.round(-W.min() / s)
W_q = torch.clamp(torch.round(W / s) + z, 0, 2**bits - 1)
return s * (W_q - z)
def per_channel_quantize(W, bits=4):
"""Quantize mỗi hàng với scale riêng."""
result = torch.zeros_like(W)
for i in range(W.shape[0]):
row = W[i]
s = (row.max() - row.min()) / (2**bits - 1)
if s == 0: continue
z = torch.round(-row.min() / s)
row_q = torch.clamp(torch.round(row / s) + z, 0, 2**bits - 1)
result[i] = s * (row_q - z)
return result
# Weight matrix giả: mỗi channel có range khác nhau
torch.manual_seed(42)
W = torch.randn(64, 256)
W[0] *= 10 # Channel 0 có outlier
W[32] *= 0.01 # Channel 32 rất nhỏ
err_tensor = (W - per_tensor_quantize(W)).abs().mean()
err_channel = (W - per_channel_quantize(W)).abs().mean()
print(f"Per-tensor error: {err_tensor:.4f}")
print(f"Per-channel error: {err_channel:.4f}")
print(f"Improvement: {err_tensor/err_channel:.1f}x")
# Per-tensor error: 0.0387
# Per-channel error: 0.0128
# Improvement: 3.0x
3 lần tốt hơn chỉ bằng cách cho mỗi channel một scale riêng. Không thay đổi gì về thuật toán quantization, chỉ thay đổi đơn vị áp dụng. Đây là lý do per-group quantization (G=128) trở thành default trong hầu hết LLM quantization tools — nó là "free lunch" gần nhất mà bạn có.
Nhưng dù granularity có mịn đến đâu, bạn vẫn đang chia đều khoảng giá trị. Và nếu phân phối data không đều — mà nó gần như không bao giờ đều — bạn đang lãng phí bucket. Câu hỏi tự nhiên tiếp theo: nếu biết data tập trung ở đâu, tại sao không đặt nhiều bucket hơn ở chỗ đó?
Non-uniform quantization và Lloyd-Max: bài toán 70 năm tuổi

Năm 1957, Stuart Lloyd — một kỹ sư tại Bell Labs — viết một bản memo nội bộ giải quyết chính xác câu hỏi đó. Bản memo này không được publish chính thức cho đến năm 1982 (25 năm sau!), nhưng ý tưởng đã lan truyền trong giới signal processing. Năm 1960, Joel Max độc lập phát triển cùng phương pháp. Ngày nay chúng ta gọi nó là Lloyd-Max quantizer.
Ý tưởng cực kỳ tự nhiên: thay vì chia đều khoảng giá trị, hãy chia sao cho mỗi bucket chứa cùng một lượng "xác suất". Nơi nào data tập trung nhiều, đặt nhiều bucket hơn (bucket nhỏ hơn, resolution cao hơn). Nơi nào data thưa, đặt ít bucket (bucket lớn, resolution thấp, nhưng ít data ở đó nên không sao).
Formally, bạn muốn tìm bộ centroid ${c_1, c_2, \ldots, c_K}$ và boundary ${b_0, b_1, \ldots, b_K}$ sao cho distortion nhỏ nhất:
$$D = \int_{-\infty}^{\infty} (x - Q(x))^2 \cdot f(x) \, dx = \sum_{i=1}^{K} \int_{b_{i-1}}^{b_i} (x - c_i)^2 \cdot f(x) \, dx$$
Với $f(x)$ là probability density function của data. Lloyd-Max chứng minh rằng bộ tối ưu phải thỏa hai điều kiện:
Điều kiện 1 — Nearest neighbor encoding: mỗi boundary nằm chính giữa hai centroid liền kề:
$$b_i = \frac{c_i + c_{i+1}}{2}$$
Điều kiện 2 — Centroid condition: mỗi centroid là conditional mean của data trong bucket đó:
$$c_i = \frac{\int_{b_{i-1}}^{b_i} x \cdot f(x) \, dx}{\int_{b_{i-1}}^{b_i} f(x) \, dx} = \mathbb{E}[X \mid b_{i-1} \leq X < b_i]$$
Hai điều kiện này tạo thành một hệ phương trình mà bạn giải bằng cách lặp: khởi tạo centroid ngẫu nhiên → tính boundary theo điều kiện 1 → cập nhật centroid theo điều kiện 2 → lặp cho đến hội tụ. Nếu bạn nhận ra đây chính là k-means trong 1 chiều — đúng, Lloyd-Max quantizer chính là nguồn gốc của k-means clustering. Lịch sử đi vòng.
Implement nó không khó:
import numpy as np
def lloyd_max(data, n_levels, max_iter=100, tol=1e-6):
"""Lloyd-Max optimal quantizer.
Args:
data: 1D numpy array — samples từ phân phối cần quantize
n_levels: số centroid (2^bits)
max_iter: số vòng lặp tối đa
tol: ngưỡng hội tụ
Returns:
centroids: vị trí tối ưu của các centroid
boundaries: boundary giữa các bucket
"""
# Khởi tạo: chia đều khoảng data thành n_levels centroid
centroids = np.linspace(data.min(), data.max(), n_levels)
for iteration in range(max_iter):
# Bước 1: tính boundary = midpoint giữa centroid liền kề
boundaries = (centroids[:-1] + centroids[1:]) / 2
boundaries = np.concatenate([[-np.inf], boundaries, [np.inf]])
# Bước 2: cập nhật centroid = mean của data trong mỗi bucket
new_centroids = np.zeros_like(centroids)
for i in range(n_levels):
mask = (data >= boundaries[i]) & (data < boundaries[i + 1])
if mask.sum() > 0:
new_centroids[i] = data[mask].mean()
else:
new_centroids[i] = centroids[i] # bucket rỗng, giữ nguyên
# Kiểm tra hội tụ
if np.max(np.abs(new_centroids - centroids)) < tol:
break
centroids = new_centroids
return centroids, boundaries
# Phân phối Gaussian — giống weight distribution trong neural net
np.random.seed(42)
data = np.random.randn(100000)
# So sánh 4-level (2-bit) uniform vs Lloyd-Max
n_levels = 4 # 2-bit
# Uniform: chia đều
uniform_centroids = np.linspace(data.min(), data.max(), n_levels)
uniform_q = uniform_centroids[np.argmin(
np.abs(data[:, None] - uniform_centroids[None, :]), axis=1
)]
uniform_mse = np.mean((data - uniform_q) ** 2)
# Lloyd-Max: tối ưu
lm_centroids, lm_boundaries = lloyd_max(data, n_levels)
lm_q = lm_centroids[np.argmin(
np.abs(data[:, None] - lm_centroids[None, :]), axis=1
)]
lm_mse = np.mean((data - lm_q) ** 2)
print(f"Uniform centroids: {uniform_centroids}")
print(f"Lloyd-Max centroids: {lm_centroids}")
print(f"\nUniform MSE: {uniform_mse:.4f}")
print(f"Lloyd-Max MSE: {lm_mse:.4f}")
print(f"Improvement: {uniform_mse / lm_mse:.2f}x")
# Output:
# Uniform centroids: [-4.17 -1.39 1.39 4.17]
# Lloyd-Max centroids: [-1.51 -0.45 0.45 1.51]
#
# Uniform MSE: 0.3757
# Lloyd-Max MSE: 0.1175
# Improvement: 3.20x
Nhìn vào centroids để thấy sự khác biệt. Uniform chia đều khoảng [-4.17, 4.17], đặt hai centroid ở ±4.17 và ±1.39. Nhưng gần như không có data nào ở vùng ±4 (đuôi Gaussian) — hai bucket đó gần như rỗng, lãng phí 2 trong 4 centroid cho vùng không có ai.
Lloyd-Max thông minh hơn: dồn cả 4 centroid vào vùng [-1.51, 1.51] — chính xác nơi 87% data Gaussian tập trung. Kết quả: MSE giảm hơn 3 lần. Với chỉ 2 bit. Không thay đổi số bit, không thêm metadata, chỉ đặt centroid đúng chỗ.
Đây chính là cái quantizer mà paper TurboQuant sử dụng. Nhưng họ làm một bước thông minh hơn nữa: thay vì chạy Lloyd-Max trên data thật (cần calibration, mỗi model khác nhau), họ xoay data bằng random rotation để nó luôn là Gaussian — rồi pre-compute Lloyd-Max cho Gaussian một lần duy nhất và xài lại cho mọi model. Nếu bạn muốn hiểu chi tiết trick xoay đó, bài TurboQuant giải thích kỹ.
70 năm quantization: từ Bell Labs đến GPU cluster
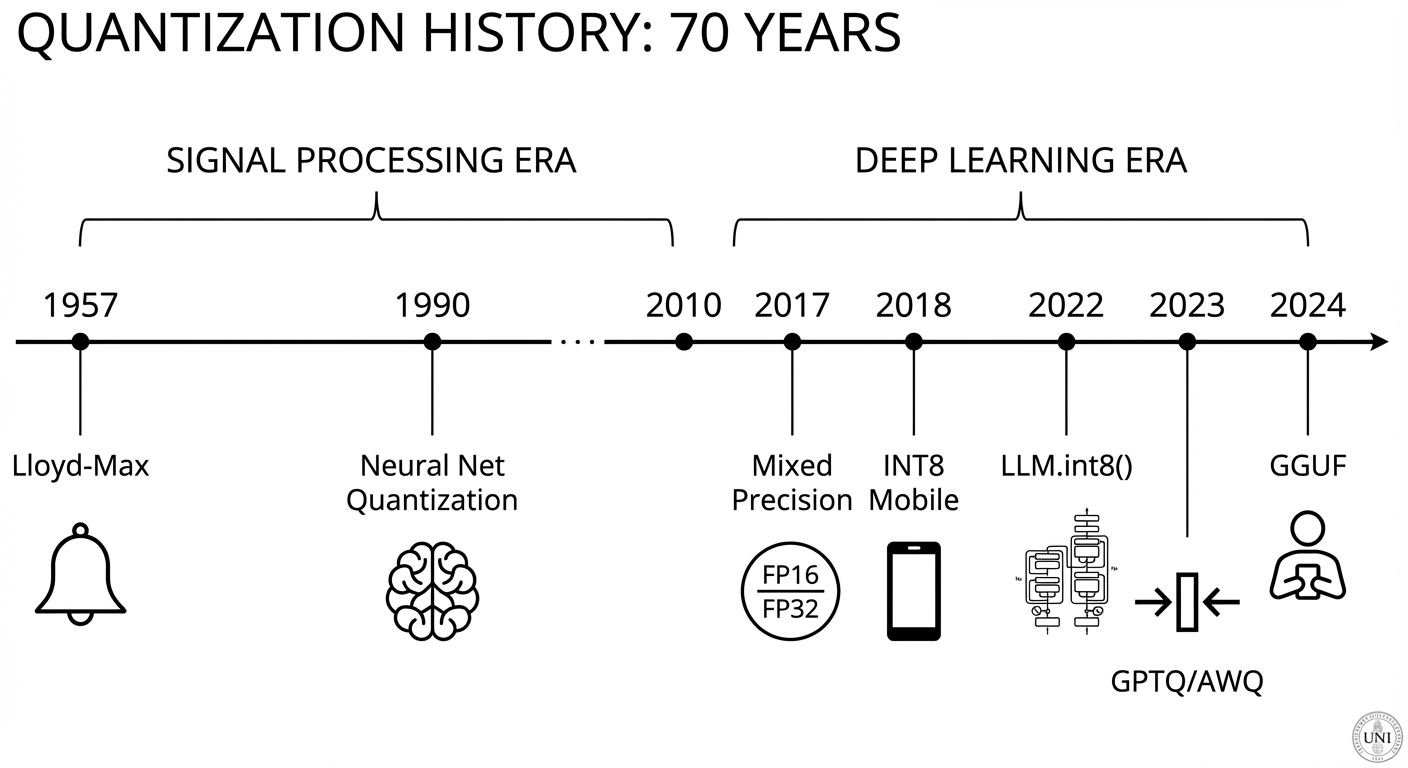
Quantization không phải phát minh của deep learning. Nó có lịch sử riêng, dài hơn cả lịch sử máy tính cá nhân. Và hiểu timeline này giúp mình thấy rõ hơn một pattern: mỗi bước tiến không phải "nén tốt hơn" — mà là xây một từ điển dịch tốt hơn, phù hợp hơn với loại data cần dịch.
| Năm | Sự kiện | Tại sao quan trọng |
|---|---|---|
| 1948 | Shannon's Information Theory | Đặt nền tảng: có giới hạn lý thuyết cho việc nén tín hiệu mà không mất thông tin (rate-distortion theory). Mọi quantizer đều sống dưới giới hạn này. |
| 1957-60 | Lloyd-Max Quantizer | Giải bài toán "đặt centroid ở đâu cho phân phối biết trước" — optimal scalar quantizer. Vẫn dùng nguyên vẹn 70 năm sau (TurboQuant 2025). |
| 1980 | Linde-Buzo-Gray (LBG) | Mở rộng Lloyd-Max sang vector quantization — quantize cả block giá trị cùng lúc thay vì từng số. Tiền thân của product quantization (PQ) trong FAISS. |
| 1990 | Fiesler et al. | Đề xuất quantize weight của neural network lần đầu tiên, dưới tên "continuous-discrete learning". Không GPU, không practical — nhưng idea đã có. |
| 2011 | Vanhoucke et al. | Chứng minh rằng quantize neural net xuống 8-bit trên CPU hoạt động được thực tế. Bài paper lặng lẽ mà có ảnh hưởng lớn. |
| 2017 | Mixed-Precision Training (Micikevicius) | Train với FP16, accumulate với FP32. Tốc độ tăng 2-3x, accuracy giữ nguyên. NVIDIA Volta GPU (V100) hỗ trợ native. Thay đổi cách cả industry train model. |
| 2018 | Google INT8 Inference (Jacob et al., CVPR) | Integer-only inference cho mobile. Cái này đưa quantization từ research vào sản phẩm thật (TensorFlow Lite, Android). |
| 2019 | BFLOAT16 (Google TPU) | Một format số kỳ lạ: hy sinh mantissa (precision), giữ exponent (range) giống FP32. Hóa ra training quan tâm đến range hơn precision — một insight quan trọng. |
| 2022 | LLM.int8() (Dettmers et al.) | Phát hiện rằng transformer có outlier features — vài channel có activation lớn gấp 100x. Giải pháp: mixed-precision, outlier giữ FP16. Mở đường cho LLM quantization. |
| 2023 | GPTQ (Frantar & Alistarh, ICLR) | One-shot weight quantization dùng Hessian. Lần đầu chạy GPT-175B trên một GPU. Thay đổi cuộc chơi cho local LLM. |
| 2023 | AWQ (Lin et al., MLSys Best Paper 2024) | Nhận ra 1% weights quan trọng 100x. Thay vì giữ chúng ở precision cao (đắt), scale chúng lên trước khi quantize (rẻ). Elegant. |
| 2023 | QuIP (Chee et al., NeurIPS) | 2-bit quantization với incoherence processing + E8 lattice codebook. Đẩy giới hạn xuống sub-4-bit lần đầu. |
| 2024 | GGUF + llama.cpp | Quantization đi vào tay consumer. Q4_K_M trở thành từ mà hàng triệu người dùng local LLM biết mà không cần hiểu paper. |
Nhìn cả timeline, bạn thấy một chuyển dịch quan trọng: trước 2022, quantization chủ yếu là bài toán hardware — làm sao chạy model trên mobile, trên edge, trên CPU rẻ. Từ 2022, nó trở thành bài toán survival — model quá to, VRAM quá đắt, không quantize thì không chạy được. Động lực thay đổi hoàn toàn, và cùng với nó là một loạt kỹ thuật mới mà deep learning truyền thống chưa bao giờ cần.
PTQ vs QAT: hai trường phái quantize
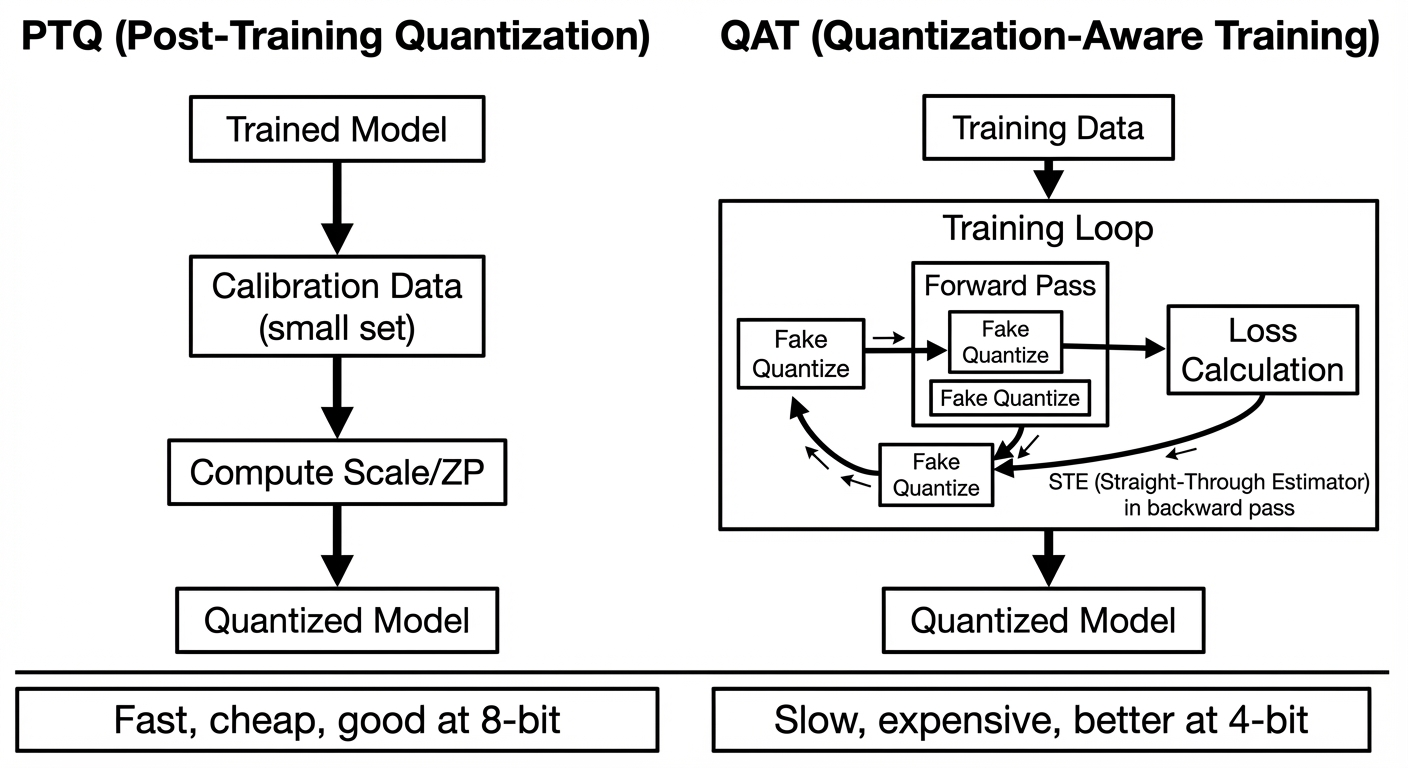
Khi bạn muốn quantize một model, có hai con đường.
Post-Training Quantization (PTQ) — quantize sau khi model đã train xong. Bạn lấy model FP16, chạy một calibration set nhỏ (vài trăm đến vài nghìn sample) qua model để thu thập statistics (min, max, percentile của mỗi layer), rồi dùng statistics đó để tính scale và zero-point. Xong. Model quantized sẵn sàng dùng.
Ưu điểm: nhanh (vài phút đến vài giờ), không cần training data đầy đủ, không cần GPU để retrain. Nhược điểm: ở bit thấp (INT4 trở xuống), accuracy có thể tụt đáng kể vì model chưa bao giờ "thấy" quantization noise trong quá trình học.
Quantization-Aware Training (QAT) — simulate quantization trong khi train. Bạn chèn các "fake quantization" node vào graph: mỗi weight và activation được quantize rồi dequantize lại (round-trip) trong forward pass, nhưng gradient vẫn chạy qua bình thường trong backward pass. Model học cách "sống chung" với quantization noise.
Nhưng chờ — nếu bạn quantize (round) trong forward pass, thì backward pass sẽ có gradient = 0 ở hầu hết mọi nơi (vì round() có đạo hàm = 0 gần như everywhere). Đây là vấn đề. Giải pháp là Straight-Through Estimator (STE) — một trick nổi tiếng trong deep learning:
$$\frac{\partial L}{\partial x} \approx \frac{\partial L}{\partial Q(x)}$$
Dịch: khi tính gradient, giả vờ rằng quantization không tồn tại — pass gradient thẳng qua, như thể $Q$ là identity function. Nghe phi lý nhưng hoạt động. Model vẫn học được vì forward pass có quantization noise, nên weights dần dịch chuyển về vùng mà quantization error nhỏ. STE chỉ cần gradient hướng đúng, không cần chính xác.
Ưu điểm QAT: accuracy tốt hơn PTQ đáng kể ở bit thấp (Llama 3 QAT 4-bit recover được ~96% accuracy loss so với PTQ). Nhược điểm: cần retrain, cần GPU, cần thời gian. Với model 70B+ parameter, QAT đắt đến mức hầu hết người dùng không có lựa chọn — PTQ là bắt buộc.
Đó là lý do tại sao GPTQ, AWQ, và toàn bộ dòng nghiên cứu quantization cho LLM tập trung vào PTQ — làm sao "nén" model sau khi train mà không mất quá nhiều. Và để làm được điều đó, họ cần những trick thông minh hơn uniform quantization rất nhiều.
GPTQ: khi Hessian chỉ đường

GPTQ (Frantar & Alistarh, ICLR 2023) là paper thay đổi cuộc chơi cho local LLM. Lần đầu tiên, một model 175B parameter có thể chạy trên một GPU duy nhất. Ý tưởng cốt lõi không phức tạp khi bạn đã hiểu nền tảng ở trên — nhưng cách implement rất elegant.
Bài toán: bạn có weight matrix $W$ (đã train xong), và bạn muốn tìm $\hat{W}$ quantized sao cho output của layer gần như không đổi. Cụ thể, bạn muốn minimize:
$$|WX - \hat{W}X|_2^2$$
Với $X$ là activation (input) của layer đó. Đây là điểm khác biệt đầu tiên: GPTQ không minimize error trên weight, mà minimize error trên output. Hai thứ đó không giống nhau — một weight có giá trị lớn nhưng nhân với activation gần 0 thì error trên weight không quan trọng.
Khi bạn khai triển bài toán trên, Hessian matrix xuất hiện tự nhiên: $H = 2XX^T$. Ma trận này cho bạn biết output nhạy cảm thế nào với thay đổi ở mỗi weight. Diagonal $H_{ii}$ lớn = weight $i$ rất nhạy cảm, quantize nó sẽ gây lỗi lớn. Diagonal nhỏ = weight đó "dễ tính", bạn quantize thoải mái.
GPTQ quantize từng cột (column) của weight matrix, từ trái sang phải. Mỗi khi quantize một cột, nó tính lỗi (sai số giữa giá trị gốc và giá trị quantized), rồi redistribute lỗi đó sang các cột chưa quantize bằng Hessian inverse:
$$\boldsymbol{\delta}F = -\frac{w_q - \text{quant}(w_q)}{[H^{-1}{FF}]{qq}} \cdot (H^{-1}{FF})_{:,q}$$
Dịch sang tiếng người: "lỗi do quantize cột $q$ được bù lại bằng cách điều chỉnh các cột còn lại — điều chỉnh bao nhiêu tùy vào Hessian inverse, tức tùy vào mỗi cột 'chịu được' bao nhiêu error mà không ảnh hưởng output."
# Pseudocode GPTQ (simplified, illustrative)
import torch
def gptq_quantize(W, H_inv, bits=4, group_size=128):
"""Simplified GPTQ: quantize column-by-column with error compensation.
W: weight matrix [out_features, in_features]
H_inv: inverse Hessian [in_features, in_features]
"""
n_cols = W.shape[1]
W_hat = W.clone()
for col in range(n_cols):
# Quantize cột hiện tại
w = W_hat[:, col]
w_q = uniform_quantize_column(w, bits) # round về grid
# Tính error
error = (w - w_q)
# Redistribute error sang các cột chưa quantize
# bằng Hessian inverse — cột nào "chịu được" thì nhận nhiều hơn
if col + 1 < n_cols:
compensation = error.unsqueeze(1) * H_inv[col, col+1:] / H_inv[col, col]
W_hat[:, col+1:] += compensation
W_hat[:, col] = w_q
return W_hat
Trong thực tế, GPTQ không quantize từng cột mà quantize từng block 128 cột (lazy batch updates) để tối ưu computation. Nhưng concept giống hệt: quantize → tính lỗi → redistribute bằng Hessian → quantize tiếp.
Kết quả: model 175B quantize xuống 4-bit trong vài giờ trên 1 GPU, gần như không mất accuracy. Đó là lý do hàng triệu GGUF file trên Hugging Face tồn tại — phần lớn được quantize bằng GPTQ hoặc các biến thể của nó.
AWQ & GGUF — nhìn nhanh
AWQ (Activation-Aware Weight Quantization, MLSys 2024 Best Paper) đi một hướng khác. Thay vì dùng Hessian, nó hỏi một câu hỏi đơn giản: weight nào quan trọng nhất?
Câu trả lời không nằm ở bản thân weight — mà ở activation. Nếu activation tương ứng lớn, thì weight đó quan trọng vì nó nhân với số lớn, sai lệch nhỏ trong weight sẽ bị amplify. Lin et al. phát hiện rằng chỉ khoảng 1% channels có activation lớn hơn hẳn — "salient channels". Nếu giữ những weight tương ứng ở precision cao, accuracy hầu như không tụt.
Nhưng mixed-precision (giữ 1% ở FP16, 99% ở INT4) phức tạp về hardware. Trick của AWQ: thay vì giữ salient weights ở precision cao, scale chúng lên trước khi quantize. Nhân weight với $s > 1$ → giá trị lớn hơn → ít bị ảnh hưởng bởi rounding error → dequantize lại chia cho $s$. Rẻ, đơn giản, và hoạt động tốt đến mức đạt Best Paper.
GGUF — nếu bạn dùng local LLM, bạn gần như chắc chắn đã gặp format này. Nó là format file mà llama.cpp sử dụng, chứa model đã quantized ở nhiều precision khác nhau. Đây là cái bảng giải mã:
| Ký hiệu | Ý nghĩa | VRAM (7B model) | Khi nào dùng |
|---|---|---|---|
| Q8_0 | 8-bit, block size 32 | ~7.5 GB | Muốn gần FP16, có đủ VRAM |
| Q6_K | 6-bit, super-block 256 | ~5.5 GB | Sweet spot cho accuracy |
| Q5_K_M | 5-bit mixed, importance-weighted | ~5.0 GB | Balance tốt |
| Q4_K_M | 4-bit mixed, importance-weighted | ~4.0 GB | Phổ biến nhất — đủ tốt cho hầu hết use case |
| Q4_K_S | 4-bit mixed, small | ~3.8 GB | Tiết kiệm hơn Q4_K_M, chất lượng thấp hơn chút |
| Q3_K_M | 3-bit mixed | ~3.3 GB | Khi thật sự thiếu VRAM |
| Q2_K | 2-bit | ~2.7 GB | Experimental, quality tụt rõ |
Chữ "K" trong K-quants nghĩa là importance-based: llama.cpp chạy một calibration set nhỏ, đo sensitivity của từng layer, rồi allocate bit-width khác nhau cho từng layer. Layer nhạy cảm được giữ ở precision cao hơn. "M" = medium (balance), "S" = small (tiết kiệm hơn), "L" = large (chất lượng hơn).
Rule of thumb mà mình dùng: bắt đầu với Q4_K_M. Nếu output kỳ quặc, lên Q5_K_M. Nếu model quá to cho VRAM, xuống Q3_K_M nhưng chuẩn bị tinh thần chất lượng tụt ở reasoning dài. Q8_0 gần như identical với FP16 — nếu fit VRAM thì không có lý do gì dùng FP16.
GPTQ, AWQ, và GGUF K-quants — mỗi cái là một cách chọn "từ điển dịch" khác nhau. GPTQ dùng Hessian để biết weight nào quan trọng. AWQ dùng activation. K-quants dùng layer sensitivity. Nhưng tất cả đều đang giải cùng một bài toán mà Lloyd đã đặt ra năm 1957: đặt centroid ở đâu để distortion nhỏ nhất?
LLM quantization — một cuộc chơi khác

Tất cả những gì mình viết ở trên — uniform quantization, Lloyd-Max, PTQ vs QAT — là nền tảng chung cho mọi loại quantization. Nhưng khi bạn áp dụng chúng vào LLM, câu chuyện rẽ nhánh.
Vấn đề bắt đầu từ outlier. Transformer có một đặc tính kỳ lạ mà CNN không có: một số ít activation channels — Tim Dettmers gọi chúng là "emergent features" — có giá trị lớn gấp 100 lần so với phần còn lại, và chúng xuất hiện đột ngột khi model đủ lớn (>6.7B params). Nếu bạn quantize chúng cùng scale với các channel bình thường, model collapse. Uniform quantization "sạch" gần như không bao giờ đủ cho LLM — và đây là domino đầu tiên kéo theo mọi thứ khác.
Vì activation có outlier và thay đổi mỗi input, hầu hết LLM quantization method chỉ dám quantize weight — giữ activation ở FP16 hoặc BF16. Trong deep learning truyền thống bạn quantize cả hai (W8A8), nhưng với transformer thì quá rủi ro. Và vì model quá to — 70B parameter nghĩa là retrain trên hạ tầng hàng triệu đô — QAT gần như là đặc quyền của lab lớn (Meta, Google). Người chạy local LLM sống bằng PTQ, và đó là lý do toàn bộ dòng nghiên cứu GPTQ, AWQ tồn tại: chúng là những PTQ method đủ tốt để thay thế QAT.
Kết quả của chuỗi domino này: LLM quantization push aggressive hơn DL truyền thống rất nhiều. Khi DL coi INT8 là "đã đủ", LLM coi INT4 là mainstream và đang đua xuống 3-bit (GGUF Q3_K), 2-bit (QuIP, AQLM), thậm chí 1.58-bit (BitNet b1.58 của Microsoft). Mỗi bit tiết kiệm trên model 70B = gần 9 GB VRAM — sự khác biệt giữa chạy được và không chạy được trên một cái 4090.
Bài tiếp theo mình sẽ kể chi tiết về GPTQ, AWQ, và cuộc đua xuống 2-bit — nơi mà quantization cho LLM trở thành một branch riêng với những trick mà deep learning truyền thống không cần và không có. Từ Hessian-based error redistribution đến activation-aware scaling đến lattice codebook trên E8 — mỗi cái là một câu chuyện riêng, và mỗi cái xứng đáng được kể kỹ.
Từ điển nào cho thời đại nào
Mình bắt đầu bài này bằng lời thú nhận rằng mình dùng quantization mà không hiểu nó. Sau một tuần đào, cái mình mang về không phải chỉ là kiến thức — mà là một cách nhìn khác.
Quantization không phải là "làm model nhỏ đi". Nó là bài toán dịch thuật cổ nhất trong lý thuyết thông tin — dịch từ ngôn ngữ liên tục sang ngôn ngữ rời rạc. Và mỗi bước tiến trong 70 năm qua là xây một từ điển tốt hơn:
- Lloyd-Max (1957) xây từ điển cho phân phối đã biết — Gaussian, Laplace, bất kỳ $f(x)$ nào bạn đưa cho nó.
- GPTQ (2023) xây từ điển bằng cách hỏi Hessian: "weight nào quan trọng, weight nào có thể nhận thêm lỗi?"
- AWQ (2023) xây từ điển bằng cách nhìn activation: "channel nào đang hoạt động mạnh nhất?"
- TurboQuant (2025) không xây từ điển mới — nó xoay ngôn ngữ (random rotation) để khớp với từ điển Lloyd-Max có sẵn. Một meta-move mà mình thấy là elegant nhất trong cả dòng.
Mỗi cái giải cùng bài toán Lloyd đặt ra 70 năm trước. Chỉ là "data" ngày càng phức tạp hơn — từ tín hiệu 1D đến weight matrix hàng tỷ tham số — và "từ điển" ngày càng tinh vi hơn để theo kịp.
Nếu bạn đã đọc bài TurboQuant trước bài này, quay lại đọc lần nữa. Mình cá là phần Lloyd-Max, phần random rotation, phần QJL — tất cả sẽ click khác đi khi bạn đã hiểu nền tảng. Và nếu bạn đọc bài này trước — đọc TurboQuant tiếp theo, vì đó là một trong những ứng dụng đẹp nhất của toàn bộ lý thuyết này.
Lần tới khi bạn chọn giữa Q4_K_M và Q5_K_S, ít nhất bạn sẽ biết mình đang chọn gì — không phải "4 bit hay 5 bit", mà là "từ điển dịch nào phù hợp hơn với cái giá mình sẵn sàng trả".
Bình
Tham khảo: Lloyd, S. "Least squares quantization in PCM" (1957/1982). Frantar & Alistarh, "GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers" (ICLR 2023). Lin et al., "AWQ: Activation-aware Weight Quantization" (MLSys 2024). Dettmers et al., "LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale" (NeurIPS 2022). Chee et al., "QuIP: 2-Bit Quantization of Large Language Models With Guarantees" (NeurIPS 2023). Companion piece: TurboQuant: nén KV cache 6 lần, hay một paper cũ 9 tháng được PR lại?