TurboQuant của Google: nén KV cache 6 lần, hay một paper cũ 9 tháng được PR lại?
Google vừa nói họ nén được KV cache xuống 3 bit mà không mất accuracy. Mình ngồi đọc paper, và câu chuyện thú vị hơn cái tiêu đề rất nhiều.
Tuần trước mình đang ngồi debug một con Qwen 32B chạy trên cái 4090 duy nhất trong lab, context dài 64K, thì OOM. Lại OOM. Lần thứ tư trong buổi chiều. Mình biết thủ phạm rồi - KV cache. Cái đống ma trận key-value mà model phải giữ trong VRAM để không phải tính lại attention từ đầu mỗi token. Với context dài, nó phình ra nhanh hơn cả weights.
Đúng lúc đó, trên r/LocalLLaMA có một post viral: "[google research] TurboQuant: Redefining AI efficiency with extreme compression". Tiêu đề hơi giật gân theo kiểu Google muốn chúng ta tin. 361 upvotes. Comments của Awni Hannun (cha đẻ MLX) nói đã implement xong, cache nhỏ hơn 4.9 lần ở 2.5-bit, zero accuracy loss.
Mình đóng laptop, đi pha cà phê, rồi ngồi đọc paper. Và những gì mình tìm thấy không phải là một breakthrough. Nó là một thứ thú vị hơn nhiều: một paper 9 tháng tuổi, viết rất đẹp về mặt toán học, được Google team marketing lôi ra đúng lúc thị trường VRAM đang điên loạn. Và đằng sau cái hype đó là một ý tưởng toán học thật sự đẹp - đẹp đến mức nếu bạn không hiểu nó, bạn sẽ bỏ lỡ một trong những trick hay nhất của high-dimensional geometry mà mình đọc được năm nay.
Bài này mình muốn kể bạn nghe cả hai phần: phần toán đẹp, và phần mà Google không nói trong blog post.
KV cache - cái bàn làm việc mà transformer không bao giờ dọn
Trước khi nói TurboQuant làm gì, mình cần bạn hiểu rõ nó đang cố compress cái gì. Vì 90% các bài blog mình đọc về chủ đề này bắt đầu ngay với "KV cache chiếm nhiều VRAM" mà không giải thích vì sao cái đống đó tồn tại ngay từ đầu.
Khi một transformer generate từng token, nó cần chạy attention. Attention nói ngắn gọn là: với mỗi token mới, hỏi "mình nên chú ý tới những token nào trong quá khứ?" - và để trả lời câu đó, mỗi token trong quá khứ đã phải được project thành hai vector: một cái gọi là key (nhãn của token đó), và một cái gọi là value (nội dung của token đó). Token mới tạo ra query của riêng nó, rồi tính inner product $\text{query} \cdot \text{key}$ với tất cả key trong quá khứ để biết token nào liên quan. Kết quả là một trọng số, nhân với value, rồi cộng lại.
Vấn đề: nếu mỗi lần generate một token mới mà phải tính lại key và value của toàn bộ quá khứ từ đầu, bạn sẽ chờ dài cổ. Vì thế transformer cache tất cả key và value đã tính ra. Đó là KV cache. Cái bàn làm việc đầy giấy tờ của model. Model không bao giờ dọn nó - mỗi token mới lại thêm một cặp K, V vào đống cũ.
Với một model 7B, head_dim = 128, 32 layers, 32 heads, mỗi token generate ra khoảng 1 MB KV data ở FP16. Context 100K tokens? Đó là 100 GB. Nhảy múa với 64 GB VRAM của bạn. Đây là lý do vì sao chạy long context ở local luôn khó hơn bạn nghĩ - không phải vì weights quá to, mà vì cái bàn làm việc của model không bao giờ hết phình ra.

Và điểm quan trọng nhất - cái mà TurboQuant exploit được: những con số trong KV cache không cần phải chính xác tuyệt đối. Cái transformer cần là tính được $\text{query} \cdot \text{key}$ đủ gần để pick đúng token quan trọng. Nếu bạn có thể nén key thành 3 bit mỗi số thay vì 16 bit, mà inner product tính ra vẫn gần giống như inner product gốc, bạn đã thắng.
Đó là bài toán. Bây giờ nói đến cách TurboQuant giải nó.
Trick đầu tiên: xoay ngẫu nhiên trước khi nén
Quantization bình thường (INT4, INT8 các kiểu) hoạt động theo kiểu đơn giản nhất có thể: lấy từng giá trị float, tìm min-max của chunk, chia đều khoảng đó thành 16 (với 4-bit) hoặc 256 (với 8-bit) bucket, rồi map mỗi float về bucket gần nhất. Xong.
Cái vấn đề của cách này là nó không care về phân phối của data. Nếu vector của bạn có outlier - một vài giá trị cực lớn hoặc cực nhỏ - bucket sẽ bị kéo căng ra để chứa chúng, và các giá trị "bình thường" sẽ cùng dồn vào vài bucket giữa. Mất resolution ở chỗ quan trọng nhất.
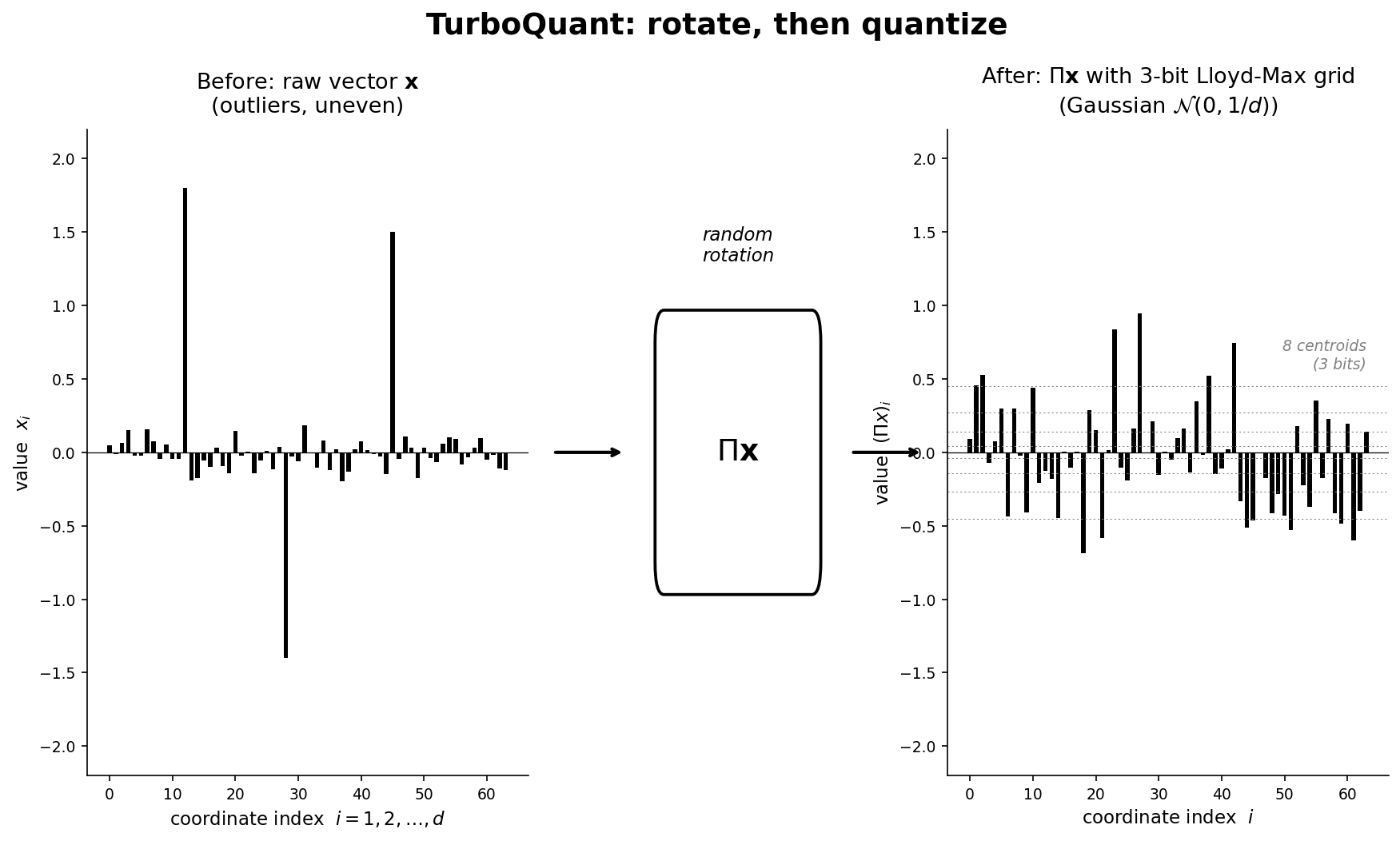
TurboQuant tiếp cận theo một hướng lạ: trước khi quantize, xoay vector đi đã. Cụ thể:
Nhân vector đầu vào x với một ma trận xoay ngẫu nhiên $\Pi$ (rotation matrix được lấy từ QR decomposition của một ma trận entries Normal i.i.d.). Kết quả $\Pi x$ là vector mới, cùng độ dài, nhưng xoay theo một hướng ngẫu nhiên trong không gian d chiều.Nghe có vẻ ngu. Bạn thêm một bước tính toán, vector thì vẫn cùng size, thông tin không mất đi (xoay là invertible). Tại sao lại làm vậy?
Vì một tính chất rất đẹp của high-dimensional geometry: khi bạn xoay ngẫu nhiên một vector trong không gian rất nhiều chiều, từng coordinate của vector xoay đó sẽ có phân phối gần như Gaussian với variance rất nhỏ. Không có outlier nữa. Không có spike. Mọi coordinate đều ngoan ngoãn, tập trung quanh 0, với độ lệch chuẩn chừng $\frac{1}{\sqrt{d}}$.
Paper viết chính xác như thế này: với một vector đơn vị trên mặt cầu đơn vị d chiều, mỗi coordinate có phân phối:
$$f(x) = C \cdot (1 - x^2)^{\frac{d-3}{2}}$$
Đây là một Beta distribution. Khi d tăng lên, nó converge về một Gaussian $\mathcal{N}(0, 1/d)$.

Đây là concentration of measure - hiện tượng mà trong không gian nhiều chiều, gần như mọi thứ đều nằm cạnh một thứ gì đó dự đoán được.
Dịch sang ngôn ngữ người: trong 128 chiều hoặc cao hơn, nếu bạn xoay ngẫu nhiên, bạn gần như chắc chắn sẽ nhận được một vector mà mọi coordinate đều "behaved" - không có giá trị nào lòi ra quá xa. Và khi mọi coordinate đều có cùng một phân phối đã biết trước (Gaussian), bạn có thể pre-compute một bộ quantization codebook tối ưu cho phân phối đó và xài lại cho mọi vector, mọi model, mọi dataset. Data-oblivious hoàn toàn. Không cần calibration set. Không cần fitting.
Đây là phần mình thấy đẹp nhất. Bạn không tối ưu quantization cho data của bạn. Bạn tối ưu cho một phân phối toán học mà random rotation đảm bảo data của bạn sẽ có. Bạn trade một chút compute (cái rotation) để lấy một thứ quý hơn rất nhiều: sự dễ đoán.
Lloyd-Max quantizer: chia bucket đúng chỗ
Khi đã biết coordinate sau xoay có phân phối Gaussian $\mathcal{N}(0, 1/d)$, câu hỏi tiếp theo là: nên chia không gian thành mấy bucket và đặt mỗi bucket ở đâu để sai số bình phương nhỏ nhất?
Đây là bài toán Lloyd-Max - về bản chất là k-means một chiều trên một phân phối liên tục. Bạn minimize:
$$C(f, b) = \min_{{c_1, \dots, c_{2^b}}} \sum_{i} \int |x - c_i|^2 \cdot f(x) \, dx$$
Dịch: với 2^b centroids (bucket), tìm vị trí của chúng sao cho tổng bình phương khoảng cách giữa x và centroid gần nhất, trung bình hóa qua toàn bộ phân phối f(x), là nhỏ nhất.

Với phân phối Gaussian, bài này đã được giải numerical từ những năm 60. Centroid không cách đều - chúng dày hơn ở gần 0 (nơi có nhiều xác suất nhất) và thưa dần ra đuôi. Vì TurboQuant biết trước phân phối là gì, họ pre-compute bảng centroid này một lần và ship kèm code. Không runtime fitting. Không calibration. Mỗi coordinate sau khi xoay, bạn chỉ việc lookup xem nó gần centroid nào nhất, lưu cái index vào - đó là giá trị quantized của bạn.
Đến đây nếu bạn vẫn theo mình, bạn có thể tự hỏi: ok, MSE giữa vector gốc và vector quantized nhỏ, tốt. Nhưng transformer không dùng vector gốc trực tiếp - nó dùng inner product $\text{query} \cdot \text{key}$. Low MSE có đảm bảo inner product không bị lệch không?
Câu trả lời là: không. Và đây là chỗ TurboQuant làm một trick thứ hai.
Vấn đề của inner product: bias không phải MSE
Có một kết quả khó chịu trong quantization theory: MSE-optimal quantizer luôn underestimate inner product. Lý do trực giác là thế này - khi bạn quantize một vector, bạn kéo nó về gần các centroid nhất. Centroid nằm ở vị trí "trung bình" của data, nên về mặt norm, vector quantized sẽ luôn ngắn hơn vector gốc một chút. Khi bạn tính $\text{query} \cdot \tilde{\text{key}}$, cái tích số sẽ nhỏ hơn $\text{query} \cdot \text{key}$ một cách có hệ thống. Đó là bias.

Với attention, bias là cực kỳ tệ.
Và đây không phải là lý thuyết mà mình bịa ra - paper có một hình cực kỳ minh họa cho điều này. Figure 1 của paper plot histogram của inner product distortion (sai số giữa $\langle q, \tilde{k} \rangle$ và $\langle q, k \rangle$ thật) ở 4 bit-width khác nhau, cho cả hai phiên bản: TurboQuantprod (với correction) và TurboQuantmse (chỉ MSE, không correction).

Hãy nhìn kỹ hai hàng. Hàng trên là TurboQuantprod: tất cả histogram đều centered tại 0, đối xứng, trông như Gaussian quanh trung bình bằng không. Đó là đặc trưng của một estimator unbiased - sai số dương và sai số âm triệt tiêu nhau trung bình.
Hàng dưới là TurboQuantmse. Ở bit-width = 1, histogram bị lệch hẳn sang phía dương - tất cả sai số đều cùng dấu, cùng hướng. Đó chính là bias mình vừa nói: inner product bị underestimate một cách có hệ thống. Khi bit-width tăng lên 2, 3, 4, bias co lại dần - nhưng ở bit thấp (2-bit, là chỗ TurboQuant sống), bias là thảm họa nếu không có correction.
Paper còn có một hình thứ hai thú vị hơn: bias của MSE tăng theo độ lớn của inner product trung bình. Nghĩa là key nào càng liên quan đến query (inner product càng lớn), key đó càng bị downweight nhiều.

Nhìn hàng trên (prod): qua 4 cột với average inner product tăng dần từ 0.01 đến 0.17, histogram vẫn đứng yên, vẫn centered tại 0, variance không đổi. Hàng dưới (mse): cùng 4 cột đó, histogram dịch dần sang phải - bias tăng theo đúng cái quantity mà attention cần preserve nhất. Đây là lý do tại sao QJL correction không phải optional. Nếu bỏ nó đi, model sẽ "quên" đúng những token quan trọng nhất. Vì attention dùng softmax - nó normalize các logit. Nếu mọi logit đều bị kéo xuống một cách đều nhau, softmax không care. Nhưng nếu bias phụ thuộc vào norm của key (mà nó phụ thuộc), thì token có norm lớn sẽ bị downweight nhiều hơn token có norm nhỏ. Đột nhiên model của bạn "quên" những token quan trọng.
Cách fix của TurboQuant là phần thứ hai: QJL - Quantized Johnson-Lindenstrauss.
Johnson-Lindenstrauss là một định lý kinh điển từ 1984 nói rằng: bạn có thể project data từ nhiều chiều xuống ít chiều hơn bằng một random projection, và inner product vẫn được giữ gần đúng (với xác suất cao). QJL là biến thể quantized của nó: thay vì giữ giá trị sau projection, chỉ giữ dấu của chúng (+1 hoặc -1). Đúng 1 bit mỗi coordinate.
Điểm mạnh của QJL là nó cho estimator unbiased cho inner product. Cụ thể, nếu bạn dùng QJL để nén x thành x_qjl, thì:
$$\mathbb{E}[\langle y, \tilde{x}_{qjl} \rangle] = \langle y, x \rangle$$
Không lệch một hướng nào. Variance thì có (bounded bởi $\frac{\pi}{2d} \cdot |y|^2$), nhưng bias = 0. Đây là điểm khác biệt quan trọng: MSE quantizer precise hơn về giá trị từng điểm, nhưng lệch về tổng thể; QJL noisy hơn nhưng về trung bình thì đúng.
TurboQuant kết hợp hai cái lại theo công thức:
Dùng (b-1) bit cho MSE quantizer với Lloyd-Max + random rotation. Lấy residual (phần mà quantizer không capture được). Dùng 1 bit QJL trên residual đó.
Ý tưởng: để MSE quantizer lo phần chính - phần có energy lớn - thật chính xác. Rồi dùng 1 bit QJL để "sửa lệch" cho phần còn lại. Vì QJL là unbiased, cái correction term nó thêm vào sẽ trung bình hóa đi cái bias của quantizer chính. Kết quả cuối cùng: estimator của inner product trở nên unbiased, với variance nhỏ hơn nhiều so với chỉ dùng QJL một mình.

Đây là insight toán học quan trọng nhất của paper. Và đây cũng là lý do tại sao họ đặt tên "Turbo" - cái 1 bit correction như một turbocharger nhỏ bolt vào một engine MSE truyền thống.
Cái định lý đẹp: 2.7 lần distance đến giới hạn vũ trụ
Paper có một định lý mà mình muốn highlight vì nó rất hay. Họ chứng minh được rằng với b bit, distortion (MSE) của TurboQuant bị bounded bởi:
$$\text{MSE} \leq \frac{\sqrt{3} \cdot \pi}{2} \cdot \frac{1}{4^b}$$
Còn information-theoretic lower bound - giới hạn không có thuật toán nào đạt được - là bằng cỡ $1/4^b$. Tỉ số giữa hai cái này là khoảng $\frac{3\pi}{2} \approx 2.7$. Dịch sang ngôn ngữ người: TurboQuant chỉ cách giới hạn lý thuyết tuyệt đối một hằng số nhỏ (cỡ 2.7 lần), không phụ thuộc bit-width hay dimension.
Cái này không phải nhỏ. Nó có nghĩa là bạn không thể làm tốt hơn TurboQuant một cách đáng kể bằng cách nhồi nhét thêm bit hay thêm trick. Với bit-width b=1, tỉ số này còn nhỏ hơn nữa, khoảng 1.45. Về mặt toán học, đây là một kết quả near-optimal thực sự - không phải theo nghĩa "tốt hơn baseline", mà theo nghĩa "gần với giới hạn vũ trụ".

Và paper có hình xác nhận điều này bằng thực nghiệm. Figure 3 plot log-log graph của inner-product error và MSE qua các bit-width, so với lower bound lý thuyết (đường xanh dashed) và upper bound mà paper chứng minh (đường đỏ dashed):

Đọc hình này theo mình: cả TurboQuantprod và TurboQuantmse đều nằm kẹp giữa lower bound và upper bound ở mọi bit-width. Hai đường dashed song song trong log-log space - chúng có cùng slope, chỉ lệch nhau bởi một constant factor. Đó chính là factor 2.7 mà định lý nói. Nghĩa là khi bạn thêm 1 bit, cả lower bound và TurboQuant đều tụt xuống 4 lần như nhau - TurboQuant "bám sát" optimal ở mọi precision.
Điểm đáng chú ý: ở subplot (a) inner-prod error, TurboQuantprod (đường đỏ solid) gần như trùng với lower bound (xanh dashed) ở bit cao. Đường TurboQuantmse thì nằm cao hơn nhiều ở bit thấp và chỉ bắt kịp khi bit đủ lớn. Đây là bằng chứng thực nghiệm cho cả hai claim: (1) việc thêm QJL correction giúp prod gần optimal hơn, và (2) constant 2.7 không phải là loose bound - nó là tight.
Đây là lý do vì sao mình tin paper này sẽ trụ lâu trong literature kể cả khi cái hype hiện tại qua đi. Kết quả kiểu này hiếm.
Thực nghiệm: 3.5 bit và cú "tie" với full precision
Phần experiments là phần dễ viral nhất, nên mình kể nhanh:
- LongBench, trung bình trên các model Gemma/Mistral/Llama-3.1-8B-Instruct: TurboQuant 3.5-bit đạt 50.06. Full precision 16-bit baseline: 50.06. Đúng chính xác. Cùng con số.
- LongBench tại 2.5-bit (aggressive hơn): 49.44. Mất 0.62 điểm. Gọi là "marginal degradation".
- Needle-in-a-Haystack ở context lên tới 104K tokens với 4x compression: 0.997, functionally giống hệt full precision.
- Tốc độ attention logit trên H100: 4-bit TurboQuant claim 8x nhanh hơn 32-bit unquantized keys.
Cái needle-in-a-haystack test đáng xem chi tiết. Đây là benchmark mà bạn nhét một câu random ("the needle") vào một đống text dài ("the haystack") rồi hỏi model câu đó ở đâu. Nó test trực tiếp khả năng long-context retrieval - chính xác cái thứ mà compression KV cache dễ làm hỏng nhất. Figure 4 của paper so sánh 6 approach khác nhau:

Mỗi heatmap là một method. Trục x là context length (4k → 104k tokens), trục y là depth percent (needle ở đầu, giữa, cuối document). Màu xanh = recall cao, đỏ = recall thấp. Score ở trên mỗi heatmap là trung bình.
Nhìn hàng trên - SnapKV (0.858) và PyramidKV (0.895) - bạn thấy rõ các ô đỏ/cam ở depth 33-67%, đặc biệt ở context dài. Đó là "middle-loss" cổ điển: token-level eviction methods quyết định drop token nào dựa vào heuristic, và chúng drop nhầm. KIVI (0.981) khá hơn - scalar quantization giữ được thông tin nhiều hơn là drop token - nhưng vẫn có vài điểm miss.
Hàng dưới là chỗ thú vị. PolarQuant (0.995) gần perfect. Full-Precision baseline là 0.997. Và TurboQuant (0.997) - cùng score với full precision, ở compression ratio 4×. Không phải "gần như" full precision. Là bằng. Heatmap xanh hoàn toàn, không có một ô nào lệch.
Đây là cái hình mà Google marketing chắc chắn đã screenshot và đóng khung. Và về mặt compression-accuracy trade-off thì nó xứng đáng. Cái asterisk quan trọng mình sẽ nói sau - nó là về tốc độ, không phải về accuracy. Accuracy thì paper không nói điêu.
Một chi tiết nữa mà mình đã hiểu sai lúc đầu và cần correct lại: con số "3.5-bit" và "2.5-bit" không phải pure bit-width. TurboQuant không có codebook 2.5-bit (vì không có 2^2.5 centroid). Thực tế nó là một chiến lược channel splitting: paper tách 128 channel của head_dim thành hai nhóm - "outlier channels" được quantize ở precision cao hơn, "regular channels" precision thấp hơn. Cụ thể cho 2.5-bit: 32 channel outlier ở 3-bit + 96 channel regular ở 2-bit = (32×3 + 96×2)/128 = 2.5 bit/channel trung bình. Đây là trick đã được dùng trong các paper quantization trước (ZeroQuant, SmoothQuant), không phải novelty của TurboQuant - nhưng nó là lý do giá trị trung bình là số lẻ. Compression thực tế của quantized vector ít nhất 4.5×.

Nhìn những con số này xong, phản ứng đầu tiên của ai cũng sẽ là: "wow, 6x ít memory, 8x speed, không mất accuracy, sao phải dùng FP16 nữa?". Đó chính là phản ứng mà blog post của Google muốn bạn có.
Và đây là lúc mình phải làm cái việc không vui lắm: kéo bạn xuống mặt đất.
Steel-man: ReturningTarzan của ExLlama đã đúng ở đâu
Trong comments của post r/LocalLLaMA, có một người tên ReturningTarzan - dev của ExLlama, một trong những inference engine được care nhiều nhất trong local LLM community. Comment của ông đáng đọc toàn bộ, nhưng mình tóm gọn cái argument:
Cái "8x speedup" không có trong paper. Paper chỉ nói về compression ratio và accuracy. Con số 8x chỉ xuất hiện trong blog post của Google, với một comparison rất kỳ lạ: so với 32-bit unquantized keys trên FP32, tính attention ở format mà không ai chạy production dùng. Production dùng FP16 hoặc BF16. So với cái baseline đúng, speedup thực tế gần như biến mất.
Overhead runtime là có thật, và nó lớn. Lý do là hai lý do kỹ thuật:
- Random rotation không free. Mỗi lần bạn quantize một vector mới (mà KV cache là online - bạn thêm vector mới mỗi token), bạn phải multiply với ma trận rotation $d \times d$. Với $d = 128$ (head dim), đó là một matmul $128 \times 128$ cho mỗi token, mỗi head, mỗi layer. Với 32 layers, 32 heads, một token = 1024 matmul. Không nhiều ở scale H100, nhưng không "zero overhead" như blog claim.
- Codebook lookup không vectorize tốt. Quantization kiểu INT4 truyền thống rất đơn giản: convert float thành int, truncate bit. Vài instruction, SIMD ngon lành. Codebook quantization của Lloyd-Max thì khác hoàn toàn - với mỗi giá trị, bạn phải tìm centroid gần nhất trong bảng $2^b$ giá trị. Đó là table lookup, comparison, branch. Trên modern GPU, cái loop này chạy vật vã hơn INT4 truyền thống rất nhiều.
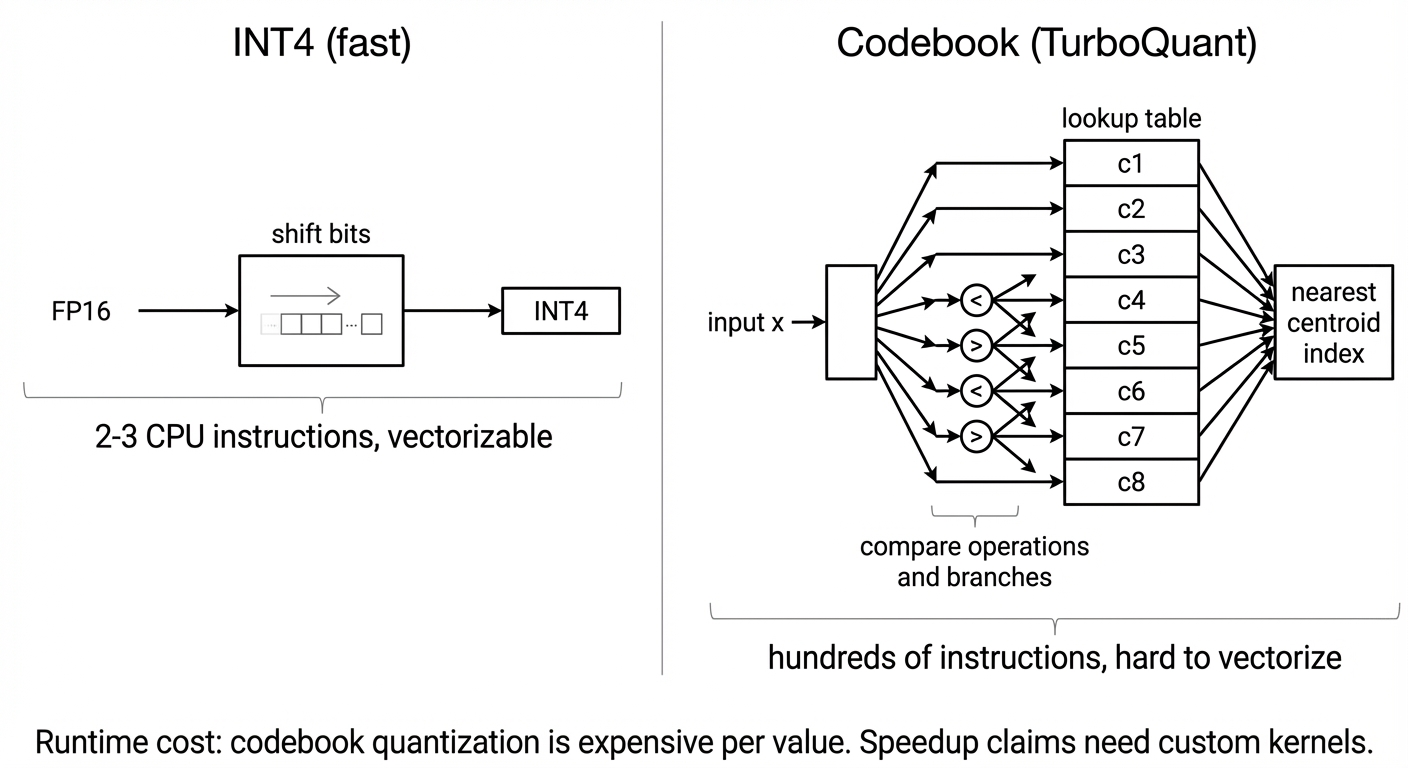
Cộng hai cái lại, ReturningTarzan chỉ ra một benchmark mà naive implementation của TurboQuant chạy 13-35 lần chậm hơn baseline ở end-to-end. Optimized implementation (với Triton kernel custom, có fuse với attention) hiện tại đã kéo performance gần par với 8-bit quantization, nhưng chưa ai demonstrate được cái 8x speedup của blog post.
Nói cách khác: cái number 8x mà Google quảng cáo là so sánh một apples với một orange được thả trong máy blender. Trong môi trường production thực tế, TurboQuant hiện tại là một technique compression tốt về memory, nhưng speedup vẫn là dấu hỏi lớn.
Mình không nói Google dối. Paper toán học của họ thật sự đẹp. Mình nói là blog post của họ đã marketing nó theo một cách mà nếu bạn không đọc kỹ, bạn sẽ hiểu nhầm.
Tại sao là bây giờ?
Có một chi tiết mà không ai nhắc đến trong hype wave đầu tiên: paper này submit lên arXiv ngày 28 tháng 4 năm 2025. Đã được accept ở ICLR 2026. Nghĩa là khi blog post của Google Research publish gần đây với tone "introducing a breakthrough", paper đã tồn tại gần một năm rồi. Một năm là eternity trong AI research.
Câu hỏi đúng không phải "TurboQuant làm được gì?". Câu hỏi đúng là: tại sao Google chọn marketing nó vào tháng 4 năm 2026, không phải tháng 5 năm 2025 khi paper ra?
Nhìn quanh thị trường bây giờ. Giá DRAM và HBM đang ở peak lịch sử - tin tức về việc các hyperscaler mua sạch memory đã lên báo cả năm qua. Nvidia đang thao túng toàn bộ conversation về LLM hardware. Memory stocks (Micron, SK Hynix, Samsung) tăng vọt. Mọi người đang lo không có đủ VRAM để chạy long-context workload.
Một comment trên HN mà mình đọc, viết rất sắc: "Google đang cố đẩy giá memory xuống để chính họ mua được nhiều hơn." Mình không nói đây là motivation duy nhất, nhưng nó là một góc nhìn đáng cân nhắc. Khi một big tech release một compression technique 9 tháng cũ với tone "world-changing breakthrough" đúng vào lúc giá HBM peak, signal khá rõ: họ muốn narrative chuyển sang "memory is fine, just compress better" để áp lực lên memory supplier giảm đi.
Và có một khả năng khác, cynical hơn nhưng có căn cứ: Google và các hyperscaler khác đã dùng một version của technique này trong production từ lâu rồi. Việc release giờ không phải là giving away competitive edge - nó là commoditize hóa cái mà competitor của họ (OpenAI, Anthropic) có thể chưa có, trong khi Google đã move on sang generation tiếp theo. Trong 9 tháng, Google Research publish một technique nội bộ thường là dấu hiệu họ đã có technique tốt hơn đang chạy trong data center. Cách này, họ vừa chiếm credit trong academic literature, vừa đẩy các đối thủ phải bận rộn re-implementation thay vì research tiếp.
Mình không biết cái nào đúng. Có thể là cả hai. Có thể không có cái nào. Nhưng một rule mình tự đặt ra khi đọc big tech research blog: khi tone của blog post lệch nhiều so với tone của paper, hãy đọc kỹ paper và skip blog post. TurboQuant là case điển hình - paper viết khiêm tốn, có theorem, có confidence interval, có discussion về limitation. Blog post thì nói "6x compression, 8x speedup, redefining efficiency". Hai text kể hai câu chuyện khác nhau.
Gemma 4 và một hiểu lầm đáng nói
Ngay sau khi TurboQuant viral, Google release Gemma 4 — và mình thấy một narrative bắt đầu hình thành trong community: "À, TurboQuant chắc là lý do Gemma 4 nhẹ mà vẫn mạnh." Mình cũng tự hỏi câu đó, nên đã ngồi đào kỹ. Và câu trả lời ngắn gọn là: không phải.
TurboQuant có thể apply lên Gemma 4 — và kết quả rất ấn tượng. Prince Canuma đã chạy Gemma 4 31B với TurboQuant KV cache trên MLX ở 128K context: KV memory giảm từ 13.3 GB xuống 4.9 GB, giảm 63%, quality preserved. Có cả một fork llama.cpp riêng cho Gemma 4 + TurboQuant đạt 120 t/s với 3.8x compression trên RTX 3090. Nhưng đây là optimization áp dụng lúc inference, không phải thứ nằm sẵn trong kiến trúc model.
Lý do thật sự Gemma 4 nhẹ mà vẫn mạnh nằm ở ba thiết kế kiến trúc khác hẳn:
Mixture of Experts (MoE): Model 26B tổng params nhưng chỉ activate khoảng 4B params mỗi token — 128 experts, chỉ route qua 2. Nên nó chạy nhanh như model 4-8B nhưng chất lượng gần 30B. Đây là lý do chính Gemma 4 "nhẹ" — bạn trả compute cho 4B, nhưng được capacity của 26B.
Shared KV Cache: Các layer cuối không tính K/V riêng mà reuse từ layer trước cùng loại attention. Cái này giảm cả compute lẫn memory mà gần như không mất quality — và nó là thiết kế architecture, không phải compression trick post-hoc.
Per-Layer Embeddings (PLE): Thêm một pathway conditioning song song nhỏ bên cạnh residual stream chính, kết hợp token-identity và context-aware components. Giúp model biểu diễn hiệu quả hơn mà không phình size.
Điều thú vị là khi bạn kết hợp shared KV cache (đã giảm KV sẵn ở architecture level) với TurboQuant (nén phần KV còn lại lúc inference), hiệu quả kép — hai layer optimization stack lên nhau. Gemma 4 31B chạy 128K context trên một cái Mac Studio mà không OOM, cái mà vài tháng trước là không tưởng cho một model dense 31B. Nhưng credit thuộc về cả hai thứ riêng biệt, không phải một.
Chi tiết thì sẽ được kể trong một bài khác nhé
Mình nói chuyện này vì nó là ví dụ điển hình của việc correlation bị nhầm thành causation trong tech discourse. TurboQuant ra cùng thời điểm Gemma 4, cả hai đều từ Google, cả hai đều liên quan đến efficiency → não người tự nối dây. Nhưng chúng là hai innovation độc lập mà tình cờ bổ trợ nhau rất tốt.
Vậy có nên dùng TurboQuant không?
Câu trả lời thẳng của mình sau một tuần đào sâu:
Nếu bạn đang chạy local LLM với long context và đang OOM: có. Đặc biệt nếu bạn xài MLX (Awni Hannun đã implement xong), hoặc theo dõi PR trên llama.cpp (đang có work in progress). 3.5-bit KV cache gần như free về accuracy, và memory saving 4-5x là thật. Bạn sẽ không thấy 8x speedup, nhưng bạn sẽ chạy được context dài hơn mà không hit OOM. Đây là use case killer cho hobbyist.
Nếu bạn đang viết một serving engine cho multi-user: chờ thêm. Overhead của codebook lookup và rotation chưa được giải quyết tốt trong open-source code. vLLM/SGLang/ExLlamaV3 có các KV cache quantization tốt hơn về runtime (đặc biệt ExLlamaV3 của ReturningTarzan, đã được nhiều người khen là gần bằng TurboQuant về accuracy với overhead ít hơn).
Nếu bạn trade memory stocks dựa trên tin này: cẩn thận. Big hyperscaler (Google, Meta, Microsoft) nhiều khả năng đã có technique tương đương hoặc tốt hơn trong production lâu rồi. Việc Google release giờ không thay đổi fundamentals của memory demand - nó chỉ là một noise event cho public narrative.
Về mặt học thuật: đọc paper đi. Nó thật sự đẹp. Cái insight về random rotation + Beta distribution concentration là một trong những ví dụ sạch nhất mình từng gặp về việc exploit high-dimensional geometry cho practical engineering. Định lý bound 2.7-factor là một kết quả hiếm. Dù cái hype có passes hay không, đoạn toán này sẽ còn được cite trong 10 năm nữa.
Một suy tư để ngỏ
Cái làm mình dừng lại lâu nhất khi đọc paper không phải là math, mà là một câu hỏi mình không trả lời được: trong bao nhiêu "breakthrough" khác mà mình đã đọc trong năm qua, cũng là những paper cũ được lôi ra marketing đúng thời điểm?
Mình nghĩ con số không nhỏ. AI research có một cycle kỳ lạ bây giờ: paper publish trên arXiv, nằm yên vài tháng hoặc vài năm, rồi một ngày big tech blog team lôi nó ra với một tiêu đề sharp, và bỗng nhiên cả community phát sốt. Cái timing không phải ngẫu nhiên - nó match với các chu kỳ market, các release cycle của competitor, các press conference của Nvidia. Research không còn độc lập với narrative nữa.
Bài học mình rút ra cho bản thân, sau vụ TurboQuant này: mỗi khi thấy một "breakthrough" từ big tech, hãy check ngày submit lên arXiv trước. Nếu paper đã hơn 6 tháng, câu hỏi đáng hỏi không phải "technique này có đột phá không" - mà là "tại sao bây giờ?". Câu trả lời thường nói nhiều hơn về industry dynamics so với về chính technique đó.
TurboQuant là một paper tốt. Có lẽ sẽ thành một phần standard trong inference stack của 2027. Cái compression 6x có thể sẽ thành thật với community local LLM trong vài tháng tới. Nhưng nó không phải là phép màu, và nó không "redefine" cái gì cả - nó là một ứng dụng rất elegant của high-dimensional probability theory cho một bài toán rất thực tế.
Mình vẫn OOM cái Qwen 32B ngày hôm kia. Nhưng mình đang nghĩ khác về nó rồi - không phải "cần thêm VRAM", mà là "cần ngồi hiểu kỹ hơn cái geometry của attention trước khi nhồi thêm phần cứng vào". Đôi khi câu trả lời cho một bottleneck hardware nằm trong một paper toán 9 tháng tuổi mà không ai đọc.
Nếu bạn đọc tới đây và có bất đồng - đặc biệt nếu bạn đã thử implement TurboQuant và thấy speedup thực hoặc không thực ở environment của bạn - mình muốn nghe. Cái số 8x vẫn là một puzzle mình chưa resolve được, và mình thà sai mà biết mình sai còn hơn đúng một cách mù quáng.

Bài viết được kiện toàn trong 1 buổi chiều thứ 6 nhẹ nhàng trên lab ĐH FPT ☕
Bình
Paper: TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate (arXiv:2504.19874). Google Research blog: TurboQuant: Redefining AI efficiency with extreme compression. Discussion gốc trên r/LocalLLaMA với comment thread của ReturningTarzan rất đáng đọc.