Gemma 4 Shit post Review: Google Cho Free Model
Gemma 4 nghe khá là sus với những gì google công bố: benchmark cherry-picking, tool calling broken ngày đầu, tiếng Việt yếu hơn Qwen. Google cần 11 partners launch cùng lúc - tại sao?
Google launch Gemma 4 với 11 blog posts đồng loạt từ 11 partners trong cùng một ngày. Google Blog, Google Developers Blog, Google Open Source Blog, Android Developers Blog (hai bài), Google Cloud Blog, NVIDIA Blog, NVIDIA Technical Blog, Arm Newsroom, Modular Blog, HuggingFace Blog - tất cả xuất hiện ngày 2 tháng 4 năm 2026 như thể đã rehearse từ trước.
Cùng thời điểm đó, nhìn lại cách DeepSeek launch models: một upload lên HuggingFace, một paper trên arXiv. Không partner dance. Không coordinated PR. Models tự nói cho mình.
Google cần 11 partners. DeepSeek cần 1 upload. Sự bất đối xứng đó nói lên tất cả về nơi giá trị thực sự nằm - và nơi marketing cần bù đắp.
Đừng hiểu lầm - Gemma 4 là model tốt. Thật sự tốt. Cú nhảy benchmark từ Gemma 3 là lớn nhất trong lịch sử open model. Nhưng "tốt" và "tốt nhất" là hai chuyện khác nhau, và cách Google framing câu chuyện này mới là điều đáng phân tích hơn cả architecture. Đây là Gemma 4 review thực sự - không phải press release rewrite. Bài viết này sẽ mổ xẻ những gì các bài generic không bao giờ nói: model thực sự có gì mới, benchmarks đang giấu gì, so sánh thật với competitors ra sao, và quan trọng nhất - Google đang chơi game gì khi cho không model AI.
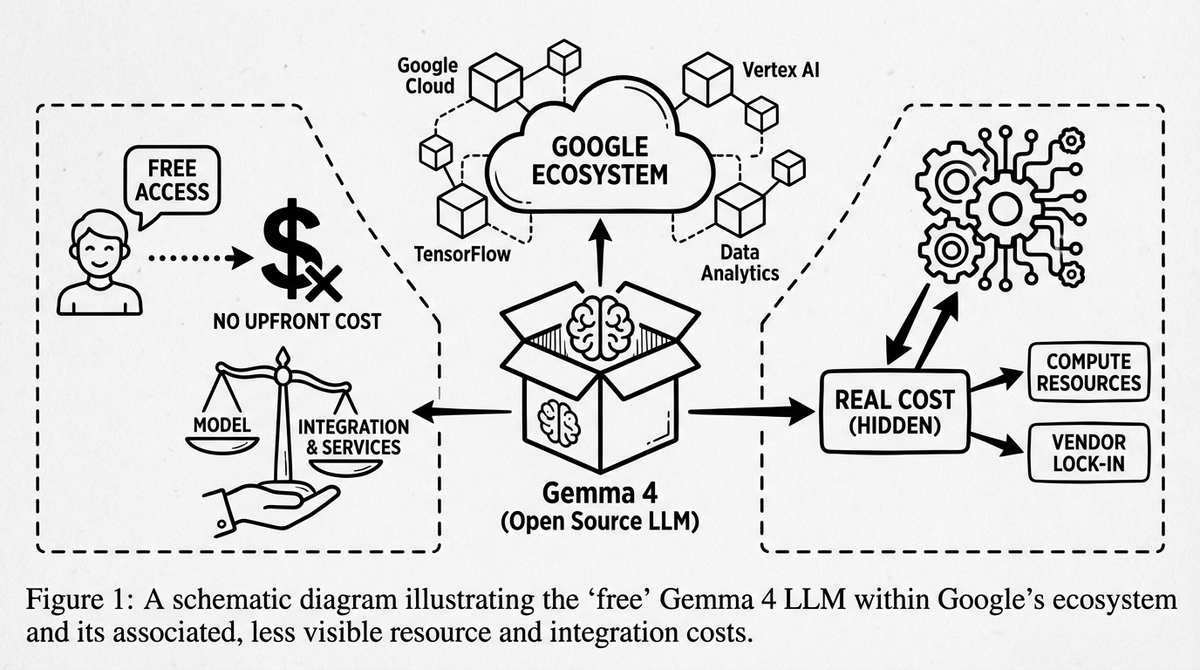
Thesis: Gemma 4 là ecosystem play tinh vi nhất của Google. Model là mồi. Ecosystem là bẫy. Và Apache 2.0 license - không phải architecture - mới là thay đổi quan trọng nhất.
Cái mà các Facebooker không nói (hoặc không hiểu): Architecture thực sự có gì?

Mở Facebook, bạn thấy "Gemma 4 ra rồi, hay lắm!" kèm screenshot benchmark. Nhưng hay ở chỗ nào? Hãy bắt đầu từ những gì thực sự thay đổi.
Gemma 4 ship 4 variants, phục vụ 4 phân khúc hoàn toàn khác nhau:
| Model | Total Params | Active Params | Context | Audio | VRAM (Q4) | Target |
|---|---|---|---|---|---|---|
| E2B | 5.1B | 2.3B | 128K | Yes | ~3 GB | Phone, IoT |
| E4B | 8B | 4.5B | 128K | Yes | ~5 GB | Laptop, edge |
| 26B-A4B (MoE) | 25.2B | 3.8B | 256K | No | ~16 GB | RTX 4090 |
| 31B Dense | 30.7B | 30.7B | 256K | No | ~20 GB | Workstation |
Variant đáng chú ý nhất là 26B-A4B - model Mixture-of-Experts đầu tiên trong family Gemma. Hãy tưởng tượng bạn thuê 128 chuyên gia, nhưng mỗi câu hỏi chỉ cần hỏi 8 người phù hợp nhất thay vì bắt cả 128 người ngồi họp. Đó là cách MoE hoạt động: 128 expert networks, top-8 routing mỗi token, cộng thêm 1 shared expert luôn active. Kết quả là chỉ 3.8B parameters thực sự "chạy" cho mỗi token, nhưng model có access đến 25.2B params kiến thức. Google claim variant này đạt 98% chất lượng của model 31B dense, với 7.5x ít compute. Nếu con số đó đúng, đây là engineering achievement thực sự đáng respect.
Về mặt architecture, Gemma 4 có 6 innovation genuinely mới so với Gemma 3. Per-Type Attention Geometry cho phép sliding window attention và full attention dùng head dimensions khác nhau (256 vs 512), thay vì uniform như trước. Proportional RoPE (p-RoPE) giúp full attention layers chỉ rotate 25% dimensions khi encode vị trí, cải thiện đáng kể long-context performance. K=V Weight Sharing loại bỏ V projection trong full attention bằng cách tái sử dụng key states, tiết kiệm memory mà không giảm chất lượng. Per-Layer Embeddings (PLE) cho mỗi decoder layer một embedding lookup riêng, giúp các layers chuyên biệt hóa. Shared KV Cache cho phép N layers cuối chia sẻ cached keys/values từ layers trước đó - E2B tận dụng điều này cho 20 trên 35 layers, giảm memory footprint drastically. Và vision encoder hoàn toàn mới dùng ViT với 2D RoPE thay thế SigLIP, hỗ trợ variable aspect ratio từ 70 đến 1,120 tokens mỗi ảnh.
Nhưng có hai red flags cần chú ý. Thứ nhất, audio chỉ có trên small models (E2B và E4B). Flagship 31B và 26B-A4B không có audio. Marketing nói "multimodal" mà không qualify rằng model mạnh nhất thiếu một modality quan trọng. Thứ hai, không có technical report trên arXiv. Google chỉ nói "built from Gemini 3 research and technology" - nhưng không publish ablations, training details, hay failure modes. Bạn không thể verify những gì không được publish. So sánh với DeepSeek, công bố paper chi tiết cho mọi model release.
Benchmark: Con số đẹp và những gì bị giấu

Cú nhảy thật - credit where credit is due
Tôi phải thừa nhận: cú nhảy từ Gemma 3 sang Gemma 4 là real và massive. Không có cách nào spin nó thành hype rỗng.
| Benchmark | Gemma 3 27B | Gemma 4 31B | Jump |
|---|---|---|---|
| AIME 2026 (math) | 20.8% | 89.2% | +329% |
| Codeforces ELO (competitive coding) | 110 | 2150 | +1854% |
| LiveCodeBench v6 (code) | 29.1% | 80.0% | +175% |
| GPQA Diamond (reasoning) | 42.4% | 84.3% | +99% |
| BigBench Extra Hard | 19.3% | 74.4% | +289% |
| 128K MRCR v2 (long context) | 13.5% | 66.4% | +392% |
Codeforces ELO nhảy từ 110 lên 2150 trong một generation - đó là từ "không biết code" lên "competitive programmer cấp quốc tế" chỉ qua một lần upgrade. Đây là cú nhảy benchmark lớn nhất trong lịch sử open model, và "thinking mode" - extended chain-of-thought reasoning lên đến 4000+ tokens - là primary driver. Không phải chỉ architecture tốt hơn; model học được cách "suy nghĩ" trước khi trả lời.
Những gì Google KHÔNG nhấn mạnh
Bây giờ đến phần mà hầu hết bài viết skip.
Arena ELO - bảng xếp hạng "thế giới thực" nơi users vote model nào trả lời tốt hơn, kể một câu chuyện khác hoàn toàn:
| Rank | Model | Arena ELO | Total Params | Origin |
|---|---|---|---|---|
| 1 | GLM-5 | ~1456 | 744B | China (Zhipu AI) |
| 2 | Kimi K2.5 | ~1453 | 1T | China (Moonshot AI) |
| 3 | Gemma 4 31B | ~1452 | 30.7B | USA (Google) |
| 4 | GLM-4.7 | ~1445 | -- | China (Zhipu AI) |
| 6 | Gemma 4 26B-A4B | ~1441 | 25.2B | USA (Google) |
(Arena ELO thay đổi theo ngày - con số trên là approximate tại thời điểm April 2, 2026)
Gemma 4 xếp thứ 3 - sát nút với top 2 Chinese models. Điều thú vị là Google frame kết quả này bằng cụm từ rất thông minh: "byte for byte, the most capable open models." Dịch ra: "tính theo mỗi byte parameter, chúng tôi tốt nhất." Điều đó có thể đúng - Gemma 4 31B đạt Arena ELO gần bằng GLM-5 (744B) với 24x ít parameters, và gần bằng Kimi K2.5 (1T) với 34x ít parameters. Đó là efficiency đáng kinh ngạc.
Nhưng "byte for byte best" không phải "best." Đó là reframing cuộc chơi từ absolute performance (nơi Chinese models thắng) sang efficiency (nơi Google thắng). Marketing cẩn thận, không phải nói dối - nhưng cũng không phải full truth. TrendingTopics EU nói thẳng: "A direct comparison with the most powerful Chinese open-source models shows that Gemma 4 cannot yet keep up." Đúng - nhưng cần qualify: "cannot keep up" theo nghĩa absolute ELO, không phải efficiency. Hai model đang cạnh tranh ở hai game khác nhau, và Google biết rõ điều đó khi chọn cách frame narrative.
Cherry-picking flags
Và đây là phần cần cảnh giác nhất khi đọc benchmarks Gemma 4:
AIME 2026 vs competitors' AIME 2024/2025. Google dùng AIME 2026 - test set mới hơn, khác hoàn toàn test set mà Qwen và DeepSeek report. So sánh con số raw giữa hai versions khác nhau của cùng benchmark là misleading. Chúng ta không biết AIME 2026 khó hơn hay dễ hơn AIME 2024.
HumanEval và SWE-bench biến mất. Hai coding benchmarks chuẩn nhất industry - HumanEval (code generation) và SWE-bench (practical software engineering) - hoàn toàn absent trong official reports. Khi một công ty skip benchmarks mà mọi competitor đều report, câu hỏi tự nhiên là: kết quả không đẹp lắm?
LiveCodeBench v6 cũng là version mới hơn competitors. Pattern: dùng version mới hơn của benchmarks khiến so sánh cross-model trở nên khó verify.
So sánh thật: Gemma 4 vs tất cả

Trong cuộc đua open source LLM 2026, đây là phần mà hầu hết bài viết về Gemma 4 skip hoặc làm sai. Không phải vì khó, mà vì nó đòi hỏi phải nói cả điều không pleasant.
Gemma 4 vs Llama 4 (Meta) - Đối thủ đã mất uy tín
| Llama 4 Maverick (400B) | Gemma 4 31B | |
|---|---|---|
| GPQA Diamond | 69.8% | 84.3% |
| Q4 VRAM | ~200 GB+ | ~20 GB |
| Context | 1M | 256K |
| License | Llama Community | Apache 2.0 |
Llama 4 có một vấn đề mà benchmark nào cũng không fix được: uy tín. Meta dính benchmark fraud scandal khi submit "experimental version" cho LMArena thay vì model công khai - version thật xếp hạng 32. Independent coding tests cho thấy Maverick chỉ đạt 70% accuracy, trong khi competitors đạt 90%.
Gemma 4 thắng Llama 4 trên reasoning (GPQA: 84.3% vs 69.8%) với 13x ít total params và 10x ít VRAM. Llama 4 chỉ thắng context window (1M vs 256K). Nhưng khi uy tín benchmark đã mất, con số context window 1M cũng đáng nghi ngờ.
Gemma 4 vs Qwen 3.5 (Alibaba) - Đối thủ thực sự
Nếu Llama 4 là đối thủ đã suy yếu, thì Qwen 3.5 là cuộc chiến thật sự:
| Qwen 3.5 27B | Qwen 3.5 397B | Gemma 4 31B | |
|---|---|---|---|
| MMLU-Pro | ~82% | -- | 85.2% |
| GPQA Diamond | 85.8% | 88.4% | 84.3% |
| Languages | 201 | 201 | 140+ (weak) |
| License | Apache 2.0 | Apache 2.0 | Apache 2.0 |
Ở tier ~30B, hai model gần như ngang nhau - Gemma dẫn MMLU-Pro, Qwen dẫn GPQA Diamond. Nhưng ở flagship tier, Qwen 3.5 với 397B params thắng rõ trên cả GPQA Diamond (88.4% vs 84.3%) và LiveCodeBench (85.3% vs 80.0%).
Về multilingual, Qwen 3.5 có lợi thế rõ: 201 ngôn ngữ với 250K vocabulary so với Gemma "140+ but weak" theo chính Google's own docs. Trên Japanese benchmarks, Qwen đạt 87.8 vs Gemma 76.2. Tuy nhiên, cần lưu ý rằng multilingual performance phụ thuộc nhiều vào task cụ thể và có thể khác nhau đáng kể giữa các ngôn ngữ.
Gemma 4 vs DeepSeek R1 - Ông vua toán
DeepSeek R1 với 97.3% trên MATH-500 vẫn là unreachable cho bất kỳ model nào khác. Nhưng Gemma 4 thắng trên GPQA Diamond (84.3% vs 71.5%) và MMLU-Pro (85.2% vs 84.0%) - với 1/22 parameter count. Practical gap còn lớn hơn: DeepSeek R1 cần ~386 GB VRAM (Q4), Gemma 4 cần ~20 GB. Nếu bạn không có cluster 8x H100, Gemma 4 là lựa chọn hiển nhiên.
Gemma 4 vs Phi-4 và Mistral - Niche players
Phi-4-Reasoning-Plus xứng danh king of small models với 82.5% AIME chỉ ở 14B params. Nhưng 16K context window là deal-breaker cho hầu hết production use cases. Gemma 4 E4B với 4.5B effective params đã tiệm cận Phi-4 trên GPQA (58.6% vs 56.1%) trong khi có 128K context - 8x hơn.
Mistral Large 3 là bất ngờ lớn nhất: 675B total params nhưng chỉ đạt 43.9% GPQA Diamond. Gemma 4 31B gần gấp đôi con số đó (84.3%) với 1/22 params. Hard reasoning rõ ràng là weakness của Mistral.
Verdict: Nên dùng model nào?
| Nếu bạn cần... | Dùng model này | Tại sao |
|---|---|---|
| Chạy local RTX 4090 | Gemma 4 26B-A4B | 3.8B active, ~150 tok/s, 82%+ GPQA |
| Chạy laptop/phone | Gemma 4 E2B/E4B | <5GB VRAM, audio, 128K context |
| Multilingual (201 languages) | Qwen 3.5 | 250K vocab, proven non-English |
| Pure toán học | DeepSeek R1 | 97.3% MATH-500 |
| Absolute best (có server) | GLM-5 / Kimi K2.5 | Arena #1-2 |
| Small + reasoning + limited context OK | Phi-4-Reasoning-Plus | 82.5% AIME ở 14B |
| Context khổng lồ (>256K) | Llama 4 Scout | 10M tokens (nếu trust Meta) |
| Commercial deployment, zero legal worry | Gemma 4 bất kỳ | Apache 2.0, period |
Agentic AI: Feature marketing mạnh nhất nhưng broken

Đây là gap lớn nhất giữa marketing và reality.
Google's entire narrative cho Gemma 4 xoay quanh "agentic AI" - model tự gọi tools, tự execute functions, tự hoàn thành workflows phức tạp. Nghe rất đẹp trên slides.
Rồi đến ngày đầu tiên community testing trên Hacker News, bức tranh khác hoàn toàn hiện ra. Nhiều users report Gemma 4 hallucinate tool execution - thay vì thực sự gọi tools, model tạo ra fake tool call responses và giả vờ đã nhận kết quả. Đây là verification bottleneck kinh điển: khi AI code trông đúng nhưng sai, và bạn không có cách verify ngoài tự chạy lại. Một test case cụ thể: khi được yêu cầu tính Unix timestamp, model generate code có vẻ đang "gọi tool" nhưng kết quả sai 1,600 giây so với đáp án đúng. Nó không sai vì tool trả sai - nó sai vì chưa bao giờ thực sự gọi tool, chỉ hallucinate toàn bộ quá trình.
Một user khác nhận xét: "doesn't respect the prompt rules" khi so sánh agentic setup giữa Gemma 4 và Qwen 3.5 - Qwen follow instructions tốt hơn rõ rệt. Trên paper, tau2-bench score 86.4% trông impressive. Nhưng tau2-bench là synthetic benchmark, không phải real-world tool calling.
Có một vấn đề sâu hơn mà ít ai bàn: khi model generate function call, hiện tại không có verifiable audit trail rằng human đã authorize action đó. Google's marketing show fully autonomous agents, nhưng production deployments cần human-in-the-loop. Architecture cho native function calling genuinely innovative - nó được built-in thay vì prompt-engineered như hầu hết competitors. Execution hiện tại thì unreliable.
Takeaway: Đừng build production agentic workflows trên Gemma 4 mà không có human oversight. Chờ 2-3 tháng community testing xác nhận reliability trước khi bet production vào feature này.
On-device: Real nhưng bạn cần biết cái giá

E2B chạy trong dưới 1.5 GB memory. Thật. 26B-A4B chạy ~150 tokens/giây trên RTX 4090 nhờ chỉ 3.8B active params. Cũng thật. Đây là engineering đáng respect và on-device story của Gemma 4 có substance thực sự - không phải chỉ marketing.
Nhưng Google cherry-pick cách present con số này một cách rất khéo. "Near-zero latency" - nghe rất catchy, cho đến khi bạn đọc fine print: trên Raspberry Pi 5, E2B decode ở 7.6 tokens/giây, nghĩa là 100 tokens mất khoảng 13 giây. Gọi là "near-zero" thì hơi aggressive.
Con số quan trọng nhất mà Google never show side-by-side: quality gap giữa on-device và full model. E2B đạt 37.5% AIME, trong khi 31B đạt 89.2%. Đó là 2.4x chênh lệch - khoảng cách giữa "đoán mò" và "giải được." Khi Google nói "run AI on your phone," họ không nói rằng AI trên phone của bạn chỉ bằng 42% chất lượng AI trên workstation.
Và tại sao không có phone benchmarks? Google show Raspberry Pi 5 (7.6 tok/s), RTX GPUs, Mac M-series - nhưng Pixel 9? Galaxy S26? Không một con số nào. Đây không phải oversight: nếu Pixel 9 đạt kết quả tốt, Google sẽ publish. Sự vắng mặt của data là data.
Devil's Advocate: Nếu muốn lock-in, sao lại Apache 2.0?

Trước khi đi đến phần "Follow the Money," hãy steel-man argument ngược lại.
Nếu Google thực sự chỉ muốn lock developers vào ecosystem, tại sao chọn Apache 2.0 - license mà bất kỳ ai cũng có thể fork, modify, deploy lên AWS hay Azure mà không cần Google Cloud? Tại sao không giữ custom license với conditions buộc dùng Google infrastructure?
Đây là counter-argument mạnh nhất, và nó có merit thực sự. Apache 2.0 genuinely tốt cho ecosystem. Bất kỳ startup nào cũng có thể build sản phẩm commercial trên Gemma 4 mà không lo legal. Đó là giá trị thật, không phải marketing.
Nhưng câu trả lời nằm ở timing và context. Google KHÔNG chọn Apache 2.0 vì altruism - họ chọn vì không còn lựa chọn khác. Qwen đã Apache 2.0. Mistral đã Apache 2.0. DeepSeek dùng MIT. Chinese models tăng từ 1.2% lên ~30% global usage trong 18 tháng, phần lớn vì license rõ ràng. Enterprise legal teams từ chối Gemma vì custom terms. Google buộc phải match hoặc thua. Và Android chứng minh rằng bạn hoàn toàn có thể cho free product với open license VÀ vẫn capture value qua ecosystem. Samsung chạy Android miễn phí - nhưng Google Search, Google Play, Google Maps vẫn là default. Cùng logic: bạn chạy Gemma miễn phí trên bất kỳ đâu - nhưng khi cần scale, Vertex AI là path of least resistance.
Follow the Money: Android Playbook 2.0

Đây là phần mà hầu hết bài viết về Gemma 4 hoàn toàn miss, và cũng là phần quan trọng nhất.
Product launch giả dạng community contribution
Hãy đếm lại: 11 blog posts đồng loạt trong 1 ngày, từ Google (5 bài), NVIDIA (2 bài), Arm, Modular, HuggingFace, Android Developers. Hardware optimizations pre-built. SDK support day-zero. Tất cả choreographed hoàn hảo.
Đây không phải organic community excitement. Đây là product launch được orchestrate ở cấp độ Fortune 500. So sánh với DeepSeek - release model bằng upload + paper, để community tự discover và adopt. Hai triết lý hoàn toàn khác nhau: một bên để product tự nói, một bên cần 11 partners nói thay.
The Funnel
Khi nhìn toàn bộ các announcement cùng lúc, pattern trở nên rõ ràng:
FREE MODEL (Apache 2.0) → Developers thử nghiệm Gemma
↓
ON-DEVICE (AICore, LiteRT) → Lock vào Android/Google ecosystem
↓
DEV TOOLS (Android Studio) → Dependency sâu hơn vào Google tooling
↓
SCALE TO CLOUD (Vertex AI) → Khi cần production scale → Google Cloud
↓
TPU INFRASTRUCTURE → $15.15 tỉ USD/quý revenue
Google Cloud revenue đang ở $15.15 tỉ/quý với 34% tăng trưởng YoY. Mỗi developer prototype trên Gemma là một potential customer cho Vertex AI khi scale lên production. Gemma downloads đã vượt 400 triệu, Gemmaverse có hơn 100,000 variants. Đó là pipeline customer acquisition không tốn một đồng advertising.
Tại sao Apache 2.0 bây giờ?
Gemma 1 và 2 dùng "Gemma Terms of Use" - license custom với restrictions riêng của Google. Gemma 3 vẫn vậy. Gemma 4 đột ngột chuyển sang Apache 2.0 - zero restrictions, zero custom clauses, full commercial freedom.
Đây không phải generosity. Đây là phản ứng trước competitive pressure. Chinese open models (Qwen, DeepSeek) đã dùng Apache 2.0 hoặc MIT từ lâu, và market share chứng minh hiệu quả: open models từ China tăng từ 1.2% lên khoảng 30% global usage trong 18 tháng. Enterprise legal teams chọn Qwen/Mistral thay vì Gemma đơn giản vì license rõ ràng hơn.
Google không có choice. Apache 2.0 là nuclear option: từ bỏ mọi control để maximize adoption. Và đây chính xác là Android playbook: năm 2007, Google cho free Android để make money trên Google Play services. Năm 2026, Google cho free Gemma để make money trên Google Cloud infrastructure. Cùng strategy, khác thập kỷ.
"Token Tax" - narrative mới, game cũ
Google và NVIDIA đang co-marketing concept "Token Tax": chi phí cloud API cho always-on AI agents sẽ trở nên unsustainable, vì vậy hãy chạy model local trên NVIDIA hardware. Nghe hợp lý. Nhưng ai hưởng lợi?
NVIDIA bán thêm GPUs. Google giữ developers trong ecosystem (prototype Gemma local → scale Vertex AI khi cần). Arm có proof point cho chip sales. Android biến Gemma thành default on-device model qua AICore. Modular và Unsloth có "day-zero support" làm marketing. Tất cả partners đều win. Developer? Developer được "free model" - và một tấm vé một chiều vào ecosystem của Google.
Muốn thử Gemma 4? Google AI Studio là cách nhanh nhất
Không cần download model, không cần GPU, không cần setup. Vào Google AI Studio, chọn Gemma 4 31B IT, và bắt đầu chat. Miễn phí.

Tôi đã thử yêu cầu Gemma 4 viết tiếng Việt trực tiếp trên AI Studio - kết quả khá mượt, văn phong tự nhiên và có chiều sâu. Đây là cách nhanh nhất để tự đánh giá model trước khi quyết định deploy local hay không.
Nếu muốn integrate Gemma 4 vào ứng dụng, Google cung cấp API qua google-genai SDK. Setup chỉ mất vài dòng:
# pip install google-genai
import os
from google import genai
from google.genai import types
def generate():
client = genai.Client(
api_key=os.environ.get("GEMINI_API_KEY"),
)
model = "gemma-4-31b-it"
contents = [
types.Content(
role="user",
parts=[
types.Part.from_text(text="""INSERT_INPUT_HERE"""),
],
),
]
generate_content_config = types.GenerateContentConfig(
thinking_config=types.ThinkingConfig(
thinking_level="HIGH",
),
)
for chunk in client.models.generate_content_stream(
model=model,
contents=contents,
config=generate_content_config,
):
print(chunk.text, end="")
if __name__ == "__main__":
generate()
Lưu ý thinking_level="HIGH" - đây là thinking mode tạo nên phần lớn cú nhảy benchmark từ Gemma 3. Model sẽ "suy nghĩ" trước khi trả lời, tốn thêm tokens nhưng chất lượng reasoning tăng đáng kể.
Gemma 4 Review: Verdict cuối cùng

Đây là model genuinely tốt với engineering đáng respect. Cú nhảy benchmark từ Gemma 3 là real, architecture innovations có substance, và MoE variant 26B-A4B là sweet spot cho local deployment trên consumer hardware. Apache 2.0 license removes mọi rào cản pháp lý cho commercial use. Nếu bạn cần chạy model mạnh trên RTX 4090, Gemma 4 26B-A4B có lẽ là lựa chọn tốt nhất hiện tại - 150 tok/s, 82%+ GPQA, fit trong 16 GB.
Nhưng "tốt nhất trên RTX 4090" không phải "tốt nhất." Chinese models vẫn dẫn đầu absolute performance. Tool calling vẫn broken. Và toàn bộ launch operation - từ 11 coordinated blogs đến NVIDIA partnership đến "Token Tax" narrative - cho thấy đây không phải community contribution vô tư. Đây là tầng đầu tiên trong funnel dẫn về Google Cloud.
Lần tới khi ai đó trên Facebook chia sẻ "Gemma 4 hay quá!" - hãy hỏi ba câu: hay hơn model nào? Trên benchmark nào? Và ai hưởng lợi từ narrative đó?
Đừng chọn model vì hype. Chọn vì data. Bảng so sánh use case ở trên - bookmark nó. Và trong 6-12 tháng tới, hãy watch hai metrics: independent benchmark replication (liệu con số Google report có hold up không), và Google Cloud revenue growth (liệu funnel có convert không). Hai con số đó sẽ cho bạn biết Gemma 4 thực sự là gift hay là bait.
Gemma 4 được release ngày 2/4/2026 - một số findings có thể thay đổi khi community testing mature hơn. Confidence level: High cho architecture specs và benchmark numbers, Medium cho tool calling issues (early reports), Medium-High cho follow-the-money analysis.