DeepSeek V4 deep dive: CSA, HCA, mHC và canh bạc 1 triệu token context
Các bài về DeepSeek v4 đang được spam ầm ầm trên các group. Các bài đó đúng 80% nhưng 20% còn lại là sai hoặc gây hiểu nhầm. Và tôi nghĩ nếu bạn thật sự muốn hiểu thì bạn nên đọc bài viết này và paper gốc.

DeepSeek V4 deep dive: CSA, HCA, mHC và canh bạc 1 triệu token context
Tối thứ sáu vừa rồi, DeepSeek drop technical report V4. 58 trang LaTeX, đầy algorithm boxes và ablation tables. Mình làm cái mọi người đều làm năm 2026: ném thẳng vào ChatGPT với prompt "tóm tắt 5 điểm khác biệt lớn nhất so với V3, kèm con số nếu có".
Output trả về:
- Hybrid attention mới gọi là CSA + HCA. Nén KV cache rất mạnh, hỗ trợ context 1 triệu token native trên cả V4-Pro (1.6T params, 49B active) và V4-Flash (284B params, 13B active).
- Manifold-Constrained Hyper-Connections (mHC) thay residual connections truyền thống, giải quyết stability cho deep stacks 60+ layers.
- Muon optimizer thay AdamW cho hầu hết module. Convergence nhanh hơn, training stable hơn.
- FP4 quantization-aware training cho MoE expert weights và Lightning Indexer.
- Post-training thay đổi căn bản: từ mixed RL của V3.2 sang Specialist Training plus On-Policy Distillation của V4.
Kèm một ghi chú: ở context 1 triệu token, V4-Pro chỉ tốn 27% FLOPs và 10% KV cache so với V3.2. V4-Flash thậm chí 10% FLOPs và 7% KV cache.
Nếu bạn ngợp với chữ KV cache thì đọc cái này trước:
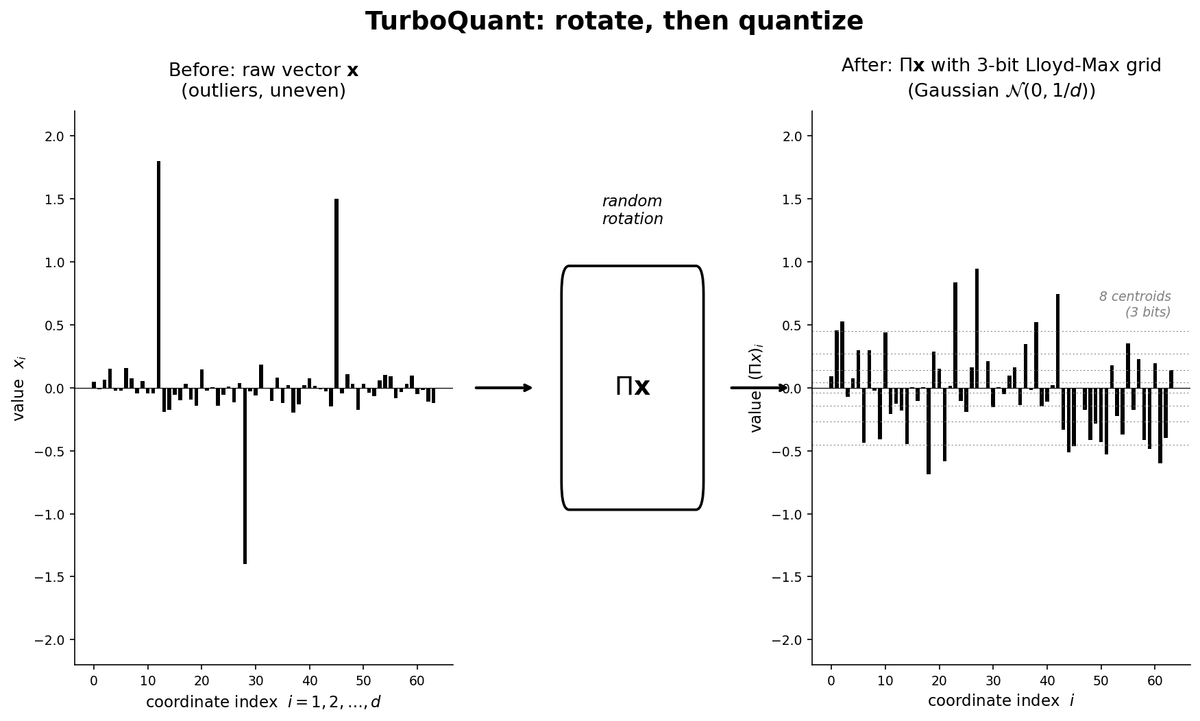

Figure 1 (page 1, DeepSeek V4 paper). Bên phải là hai curve: single-token FLOPs và accumulated KV cache theo sequence length. Đây là cú đập định nghĩa "efficiency" cho long context.
Đó là dòng khiến mình stop scroll. Bốn cái innovation kia mình từng nghe loáng thoáng. Con số efficiency này là thứ change game.
Thêm một chi tiết ChatGPT chỉ ra: trong introduction, DeepSeek tự thừa nhận V4-Pro-Max chậm hơn GPT-5.4 và Gemini-3.1-Pro khoảng "3 đến 6 tháng" trên các bài reasoning khó nhất. Đây là điều bất thường. Technical report thường khoe; đây là một report đang thừa nhận thua.

Page 5 paper, mục Reasoning. DeepSeek thẳng thừng admit "trails state-of-the-art frontier models by approximately 3 to 6 months". Hiếm khi một technical report viết câu này.
Cộng hai điều này lại, mình tin V4 không phải bản nâng cấp tiến dần của V3. Đây là một canh bạc kiến trúc lớn, đặt vào niềm tin: trong 18-24 tháng tới, "frontier model" sẽ không còn được định nghĩa bằng điểm số MMLU hay HLE, mà bằng khả năng xử lý context 1 triệu token với chi phí chấp nhận được.
Nếu cược đúng, V4 thắng một cuộc đua mà OpenAI, Anthropic, và Google chưa nhận ra mình đang chạy.
Nếu cược sai, V4 chỉ là một model "good enough" với pricing tốt, sống nhờ ăn theo Claude và GPT.
ChatGPT chỉ summarize được surface. Bài này mình sẽ cùng các bạn đi sâu vào từng cái trong list trên, mổ xẻ cơ chế thực sự, vì sao DeepSeek chọn architectural decision đó, và cuối cùng quay lại câu hỏi: cược này có đúng không? (Mình đã viết một bài riêng về kiến trúc V3 và R1 trước đây, đọc trước nếu bạn muốn nắm baseline.)
Từ V3 đến V4: cộng dồn, không reset

Bài V3 cũ của mình mổ xẻ MoE với MLA, thuật toán GRPO, và cách DeepSeek chuyển từ R1-Zero sang R1 thông qua pipeline RL có cấu trúc. V4 không vứt bỏ những gì V3 đã có. Họ giữ:
- DeepSeekMoE framework: fine-grained routed experts + shared expert
- Multi-Token Prediction (MTP) modules
- Auxiliary-loss-free load balancing strategy
- GRPO làm xương sống cho RL stage
Cái V4 thay đổi là cách bạn build các tầng đó lên thành một model có thể nuốt 1 triệu token mà không sập.
Cụ thể có bốn thay đổi lớn về kiến trúc, hai thay đổi về training, và một bước thay đổi căn bản về post-training. Mình đi qua từng cái một, vì hiểu chúng tách rời sẽ dễ hơn nhiều so với cố nhồi tất cả vào đầu cùng lúc.
Trước đó, một số con số để định khung:
| V4-Flash | V4-Pro | |
|---|---|---|
| Total params | 284B | 1.6T |
| Activated params | 13B | 49B |
| Layers | 43 | 61 |
| Hidden dimension | 4096 | 7168 |
| Routed experts (per layer) | 256 | 384 |
| Activated experts (per token) | 6 | 6 |
| Pre-training tokens | 32T | 33T |
| Native context | 1M | 1M |
Cả hai model đều support 1 triệu token context natively, không phải qua RoPE scaling sau training. Cả hai đều có ba reasoning modes: Non-Think, Think High, và Think Max.
Mở ngoặc: hiểu đúng câu "1.6T tổng, 49B active"
MoE rẻ về compute, đắt về memory. V4-Pro có 1.6T total và 49B active params: inference cost gần một dense 49B (chỉ 6 expert chạy mỗi token), nhưng vẫn cần đủ VRAM cho cả 1.6T (vì không biết trước token tiếp theo route vào expert nào). Knowledge capacity ước lượng tương đương dense ~280B.
Một câu mình thấy share đi share lại trong cộng đồng tuần này:
"DeepSeek V4 là model MoE với 1.6 nghìn tỉ tổng tham số, nhưng mỗi token chỉ kích hoạt 49 tỷ."
Câu này không sai. Nhưng nếu dừng ở đó, người đọc rất dễ trượt theo hai hướng đối lập, và cả hai đều dẫn tới quyết định kỹ thuật sai. Cần unpack một chút.
Cơ chế thật sự
V4-Pro có 384 routed expert ở mỗi layer, tổng 61 layer. Mỗi expert là một feed-forward sub-network nhỏ. Khi một token đi qua một layer, có một bộ phận gọi là router quyết định: token này nên đi vào expert nào? V4 chọn 6 expert per token (top-6 theo router score). Kết quả:
- Toàn bộ 1.6T params vẫn phải nằm sẵn trong RAM hoặc VRAM, vì không biết trước token tiếp theo route vào expert nào.
- Compute thực tế chỉ chạy qua 6 expert được chọn ở mỗi layer, cộng các phần shared (attention, embedding, shared expert). Tổng FLOPs tương đương một model 49B params dense.
Hai loại cost rất khác nhau
Đây là chỗ dễ nhầm nhất khi đọc câu trên:
- Compute cost (FLOPs trên mỗi token, latency, tiền bạn trả cho API): tính theo 49B active. V4-Pro inference nhanh và rẻ gần như một model dense 49B, không phải 1.6T. Đây là lý do pricing $1.74/$3.48 mỗi triệu token không phá sản DeepSeek.
- Memory cost (VRAM hoặc RAM cần để host): tính theo 1.6T total. Đây là lý do self-host V4-Pro cần 8x H200 (1.1 TB tổng VRAM), không phải một con H100 80 GB.
Câu summary mình hay dùng để nhớ: MoE rẻ về compute, đắt về memory.
Hai hiểu sai phổ biến
Hiểu sai 1: "49B active nghĩa là V4-Pro capacity tương đương một model dense 49B."
Sai. Knowledge của model được lưu trải đều trên cả 1.6T expert. Token A route vào expert {3, 47, 102, 188, 245, 301}, token B route vào expert hoàn toàn khác. Cộng dồn lại, model "biết" lượng kiến thức tương đương một dense model lớn hơn 49B nhiều. Một ước lượng thô hay được dùng: MoE tương đương dense khoảng $\sqrt{\text{active} \times \text{total}}$ params, tức V4-Pro $\approx$ dense $\sqrt{49 \times 1600} \approx 280$B. Đây chỉ là rule of thumb, thực tế phụ thuộc nhiều thứ (chất lượng routing, độ overlap giữa các expert, training data).
Hiểu sai 2: "Vậy thì dense 49B cũng tương đương MoE 49B-active, đỡ phải build MoE phức tạp."
Cũng sai theo hướng ngược lại. Dense 49B chỉ có 49B knowledge. MoE 49B-active có capacity vượt xa 49B. Cái giá phải trả là memory footprint và hạ tầng phức tạp hơn nhiều: router phải train cùng, load balancing giữa các expert, all-to-all communication khi distribute experts qua nhiều GPU.
Vì sao DeepSeek đẩy sparsity cao
Tỉ lệ active trên tổng của V4-Pro là $49/1600 \approx 3.1\%$, V4-Flash là $13/284 \approx 4.6\%$. Để so sánh, Gemma 4 26B MoE là 14.6%. DeepSeek đặt cược rằng càng sparse càng tách biệt được giữa "rẻ inference" và "lớn capacity". Cái giá của canh bạc này là router phải chính xác hơn nhiều (sai một lần là token bị đẩy vào expert kém liên quan), training phải ổn định hơn (đây cũng là một lý do họ phải invent Anticipatory Routing và SwiGLU Clamping ở section sau).
Lần tới khi đọc "1.6T tổng nhưng chỉ 49B active", trong đầu bạn cần ghi cùng lúc ba thứ: rẻ như nhỏ về tiền, lớn hơn nhỏ về kiến thức, nặng đúng bằng tổng về phần cứng. Ba con số này không gộp lại thành một được.
Đổi mới #1: Hybrid Attention với CSA và HCA

CSA (Compressed Sparse Attention) và HCA (Heavily Compressed Attention) là hai loại attention layer DeepSeek V4 xen kẽ trong network. CSA nén KV cache 4:1 rồi chọn top-k entries quan trọng nhất; HCA nén mạnh hơn 128:1 rồi đọc hết. Kết quả ở context 1M token: V4-Pro tốn 27% FLOPs và 10% KV cache so với V3.2.
Đây là phần đáng đào sâu nhất, vì nó chính là canh bạc trung tâm.
Vấn đề nền tảng đã được biết hơn 8 năm: vanilla attention có complexity bậc 2 với độ dài chuỗi. Một câu 1000 token cần tính 1 triệu attention scores. Một context 1 triệu token cần 1 nghìn tỷ. Đây là lý do vì sao "long context" trong các model trước thường là gắn bó vá víu. Gemini scale context bằng compute. Claude dùng chunk-and-stitch. OpenAI o1 dùng test-time compute để bù.
DeepSeek chọn con đường khác: thay đổi cấu trúc attention, không chỉ scale brute force. V4 dùng hai kiểu attention layer khác nhau, xen kẽ trong network.
Intuition trước: tưởng tượng search engine
Trước khi đi vào chi tiết, một ví dụ giúp dễ hình dung. Khi bạn search Google, search engine không đọc full content của hàng tỷ trang web mỗi lần query - bất khả thi. Quy trình thực tế gồm ba bước:
- Index trước: nén toàn bộ web thành snippet ngắn (title + meta + một ít context)
- Chấm điểm nhanh: với mỗi query, chấm độ liên quan cho từng snippet
- Chỉ đọc top-k: trả về và đọc kỹ vài chục kết quả đầu, bỏ qua phần còn lại
CSA chính là quy trình này, áp vào attention layer của LLM. HCA chọn triết lý ngược: nén cực mạnh để list đủ ngắn, sau đó đọc hết không cần lọc.
Compressed Sparse Attention (CSA): nén nhẹ rồi chọn lọc
CSA làm hai bước, đúng theo lý lẽ của search engine.
Bước 1 - Index: nén KV cache thành các "snippet". Cứ 4 token liên tiếp được gom thành 1 entry tóm tắt (compression rate $m=4$). Việc nén dùng learned weights chứ không phải pooling kiểu trung bình cộng đơn giản - tức model học được cách giữ thông tin nào quan trọng, bỏ cái nào ít giá trị. Để giảm rủi ro mất thông tin, paper tạo song song hai bộ entries $C^a$ và $C^b$ với công thức nén khác nhau, kiểu như có hai phiên bản snippet độc lập của cùng một đoạn.
Bước 2 - Chấm điểm và pick top-k. Một module tên Lightning Indexer chấm độ liên quan giữa query token hiện tại với từng entry tóm tắt, sau đó chỉ giữ top-k cao điểm nhất: 512 với V4-Flash, 1024 với V4-Pro. Core attention - phần tốn compute thực sự - chỉ chạy trên top-k này, bỏ qua phần lớn entries còn lại.
Điểm đáng chú ý: Lightning Indexer chạy hoàn toàn trong FP4 (precision 4 bit, cực thô). Nếu bạn nghĩ FP4 quá thô để chấm điểm chính xác, paper báo recall rate 99.7% so với FP32 baseline, với speedup 2x. Trade-off rất khôn: Indexer không cần perfect, nó chỉ cần pick đúng top-k chứa hầu hết tín hiệu cần - giống Google không cần ranking chính xác đến chữ số thập phân, nó chỉ cần đẩy đúng 10 link đầu lên top.

Page 19 paper. Hai claim quan trọng: (1) Lightning Indexer trong FP4 chỉ mất 0.3% recall, (2) FP4-to-FP8 dequantization là lossless nhờ E4M3 format. Đây là chỗ kỹ thuật cho phép FP4 reuse toàn bộ FP8 framework.
Heavily Compressed Attention (HCA): nén mạnh, đọc hết
HCA bỏ luôn bước score-and-select. Thay vào đó, nó nén cực mạnh ($m'=128$, cứ 128 token thành 1 entry), sau đó đọc hết danh sách kết quả với dense attention bình thường.
Quay lại ví dụ search engine: nếu CSA giống trang đầu Google (snippet vừa phải, đọc top-10), HCA giống mở mục lục của một cuốn sách dày - mỗi chương tóm tắt thành 1 dòng, và bạn lướt qua hết tất cả các dòng đó. Vì list đã ngắn rồi (1M token nén 128:1 còn ~8K entries), dense attention không còn đắt nữa, và bỏ Indexer giúp tiết kiệm thêm vòng compute.
Tại sao split thành hai loại layer?
Paper không nói thẳng, nhưng nhìn vào con số thì rõ. CSA giữ độ chính xác cao ở cost cao hơn. HCA cực kỳ rẻ nhưng độ chi tiết thô. Xen kẽ hai cái cho ra network mà mỗi token được "nhìn thấy" qua hai góc nhìn khác nhau ở các layer khác nhau: góc nhìn chi tiết chọn lọc (CSA) và góc nhìn tổng quan đọc hết (HCA). Average cost giảm mạnh, precision không sụp.
Một detail mình bỏ qua để khỏi loãng: cả hai loại layer còn có nhánh sliding window nhỏ (giữ 128 token gần nhất ở dạng nguyên không nén) để bắt local dependencies, plus một trick về cách apply RoPE để giữ relative position invariance. Ai muốn đào sâu có thể đọc Section 3.1 của paper.
Kết quả: ở context 1M token, V4-Pro tốn 27% FLOPs và 10% KV cache so với V3.2. V4-Flash tốn 10% FLOPs và 7% KV cache. So với một baseline BF16 GQA8 head dim 128 thông thường, KV cache giảm xuống còn 2% kích thước gốc.
2%. Để dễ hình dung: nếu một model thông thường cần 50GB KV cache cho 1M context, V4-Pro chỉ cần 1GB cho cùng workload. Đây không phải optimization tăng tiến. Đây là thay đổi định nghĩa "có thể làm được" với một con GPU đơn lẻ.
Đổi mới #2: Manifold-Constrained Hyper-Connections (mHC)

Nếu CSA/HCA là canh bạc về hiệu năng, mHC là canh bạc về độ ổn định khi scale model lên rất lớn.
Vì sao residual connections tồn tại
Quay lại lịch sử một chút. Trước 2015, mạng deep neural network sâu hơn 20 layer rất khó train - gradient bị "vanish" (mờ dần) khi backpropagate qua nhiều layer. ResNet (2015) giải quyết bằng một idea đơn giản: thêm một "đường tắt" bên cạnh mỗi layer. Công thức: $x_{l+1} = x_l + F(x_l)$. Output của layer $l+1$ = input gốc cộng với phần biến đổi $F$. Đường tắt này cho phép gradient đi thẳng qua nhiều layer mà không bị mờ.
Hình dung: residual giống một đường cao tốc một làn chảy xuyên suốt network. Mỗi layer thêm một chút đóng góp $F(x_l)$ vào dòng chính, nhưng dòng chính không bao giờ bị thay thế hoàn toàn.
Cách này hoạt động tuyệt vời cho 8 năm, nhưng có giới hạn. Một làn duy nhất nghĩa là tất cả layer phải share cùng "channel thông tin". Không có cách nào để một số layer chuyên xử lý low-level features còn một số khác chuyên high-level features ở các stream tách biệt.
Hyper-Connections (HC): nhiều làn song song
Hyper-Connections mở rộng idea trên. Thay vì một làn duy nhất, HC dùng nhiều làn song song (4 làn trong V4, expansion factor $n_{hc}=4$). Giữa mỗi layer, một mixing matrix quyết định thông tin chảy giữa các làn như thế nào - làn 1 góp bao nhiêu vào làn 2, làn 3 lấy bao nhiêu từ làn 4, v.v.
Lợi ích: linh hoạt hơn nhiều. Một làn có thể giữ thông tin gốc gần như nguyên vẹn, làn khác có thể tích lũy biến đổi mạnh, các làn pha trộn theo cách tối ưu cho từng tầng.
Vấn đề với HC: signal explode sau 60+ layer
Đây là chỗ V4 gặp rắc rối. Mixing matrix là một ma trận, và mọi ma trận có một đại lượng gọi là spectral norm - hiểu nôm na là hệ số khuếch đại tối đa khi nhân ma trận đó với một vector. Nếu spectral norm > 1, mỗi lần signal đi qua một layer thì độ lớn của nó tăng lên.
Trong V4-Pro với 61 layer xếp chồng, nếu mỗi layer khuếch đại signal lên 1.05 lần, thì sau 61 layer signal đã to gấp $1.05^{61} \approx 18.7$ lần - không quá tệ. Nhưng nếu mỗi layer khuếch đại 1.2 lần, sau 61 layer là $1.2^{61} \approx 73000$ lần - explode hoàn toàn. Loss spike, gradient biến thành infinity, training crash.
Vấn đề tương tự với "lãi kép" trong tài chính: một tỷ lệ tăng nhỏ qua nhiều kỳ trở thành con số khổng lồ.
mHC: ép mixing matrix không bao giờ khuếch đại
mHC giải quyết bằng cách bắt buộc mixing matrix luôn có spectral norm ≤ 1. Tức là: signal đi qua mỗi layer không bao giờ to hơn lúc trước. Bất kể bao nhiêu layer xếp chồng, signal không thể explode.
Cụ thể, mHC ép mixing matrix vào một họ ma trận đặc biệt gọi là doubly stochastic matrix (ma trận song ngẫu nhiên). Định nghĩa: tất cả phần tử không âm, mỗi hàng cộng lại bằng 1, mỗi cột cộng lại bằng 1. Đây là một tính chất "cân bằng": tổng input vào mỗi làn = tổng output ra mỗi làn = 1, không có làn nào "ăn gian".
Tập hợp các ma trận như vậy trong toán học gọi là Birkhoff polytope (một dạng hình học n-chiều). Một định lý quan trọng: mọi ma trận song ngẫu nhiên đều có spectral norm ≤ 1. Bất cứ ma trận nào trong họ này, nhân với vector cũng không làm vector to lên.
Để training, mỗi step ta cần "chiếu" (project) ma trận hiện tại về tập Birkhoff polytope. Paper dùng thuật toán Sinkhorn-Knopp: lặp đi lặp lại normalization theo hàng rồi theo cột, 20 lần là đủ. Quá trình này differentiable nên có thể train end-to-end với gradient descent bình thường.
Tác dụng phụ tích cực: bỏ luôn QK-Clip
Một điểm đẹp của mHC: vì đảm bảo signal không explode, V4 không cần dùng QK-Clip - một heuristic mà các model trillion-param khác thường phải dùng để cap attention logit khỏi blow-up. QK-Clip là một dạng "băng dán" mà cộng đồng đã chấp nhận như "necessary evil". mHC làm cho cái băng dán đó không cần thiết nữa - ví dụ đẹp về việc innovation đúng kiến trúc cho phép gỡ bớt heuristic.
Cái giá phải trả: paper thừa nhận mHC ăn thêm 6.7% wall-time mỗi 1F1B pipeline stage. Không phải miễn phí, nhưng đáng đổi để có stability ở 60+ layer.
Đổi mới #3: Muon Optimizer

DeepSeek thay AdamW bằng Muon cho hầu hết các module trong V4 (chỉ giữ AdamW cho embedding, prediction head, RMSNorm, mHC parameters, và các static biases).
AdamW làm gì? Và nó "thiên lệch" ở đâu?
Trước khi nói Muon, cần hiểu AdamW làm gì. Optimizer là module quyết định cách update weights sau mỗi training step. Cho gradient $g$ (báo cho biết weights nên thay đổi theo hướng nào để giảm loss), optimizer tính ra update $\Delta W$ thực tế.
AdamW làm hai việc thông minh: (1) tính momentum (trung bình gradient các step gần nhất, để smooth ra noise), (2) chia mỗi component cho căn bậc hai trung bình bình phương của nó (adaptive learning rate per parameter). Kết quả là weights được update theo direction gần với gradient nhưng có "phanh" tự động cho các direction biến động mạnh.
Vấn đề: gradient của một weight matrix thường thiên lệch về một số ít direction. Nếu xem matrix $g$ như một bản đồ, hầu hết "năng lượng" tập trung ở vài column hay row chính. AdamW follow gradient này, nên update cũng thiên lệch theo. Một số direction được train mạnh, một số khác bị bỏ rơi.
Hình dung: bạn đang chèo thuyền nhưng một mái chèo mạnh hơn mái kia rất nhiều. Thay vì tiến thẳng về phía trước, thuyền cứ lệch sang một bên rồi bạn phải sửa hướng liên tục.
Muon: cân bằng update trước khi apply
Muon thêm một bước trung gian: trước khi update weights, "cân bằng lại" matrix update sao cho mọi direction đều có đóng góp ngang nhau. Về mặt toán, đây là phép orthogonalization: ép matrix update về một matrix mà tất cả singular value đều bằng 1. Singular value đo "độ mạnh" theo mỗi direction chính, ép tất cả về 1 nghĩa là không direction nào trội hơn direction nào.
Quay lại analogy chèo thuyền: Muon đảm bảo cả hai mái chèo có lực đẩy bằng nhau. Thuyền tiến thẳng, không cần sửa hướng.
Newton-Schulz: cách rẻ để cân bằng matrix
Trên giấy, orthogonalize một matrix là phép tính SVD - rất đắt. Newton-Schulz là một thuật toán iterative xấp xỉ rẻ hơn nhiều: lặp đi lặp lại một công thức polynomial đơn giản, sau vài lần là singular values của matrix tiệm cận 1.
V4 dùng biến thể hybrid với 10 iteration chia thành 2 giai đoạn: - Giai đoạn 1 (8 steps) với coefficients $(3.4445, -4.7750, 2.0315)$: đẩy singular values từ giá trị gốc về gần 1 nhanh nhất có thể. - Giai đoạn 2 (2 steps) với coefficients $(2, -1.5, 0.5)$: cố định chính xác tại 1, không vượt quá.
Tại sao tách hai giai đoạn? Vì coefficients tối ưu cho "đẩy nhanh" khác với coefficients tối ưu cho "ổn định gần 1". Một loop đơn giản dùng cùng coefficients sẽ thiếu cái hai. Đây là chi tiết kỹ thuật đáng chú ý - nó cho thấy mức độ kỹ lưỡng của team DeepSeek.
Vì sao quan trọng
Muon converge nhanh hơn AdamW ở các setting trillion-param MoE, và quan trọng hơn, nó ổn định hơn ở các edge case. Kết hợp với mHC (đảm bảo signal không explode forward), V4 có một training stack mà loss spikes hiếm hơn nhiều so với V3.
Đổi mới #4: FP4 Quantization-Aware Training

Quantization là gì? Hình dung qua ảnh JPEG
Quantization là kỹ thuật giảm độ chính xác của số trong model để tiết kiệm memory. Cách hình dung dễ nhất là so sánh với nén ảnh: PNG full quality cần 5MB, JPEG quality 80% cần 500KB. Mất một chút chi tiết, nhưng người xem hầu như không nhận ra.
Với neural network cũng vậy. Mỗi weight bình thường lưu bằng 32 bit (FP32), tức 4 byte. Nén xuống FP8 (1 byte) tiết kiệm 4 lần memory; xuống FP4 (nửa byte) tiết kiệm 8 lần. Với một model 1.6 nghìn tỷ parameters như V4-Pro, đây là khác biệt giữa "không chạy nổi" và "chạy được trên một cụm GPU vừa phải".
Vấn đề: nén quá mạnh thì model dở hẳn. FP4 chỉ có 4 bit, tức chỉ 16 giá trị khả thi - rất thô. Một weight gốc 0.7234 có thể bị làm tròn thành 0.75. Sai số 0.0266 nhân lên qua hàng tỷ phép tính sẽ dẫn đến output rất khác.
Quantization thường vs Quantization-Aware Training (QAT)
Có hai cách quantize, và sự khác biệt giữa chúng là chìa khoá hiểu V4.
Cách 1 - Post-Training Quantization (PTQ): train model bình thường ở FP32, train xong mới nén weights xuống FP4. Đơn giản, nhưng thường tổn thất accuracy nhiều. Lý do: model đã optimize cho high precision rồi, ép xuống low precision sau đó như ép một bài thơ tiếng Việt thành 5 từ - mất ý.
Cách 2 - Quantization-Aware Training (QAT): train với FP4 ngay từ đầu. Trong forward pass, model dùng FP4 weights, nên nó "biết" mình sống trong thế giới low-precision và tự học cách bù trừ. Backward pass vẫn cần FP32 để tính gradient chính xác (master weights), nhưng update sẽ tự động đẩy weights về các giá trị mà FP4 representable tốt. Kết quả: model FP4 cuối cùng accuracy gần bằng FP8 hoặc FP16.
Khác biệt cốt lõi: PTQ là "nén sau", QAT là "training trong điều kiện đã nén". V4 chọn QAT cho hai chỗ tốn memory nhất - MoE expert weights (phần lớn parameters của model) và Query-Key path trong Lightning Indexer của CSA.
Vì sao FP4 khó: dynamic range hẹp
FP4 chuẩn dùng format E2M1: 1 bit dấu, 2 bit exponent, 1 bit mantissa. Exponent chỉ 2 bit nghĩa là dynamic range cực hẹp (khoảng cách giữa số nhỏ nhất và số lớn nhất biểu diễn được rất gần nhau). Nhưng matrix multiplication thông thường có range giá trị rất rộng - làm sao nhét vào FP4?
Giải pháp ngành dùng là block scaling (chuẩn MXFP4): chia weights thành các block nhỏ (1×32 trong V4), mỗi block có một scale factor riêng lưu ở FP8. Weight thực = giá trị FP4 × scale factor của block. Range hẹp của FP4 được bù bằng việc scale factor co giãn theo từng block - block nào toàn số nhỏ thì scale nhỏ, block nào toàn số lớn thì scale lớn.
Trick khôn: lossless dequant FP4 sang FP8
Đây là chỗ thông minh nhất của V4. FP8 trong DeepSeek dùng format E4M3 (4 exponent bits, 3 mantissa) - tức có 2 bit exponent nhiều hơn FP4 (E2M1). Hai bit exponent extra này cho FP8 dynamic range rộng hơn FP4 đúng 4 lần (2² = 4).
Trong V4, ratio giữa max và min scale factor của các FP4 sub-blocks không bao giờ vượt quá ngưỡng đó. Hệ quả: bạn có thể dequantize FP4 weight về FP8 mà không mất bit nào - lossless theo nghĩa toán học chứ không phải approximation.
Điều này quan trọng vì DeepSeek đã đầu tư công sức xây FP8 mixed-precision training framework từ V3. Nếu FP4 → FP8 lossless, họ reuse toàn bộ framework đó. Không cần thiết kế lại backward pipeline cho FP4, không cần re-quantize transposed weights. Toàn bộ engineering effort cho FP4 QAT giảm xuống còn vài chỗ patch nhỏ.
Khi inference: dùng FP4 thẳng, không dequant
Trong giai đoạn inference và RL rollout, model dùng FP4 weights luôn, không dequant lên FP8. Memory traffic giảm mạnh, sampling latency giảm, và quan trọng nhất là behavior nhất quán với deployment - tránh trường hợp "model train tốt nhưng deploy ra dở" do precision mismatch.
Một chi tiết ấn tượng cuối: paper viết rằng peak FLOPs của FP4×FP8 hiện tại bằng FP8×FP8 trên hardware Nvidia hiện hành, nhưng "theoretically can be implemented to be 1/3 more efficient on future hardware". Đây là câu rất nhỏ nhưng thông điệp lớn: V4 đang được thiết kế cho hardware mà chưa tồn tại khi training, dự báo về thế hệ chip kế tiếp. Mình sẽ quay lại điểm này ở phần hardware bet.
Post-Training: từ Mixed RL sang On-Policy Distillation

Đây là bước thay đổi căn bản đáng nhấn mạnh.
Vấn đề với mixed RL: ép một model làm tất cả
Trong V3.2, post-training là một mixed RL pipeline phức tạp. Một model duy nhất được train để giỏi mọi thứ - math, coding, agent task, instruction-following - bằng cách trộn nhiều reward signal khác nhau, cẩn thận balance để tránh model "hack" một reward và bỏ rơi cái khác.
Hình dung: bạn ép một đầu bếp duy nhất phải nấu giỏi cả phở Việt, sushi Nhật, pasta Ý, dim sum Hong Kong cùng lúc. Kết quả thường là mỗi món ăn được tạm tạm, không món nào xuất sắc. Cộng thêm việc balance reward giữa các domain rất khó - thêm trọng số cho coding, math performance giảm; tăng math, agent performance giảm.
V4 vứt cái này đi và dùng một cấu trúc 2 giai đoạn rõ ràng.
Giai đoạn 1: Specialist Training - mỗi domain một chuyên gia
Thay vì train một model làm tất cả, V4 train một specialist model riêng cho từng domain: math specialist, code specialist, agent specialist, instruction-following specialist. Mỗi specialist xuất phát từ V4-Pro-Base và đi qua pipeline: 1. SFT (Supervised Fine-Tuning) trên data domain đó - dạy model cách trả lời chuẩn 2. RL với GRPO - tự học cách tối ưu cho reward của domain đó
Quay lại analogy: thay vì một đầu bếp tổng hợp, bạn có 4 đầu bếp chuyên - một sư phụ phở, một master sushi, một chef pasta, một chuyên gia dim sum. Mỗi người được train độc lập đến cực hạn của domain đó.
Một chi tiết thú vị về reward: thay vì dùng một reward model riêng (scalar critic) như cách truyền thống, V4 dùng Generative Reward Model (GRM). Idea: chính actor model cũng đóng vai trò judge - nó vừa generate response, vừa tự đánh giá response của mình. Tránh được việc phải maintain một critic model riêng, và giảm nhu cầu human annotation cho các task khó verify (như "câu trả lời này có hợp logic không?").
Giai đoạn 2: On-Policy Distillation (OPD) - học trò copy nhiều thầy
Sau khi có 4+ specialist, V4 cần combine tất cả vào một model duy nhất để deploy (không thể serve 10 model song song). Đây là việc của OPD.
Distillation là kỹ thuật dạy một "student model" bắt chước một "teacher model" - student học cách output xác suất giống teacher cho mỗi input. Trong V4, student là model unified, các teacher là 10+ specialist đã train.
On-policy nghĩa là student tự sample các trajectory (prompts + responses), rồi với mỗi sample đó, so sánh distribution của student với distribution của teacher tương ứng. Loss tổng là weighted sum của KL divergence với từng teacher:
$$\mathcal{L}_{\text{OPD}}(\theta) = \sum_i w_i \cdot D_{\text{KL}}\!\left(\pi_\theta \,\|\, \pi_{E_i}\right)$$
Trong đó $\pi_\theta$ là student, $\pi_{E_i}$ là teacher specialist thứ $i$, $w_i$ là weight quyết định teacher nào quan trọng cho task này.
Một chi tiết kỹ thuật quan trọng: V4 dùng full-vocabulary reverse KL chứ không phải token-level estimate. Reverse KL nghĩa là so distribution xác suất trên toàn bộ vocabulary (~150K token) cho mỗi position - không chỉ vài token được sample. Token-level estimate (cách đơn giản hơn) có variance cao, dẫn tới training instability ở các attempt trước. Full-vocab tốn memory hơn nhiều (phải giữ teacher weights trên GPU), nên paper dedicate cả một section để giải thích cách offload và schedule efficiently.
Vì sao chuyển này quan trọng
Quay lại analogy đầu bếp: trong V3.2, một đầu bếp tổng hợp đạt mỗi món ở mức 7/10. Trong V4, mỗi đầu bếp chuyên đạt 9.5/10 ở món của mình, sau đó học trò copy từ tất cả, đạt được trung bình 9/10 cho mọi món. "Best of all worlds" thay vì "average of all worlds".
Bonus: Quick Instruction tokens
Paper introduce thêm một tool nhỏ nhưng đẹp: các special token như <|action|>, <|title|>, <|query|>, <|authority|>, <|domain|>, <|extracted_url|>, <|read_url|>.
Vấn đề: trong production chatbot, ngoài việc generate response chính, model cần làm nhiều task phụ - quyết định có cần web search không, tạo title cho conversation, classify domain của câu hỏi. Cách truyền thống dùng các small auxiliary model riêng cho mỗi task, và mỗi cái cần re-prefill toàn bộ context (rất tốn).
Quick Instruction tokens inline các task này vào main model. Khi cần classify domain, chỉ cần generate một token đặc biệt như <|domain|> rồi đọc output - reuse KV cache đã compute cho main response. Time-to-first-token giảm đáng kể. Đây là một dạng "vertical integration" rất Apple-like trong infrastructure: tự build mọi thứ vào trong cùng một pipeline thay vì gọi nhiều service riêng.
Training stability: hiếm hoi một report dám thừa nhận chưa hiểu

Một điều mình đánh giá cao trong paper là phần thảo luận về training instability. Hầu hết technical report viết như mọi thứ chạy ngon từ đầu. V4 paper viết:
"We encountered notable instability challenges during training. While simple rollbacks could temporarily restore the training state, they proved inadequate as a long-term solution."

Page 26 paper, mục 4.2.3 Mitigating Training Instability. Câu mở đầu thừa nhận thẳng "We encountered notable instability challenges". Rare honesty.
Sau đó họ giải thích cách sửa từ thực nghiệm: loss spike liên tục đến từ các giá trị outlier trong MoE layer, và cơ chế routing càng làm outlier khuếch đại lên. Họ tìm ra hai kỹ thuật giúp ổn định:
- Anticipatory Routing: tách rời việc cập nhật routing khỏi việc cập nhật backbone. Tại bước $t$, model vẫn dùng trọng số hiện tại để tính feature, nhưng quyết định route token đi đâu (chọn expert nào) lại dựa vào trọng số cũ ở bước $t-\Delta t$. Kỹ thuật này chỉ bật lên khi phát hiện loss spike, không bật mặc định.
- SwiGLU Clamping: kẹp giá trị của thành phần linear trong SwiGLU vào khoảng $[-10, 10]$, và cap chặn trên của thành phần gate ở mức $10$. Cách làm thuần thực nghiệm, nhưng triệt outlier rất hiệu quả.
Điểm thật thà: paper viết nguyên văn "Although Anticipatory Routing and SwiGLU Clamping have been proven effective in mitigating training instabilities, their underlying principles remain insufficiently understood" - tạm dịch: "Mặc dù Anticipatory Routing và SwiGLU Clamping đã được chứng minh là hiệu quả trong việc giảm bất ổn khi train, nguyên lý bên dưới vẫn chưa được hiểu thấu đáo". Đây là sự thật thà hiếm thấy trong ngành. Họ có giải pháp chạy được, nhưng chưa hiểu hết vì sao chạy được, và họ nói thẳng điều đó.

Page 44 paper, phần Conclusion. DeepSeek admit cả hai technique work nhưng họ chưa hiểu vì sao. Hầu hết technical report của OpenAI, Anthropic, Google không bao giờ viết câu này.
Phản đề: V4 vẫn thua frontier, vậy có ý nghĩa gì?

Mình đã build up các innovations xong. Giờ là phần khó: trình bày tất cả phản đề ở dạng mạnh nhất rồi mới quyết.
Counter-argument đáng nói nhất là số liệu benchmark thẳng từ paper.
| Benchmark | Opus 4.6 Max | GPT-5.4 xHigh | Gemini 3.1 High | DS-V4-Pro Max |
|---|---|---|---|---|
| MMLU-Pro | 89.1 | 87.5 | 91.0 | 87.5 |
| SimpleQA-Verified | 46.2 | 45.3 | 75.6 | 57.9 |
| GPQA Diamond | 91.3 | 93.0 | 94.3 | 90.1 |
| HLE | 40.0 | 39.8 | 44.4 | 37.7 |
| Codeforces (rating) | - | 3168 | 3052 | 3206 |

Table 6 (page 38 paper). Highlight: SimpleQA-Verified 57.9 (kém Gemini 17.7 điểm) và Codeforces 3206 (best ở 3 model). Bức tranh hai chiều: thua reasoning, thắng coding.
V4-Pro-Max thắng Codeforces. Nhưng trên các benchmark knowledge và reasoning khó, gap vẫn rõ: SimpleQA-Verified 57.9 vs Gemini 75.6 là 17.7 điểm. HLE thua mọi frontier model. GPQA Diamond cũng thua.
Người phản biện sẽ nói: "Nếu mình cần model tốt nhất, mình dùng Claude Opus 4.7 hoặc GPT-5.5. V4 chỉ là một option rẻ hơn cho người không đủ tiền. Đó không phải winning, đó là survival."
Và họ có lý. Trong các use case mission-critical, vài điểm benchmark có thể là khác biệt giữa model usable và unusable. Nếu bạn build một product mà reasoning quality là make-or-break, V4 không phải lựa chọn đầu tiên.
Mình đã ngồi với phản biện này nhiều ngày. Sau đó nhận ra: nó đúng cho hôm nay, nhưng có thể hoàn toàn sai cho ngày mai.
Mở ngoặc: V4 đặt cạnh Gemma 4
Bảng phản đề ở trên so V4 với closed-source frontier (Opus, GPT-5, Gemini). Nhưng tháng 4/2026 này có một câu hỏi tự nhiên khác: cùng là open-weight, V4 đứng cạnh Gemma 4 (Google release đầu tháng 4, Apache 2.0) thì sao?
Đầu tiên, đừng so kích thước trực tiếp. V4-Pro 1.6T tổng và 49B active, Gemma 4 31B Dense, lệch khoảng 50 lần về tổng params. Nhưng vài chỉ số đứng cùng đơn vị nên đối chiếu được:
- Codeforces rating: V4-Pro-Max 3206. Gemma 4 31B 2150. Cách nhau hơn 1000 điểm Elo, V4 thắng rõ trên thuật toán contest, dù lệch params lớn.
- Sparsity của MoE: V4-Flash chạy 4.6% tổng params mỗi token (13B / 284B). Gemma 4 26B MoE chạy 14.6% (3.8B / 26B). V4 sparse hơn ba lần. Đây là hai canh bạc khác nhau, V4 cược rằng càng sparse càng cheap inference, Gemma cược rằng dense vừa phải thì routing ổn định và dễ deploy hơn.
- Context native: V4 1M token. Gemma 4 256K. Lệch 4 lần.
Nhưng chỉ số không phải phần thú vị nhất. Phần thú vị là hai model đang đua hai cuộc khác nhau, dù cùng gắn nhãn "open-weight frontier 2026":
- Gemma 4 tối ưu cho laptop, single GPU, edge device. E2B chạy được trên điện thoại, 31B Dense chạy ngon trên một con RTX 5090. Multimodal đầy đủ (text, image, audio, video). Apache 2.0 thoải mái commercial. Gemma 4 muốn trở thành kiểu "Linux của LLM", chạy được mọi nơi.
- V4 tối ưu cho cluster, agent, long context. 1.6T params không có cách nào nhét vào consumer hardware (xem section self-host phía dưới). Text-only. Mục tiêu là làm frontier model đầu tiên thật sự usable cho agentic coding với codebase 200K LOC nguyên monorepo.
Một điểm Gemma 4 vẫn dẫn V4 rõ ràng: multimodal. V4 không support vision, audio, hay video. Nếu use case có ảnh hoặc video, Gemma 4 (hoặc Qwen-VL, hoặc các dòng tương tự) là lựa chọn bắt buộc, V4 không vào sân.
Nói gọn: nếu bạn build desktop app cần LLM offline, default là Gemma 4. Nếu bạn build coding agent đọc cả monorepo, default là V4. Hai model này về vị trí thị trường gần như không cạnh tranh trực tiếp, mặc dù cùng release tháng 4 và cùng được gắn nhãn "open-weight frontier".
Pivot point: cuộc đua mà không ai chạy

Đây là khoảnh khắc mình nghĩ câu chuyện chuyển hướng.
Benchmarks hiện tại được thiết kế cho context ngắn. MMLU-Pro, GPQA, HLE, SimpleQA, gần như tất cả test với input dưới 10K token. Đây là vì khi các benchmark này được tạo, không ai có model xử lý được 1M token một cách thực tế.
V4 vừa thay đổi điều đó. Khi 1M context với 10% KV cache trở thành baseline, không phải edge case, bộ benchmark chúng ta dùng bắt đầu đo sai thứ.
Ví dụ cụ thể nhất: agentic coding. Một codebase Rust 200K LOC dễ vượt 500K token. Một agent đang debug cần load full codebase + git history + test results vào context. Trong setup này, model nào trade một chút reasoning để có 5x cheaper context length sẽ thắng, không phải vì smarter, mà vì có thể nhìn thấy nhiều hơn.
Paper báo cáo trong real-world R&D coding benchmark (200 task từ 50+ engineer DeepSeek nội bộ): V4-Pro pass rate 67%, vượt Sonnet 4.5 (47%), gần Opus 4.5 (70%). Codeforces, V4-Pro-Max rank thứ 23 trong số human candidates với rating 3206. Trong survey nội bộ với 85 developer DeepSeek hỏi V4-Pro có sẵn sàng làm primary coding model không, 52% nói "yes", 39% lean "yes", dưới 9% nói "no".
Caveats lớn: survey nội bộ, N=85, có bias. Benchmarks DeepSeek tự đo. Real-world deploy ở scale có thể fail. Mình ghi confidence ở mức medium-high cho coding, low cho general reasoning.
Sau đó là pricing.
V4-Pro: $1.74 per million tokens input, $3.48 output. V4-Flash: $0.14 input, $0.28 output. Theo Simon Willison phân tích, V4-Pro gần khoảng nửa giá Claude Sonnet, và V4-Flash rẻ hơn cả GPT-5 Nano.
Khi efficiency curve dốc hơn capability curve, calculus thay đổi. Một model 90% capability của Opus với 10% giá có thể là deal tốt hơn nhiều cho 80% use case. Đây không phải race to bottom về quality, đây là race to top về cost-effectiveness.
Self-host V4: bạn cần gì để chạy tại nhà?
Self-host V4-Flash cần tối thiểu 2x RTX 5090 (64GB VRAM) cho cá nhân, hoặc 1x H200 cho production. V4-Pro full công suất cần 8x H200 (~1.1TB VRAM tổng). Lý do MoE 1.6T params nhét vừa một node là CSA+HCA giảm KV cache xuống còn 2% so với GQA baseline - không có innovation đó, không có self-host.
Phần này dành cho ai đọc xong đoạn architecture rồi tự hỏi: ok, vậy mình có chạy được V4 trên máy mình hoặc cluster công ty mình không, và cần bao nhiêu tiền. Mình ngồi tính lại từ paper kết hợp một vài deployment guide đã xuất hiện trong tuần đầu sau release, chia thành ba mức rõ ràng.
Trước tiên, bảng cheat sheet về kích thước checkpoint thật sự bạn cần nạp lên RAM hoặc VRAM:
| Cấu hình | Total params | Active per token | Checkpoint size | KV cache cho 1M context |
|---|---|---|---|---|
| V4-Flash (FP4 cho expert + FP8 cho phần còn lại) | 284B | 13B | ~158 GB | ~7% so với GQA baseline |
| V4-Pro (FP4 cho expert + FP8 cho phần còn lại) | 1.6T | 49B | ~862 GB | ~2% so với GQA baseline |
| V4-Pro (BF16, giả định nếu không quantize) | 1.6T | 49B | ~3.2 TB | gấp 8 lần con số trên |
Một điều rất dễ nhầm khi mới nhìn MoE: active params chỉ ảnh hưởng compute, không ảnh hưởng memory. Bạn vẫn phải nạp toàn bộ expert lên GPU, vì không biết trước token tiếp theo sẽ route vào expert nào. Vậy nên 13B "active" của V4-Flash không có nghĩa là chỉ tốn $13 \times 2 = 26$ GB. Bạn vẫn cần đủ chỗ cho cả 284B parameter ngồi sẵn ở đâu đó.
Mức 1: Hobbyist, chạy V4-Flash cho cá nhân
Đây là mức khả thi nhất với người không có cluster.
Cấu hình tối thiểu để có thứ chạy được, dù không nhanh:
- 2x RTX 5090 (32 GB mỗi card, tổng 64 GB VRAM), hoặc 4x RTX 4090 (24 GB × 4 = 96 GB)
- 256 GB RAM hệ thống, để giữ expert chưa active và swap qua lại với VRAM
- 1 TB NVMe SSD để load checkpoint lần đầu
Tốc độ thực tế nằm trong khoảng 4 đến 12 token mỗi giây ở Q4 quantization. Context phải cắt xuống còn 64K hoặc 128K nếu muốn chạy mượt. Đây không phải setup production, đây là setup để bạn nghịch và học.
Chi phí build khoảng 4000 đến 6000 USD nếu mua mới. So với việc gọi API V4-Flash giá $0.14 input và $0.28 output cho mỗi triệu token, kinh tế khá tệ. Bạn cần dùng heavy 5 năm trở lên mới hoà vốn nếu tính cả tiền điện. Nhưng nếu lý do self-host là privacy hoặc air-gap, bài toán khác hẳn, lúc đó tiền không phải biến chính.
Mức 2: Single-node enterprise, V4-Flash chạy thật hoặc V4-Pro thử nghiệm
Đây là sweet spot cho công ty muốn deploy nội bộ.
Cho V4-Flash production, full 1M context, batch inference vài user đồng thời:
- 1x H200 141 GB là cận dưới, cần CPU offload một chút vì checkpoint 158 GB
- Hoặc 2x H200 nối NVLink, thoải mái, còn dư chỗ cho KV cache 1M context
- Throughput thực tế khoảng 30 đến 50 token mỗi giây, batch 4 đến 8 user
Cho V4-Pro thử nghiệm, context giảm xuống 256K thay vì full 1M:
- 8x H100 80 GB nối NVLink (tổng 640 GB) là cấu hình vừa khít
- Cần InfiniBand giữa các node nếu muốn scale ra nhiều máy
Trên AWS, p5.48xlarge (8x H100) khoảng $98 mỗi giờ on-demand, p5e.48xlarge (8x H200) khoảng $120 mỗi giờ. Reserved instance giảm chừng 40%. Một tháng chạy 24/7 trên p5e: 120 × 24 × 30 ≈ 86,400 USD. Con số này nói lên một điều đơn giản, V4-Pro full power không phải bài toán mà cá nhân hoặc startup early-stage tự run được. Bạn gọi API.
Mức 3: Production V4-Pro full công suất, 1M context, latency thấp
Đây là mức mà DeepSeek tự run khi serve API:
- 8x H200 hoặc DGX H100 node (tổng 1.1 TB VRAM)
- Hoặc 8x B200 192 GB (tổng 1.5 TB VRAM, throughput gấp 3 lần H200)
- 1 TB RAM hệ thống trở lên
- 2 TB NVMe trở lên
- Multi-node với InfiniBand nếu cần scale
Hoặc, nếu bạn đang ở Trung Quốc và có quota Ascend, deploy trên Huawei CloudMatrix với cluster Ascend 910C theo chuẩn ngành. Đây là điểm dẫn sang đoạn tiếp theo của bài.
Phần ít ai nói: KV cache mới là thứ cứu mạng self-host
Nhìn lại bảng trên: 1.6T parameter ở FP4 mix là 862 GB. Nếu V4 dùng KV cache như transformer GQA bình thường, thêm 1M context có thể cộng vào vài trăm GB nữa, đẩy V4-Pro vượt khỏi mọi single node hiện có trên thị trường. Lý do V4-Pro vẫn nhét vừa 8x H200 (1.1 TB) chính là CSA + HCA giảm KV cache xuống còn 2% so với GQA baseline.
Nói cách khác, kiến trúc Hybrid Attention không chỉ là đổi mới học thuật. Nó là yếu tố quyết định self-host có khả thi hay không. Một model 1.6T với KV cache GQA full FP16 thì không ai self-host được. Một model 1.6T với KV cache CSA+HCA FP8 thì tier-2 enterprise có thể chạy. Sự khác biệt giữa "không thể chạm tới" và "công ty 50 người mua được nếu thật sự cần" là vài đổi mới architecture nằm sâu trong paper mà 90% comment cộng đồng bỏ qua để cãi nhau về pricing.
Hardware bet: phần Wall Street chưa chú ý

Reuters đưa tin cuối tháng 2/2026 rằng DeepSeek chủ ý hoãn release V4 vài tuần để tối ưu cho chip Huawei Ascend. Theo các nguồn của Reuters, Nvidia và AMD cùng các AI accelerator khác bị xếp ưu tiên thấp hơn cho đợt release đầu. Đây là frontier model đầu tiên đặt cược hoàn toàn vào hardware inference của Trung Quốc.
Nhìn trong context paper, câu nói "FP4×FP8 can theoretically be 1/3 more efficient on future hardware" có nghĩa khác. DeepSeek đang thiết kế kiến trúc cho thế hệ chip Chinese kế tiếp, không phải cho Hopper hay Blackwell. Họ chấp nhận pay performance penalty trên Nvidia hiện tại để có alignment tốt hơn với Huawei roadmap.
Đây là điều tinh tế đáng theo dõi. Open weights (MIT license) nghĩa là ai cũng download được. Nhưng nếu V4 chạy tối ưu trên Ascend mà subtoptimal trên H100, thì Chinese cloud providers có inference cost advantage subtle nhưng durable. Open source không phải là moat. Hardware co-design mới là moat.
DeepSeek không công khai burn rate. Nhưng training 33T tokens trên Nvidia H800 (Pro) với architecture phức tạp này không thể rẻ. Pricing $1.74/$3.48 cho Pro, $0.14/$0.28 cho Flash, ai trả tiền? Có vài khả năng:
- Profit thật sự từ efficiency (architecture chính nó đã giảm cost mạnh)
- Subsidy từ CCP hoặc Huawei (loss-leader để adopt Ascend ecosystem)
- Không profit nhưng burn money để build market share
Mình nghiêng về combo của (1) và (2), confidence medium. (3) less likely vì DeepSeek không có VC pressure như OpenAI.
Cộng đồng phản ứng ra sao

Trong 48 tiếng sau release, mình đọc qua HN thread chính (1041 upvotes, 691 comments tại thời điểm viết) và nhiều thread r/LocalLLaMA. Hai pattern nổi lên rất rõ.
Pricing dominate discussion. Hầu hết commenters tập trung vào cost. Simon Willison viết bài phân tích với tiêu đề "almost on the frontier, a fraction of the price" và pricing comparison được upvote nhiều nhất. Mọi người so V4-Flash với GPT-5 Nano, V4-Pro với Sonnet 4.5. Architecture innovations gần như không được mention.
Architecture lại bị ignore. Đây là điều mình thấy lạ. CSA, HCA, mHC, FP4 QAT là những đóng góp technical đáng kể mà mình expect dev community sẽ dive in. Nhưng phần lớn comments là về pricing, license, deployment feasibility (V4-Pro 1.6T params không fit consumer GPU), và meme. Có lẽ vì community local LLM đang chờ Q4 quantization của V4-Flash để chạy local trước, và discussion sâu về architecture sẽ đến sau.
Một thread r/SillyTavernAI làm mình ấn tượng: cộng đồng tự fingerprint một stealth model trên OpenRouter tên "Hunter Alpha" mà nhiều người đoán là DeepSeek V4. Họ phát hiện nó không phải DeepSeek vì các signal subtle: DeepSeek native dịch "Chain of Thought" thành "深度思考", Hunter Alpha output "思维链" (generic). DeepSeek dùng full-width vertical bar tokens <|end of sentence|>, Hunter Alpha echo lại như text. Mainland Chinese model bị CAC regulation thường hard-block topics nhạy cảm; Hunter Alpha thảo luận tự do. Đây là community due-diligence hiếm thấy ở subreddit khác và thể hiện một mức độ hoài nghi lành mạnh.
Implications

Bài này dài rồi. Mình đóng bằng vài câu hỏi thay vì câu trả lời.
Câu hỏi #1: nếu efficiency curve thực sự dốc hơn capability curve, ai thắng cuộc đua AI hai năm tới? Là model frontier nhất, hay model có cost-per-million-token thấp nhất ở capability level "good enough"?
Câu hỏi #2: V3 đốt một narrative ("AI cần $billions GPU"). V4 đang đốt narrative thứ hai ("AI frontier cần Nvidia"). Cái thứ ba có thể sẽ là gì? Mình đoán "AI training cần US data centers" sẽ là next.
Câu hỏi #3: nếu Huawei Ascend run V4 thực sự competitive, Nvidia mất bao nhiêu phần trăm AI training market trong 24 tháng tới? Mình không biết. Cứ vài tháng câu trả lời lại thay đổi.
Mình sẽ deploy V4-Flash thử trong vài tuần tới cho một số agentic task có long context. Đây sẽ là test thật cho thesis của bài viết này. Nếu bạn cũng đang test V4 và có kinh nghiệm khác hoặc giống, mình muốn nghe.
Có thể tháng sau mình sẽ có thêm data. Có thể không. Cuộc đua này còn dài.

random 1 ảnh 8 năm về trước trong ký túc sinh viên Viết xong bài này cũng là lúc tôi xuất phát từ nhà ra sân bay ✈️. Cảm ơn vợ đã pack vali dùm :D
Bình