YOLOv12 deep dive tiếng Việt: Area Attention, R-ELAN giải thích
YOLOv12 paper deep dive tiếng Việt: Area Attention chia 4 dải, R-ELAN scaling 0.01, thí nghiệm bóc tách bất ngờ. Chạy được trên Jetson Orin Nano? Có.
Bài YOLOv8 deep dive tuần trước mình kết bằng câu "bài tiếp theo có thể là so sánh YOLOv12 vs v8". Tối qua mình mở paper v12 ra (arXiv 2502.12524, Tian et al., Feb 2025), đọc xong abstract thì hơi giật mình.
Câu mở đầu paper đại ý: từ trước tới giờ YOLO toàn cải tiến CNN, dù attention rõ ràng modeling tốt hơn. Lý do duy nhất YOLO không dùng attention là vì attention chậm. v12 fix chuyện đó.
Đây là một thesis can đảm. Vì 5 năm qua cả ngành đã thử đẩy ViT vào real-time detection (DETR, RT-DETR, RT-DETRv2) và kết quả luôn là một trade-off, accuracy lên một chút, latency lên gấp đôi. Giờ một paper từ University at Buffalo claim làm được cả hai: YOLOv12-S đánh bại RT-DETR-R18 về mAP và chạy nhanh hơn 42%, tốn 36% compute. Nếu đúng thì đây là milestone. Nếu sai hoặc cherry-pick, sẽ lộ ra khi mình đào kỹ.

Bài này là note đọc paper của mình, cùng style với bài v8. Giả định bạn đã đọc v8 hoặc biết tương đương: hiểu backbone/neck/head, biết DFL là gì, biết anchor-free predict 4 distance thay vì offset từ anchor. Nếu chưa, quay lại bài v8 đọc trước rồi qua đây.
Bốn version giữa v8 và v12: chuyện gì đã xảy ra
Trước khi vào v12, một bản đồ ngắn để bạn không lạc giữa rừng version. Từ v8 (2023) đến v12 (2025) có 4 version trung gian, mỗi cái đổi một thứ:
- YOLOv9 (2024, Wang et al.): giới thiệu GELAN (generalized ELAN) cho backbone và PGI (Programmable Gradient Information) để fix vấn đề thông tin gradient bị mất khi đi qua nhiều layer. Thiên về training side hơn architecture.
- YOLOv10 (2024, Tsinghua): NMS-free training với dual label assignment (one-to-many cho training, one-to-one cho inference). Bỏ được NMS nghĩa là pipeline end-to-end thật sự, latency ổn định hơn.
- YOLOv11 (2024, Ultralytics): thay C2f bằng C3K2 (một special case của GELAN), thêm depthwise separable conv ở head để giảm params. Iterative improvement, không có innovation nền tảng mới.
- YOLOv12 (2025): bài hôm nay. Chuyển sang attention-centric.

v12 lấy v11 làm baseline, thay đổi chủ yếu ở backbone/neck. Head, loss, label assignment vẫn giống v8/v11 (decoupled head, anchor-free, DFL, TaskAlignedAssigner, BCE). Nếu bạn đã đọc v8 thì 70% kiến trúc vẫn quen thuộc, chỉ 30% là mới, và 30% đó tập trung ở chỗ trộn feature.
Tại sao attention từng chậm: hai chỗ nghẽn
Attention chậm hơn CNN vì hai lý do độc lập:
- Mỗi pixel trong attention phải "nhìn" tất cả pixel khác trong ảnh, nếu ảnh có $L$ pixel thì số phép tính tăng theo $L^2$ (bình phương), trong khi CNN chỉ tăng tuyến tính theo $L$ vì cửa sổ $k \times k$ cố định nhỏ. Với ảnh 640×640, $L = 1600$, attention tốn gấp ~180 lần CNN.
- GPU có hai loại bộ nhớ, SRAM (nhỏ, cực nhanh) và HBM (lớn, chậm hơn 10 lần), và attention bắt data round-trip giữa hai bên nhiều lần, GPU dành phần lớn thời gian chờ data di chuyển.
FlashAttention fix nghẽn memory, Area Attention của YOLOv12 fix nghẽn $L^2$.
Bài v12 dành nguyên một section để analyze "tại sao attention chậm hơn CNN". Đây là phần đáng đọc kỹ vì nó frame toàn bộ design choice sau đó. Mình giải thích bằng ví dụ cụ thể, không kéo công thức ra ngay.
Nghẽn 1: số phép tính tăng theo bình phương kích thước ảnh. Để hiểu, hình dung attention làm gì khác convolution.
Convolution là một cửa sổ nhỏ (ví dụ 3×3) trượt trên ảnh. Mỗi vị trí, cửa sổ chỉ "nhìn" 9 pixel xung quanh. Tức là mỗi pixel chỉ giao tiếp với 9 hàng xóm gần nhất. Số phép tính tỉ lệ thuận với số pixel. Ảnh gấp đôi → tính gấp đôi.
Attention thì khác. Nó cho mỗi pixel "nhìn" tất cả pixel khác trong ảnh rồi quyết định pixel nào quan trọng để chú ý. Đó là điểm mạnh, model có thể bắt được quan hệ xa (object ở góc trên-trái với object ở góc dưới-phải), điều CNN làm khó. Nhưng đổi lại, nếu ảnh có $L$ pixel thì attention phải tính $L \times L$ cặp tương tác. Số phép tính tỉ lệ với bình phương $L$, không phải $L$.
Cụ thể với input 640×640 chia thành patch 16×16, ta có $L = 1600$ token (mỗi "token" là một patch nhỏ của ảnh). Convolution 3×3 trên đó tốn khoảng $9 \times 1600 = 14{,}400$ phép tính per channel. Attention tốn $1600 \times 1600 = 2{,}560{,}000$, gấp gần 180 lần. Khi ảnh to hơn (1280×1280), CNN tăng 4 lần, attention tăng 16 lần. Đây là bottleneck thứ nhất, gọi là "complexity bậc 2".
Nghẽn 2: data phải chạy lòng vòng giữa hai loại memory. Đây là phần ít người ngoài systems biết, nhưng quan trọng hơn cả nghẽn 1 trên thực tế.
GPU có hai loại bộ nhớ với tốc độ rất khác nhau. SRAM (cache trên-chip, gần các nhân tính toán) cực nhanh nhưng nhỏ, chỉ vài chục MB. HBM (RAM của GPU, ở xa) chậm hơn khoảng 10 lần nhưng dung lượng lớn, vài chục GB. Logic cơ bản: muốn tính nhanh, để data trong SRAM. Nhưng SRAM nhỏ nên phần lớn data nằm trong HBM, mỗi khi cần thì kéo vào SRAM.
Attention có một bảng trung gian gọi là attention map kích thước $L \times L$, với $L=1600$ thì bảng này khoảng 10 MB cho float32. Bảng này phải tạo, ghi vào HBM, sau đó đọc lại để áp softmax, rồi đọc lại lần nữa để nhân với value. Mỗi round trip HBM↔SRAM tốn thời gian gấp 10 lần so với compute thực tế. Kết quả: GPU dành phần lớn thời gian chờ data di chuyển, không phải tính toán.
CNN không bị vấn đề này. Vì cửa sổ 3×3 nhỏ và data quanh đó được cache ngay khi đọc một lần, mọi tính toán cho pixel xung quanh dùng lại data đã nằm trong SRAM. Không có round trip lớn.

Hai nghẽn này độc lập. Bạn có thể fix một mà không fix cái kia, và đến giờ phần lớn các paper "efficient transformer" chỉ fix được một bên. FlashAttention (Dao et al., 2022 và 2023) fix nghẽn 2 bằng cách reorganize compute để giữ data trong SRAM lâu nhất có thể. Một loạt paper về local/sparse/linear attention (Swin, axial, criss-cross, Linformer) fix nghẽn 1 bằng cách giảm $L^2$ xuống thấp hơn.
YOLOv12 fix cả hai. FlashAttention dùng nguyên xi từ paper gốc, không sửa. Nghẽn complexity thì v12 đề xuất một thứ mới gọi là Area Attention.
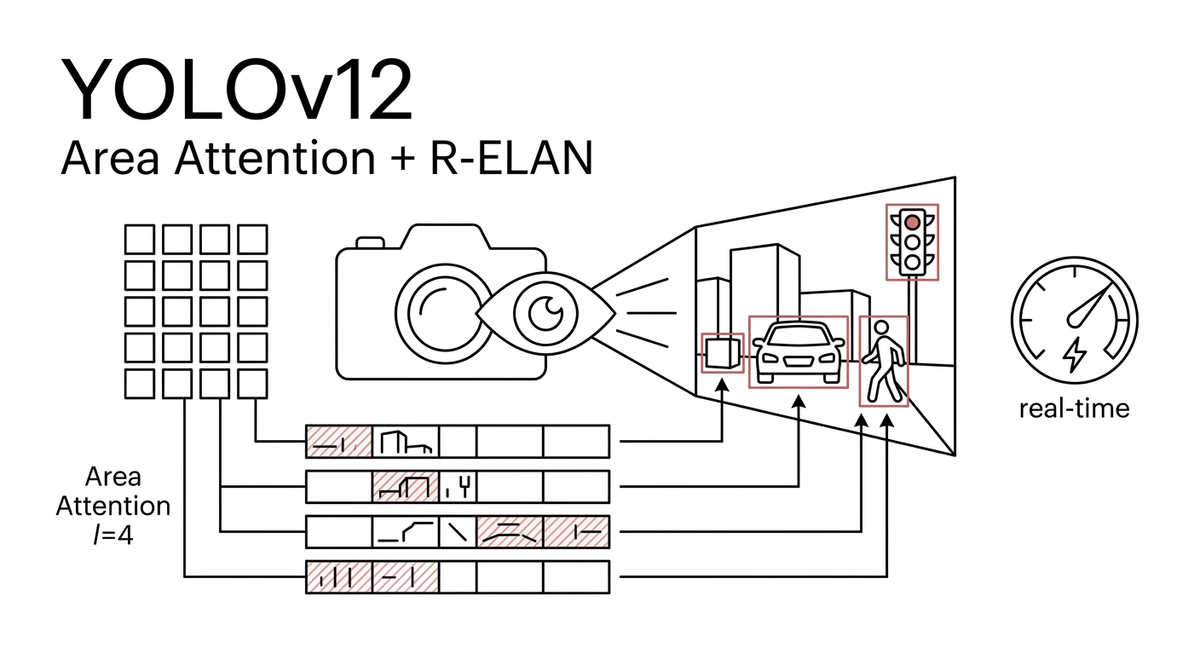
Area Attention: split feature map thành 4 dải, hết
Area Attention chia feature map $(H, W)$ thành $l=4$ dải bằng một tensor.reshape() duy nhất, không có window partition phức tạp như Swin. Complexity giảm từ $2n^2hd$ xuống $\frac{1}{2}n^2hd$, receptive field còn $\frac{1}{4}$ original nhưng vẫn đủ cho object detection ở 640×640.
Đây là innovation chính của v12 và cũng là phần đỉnh nhất.
Giả sử bạn có feature map kích thước $(H, W)$, sau khi patchify thành $n = HW$ token. Vanilla attention tính attention matrix $n \times n$, complexity $2n^2 hd$ với $h$ heads, $d$ head size. Quá đắt khi $n$ lớn.
Các paper trước cố giảm bằng cách chia feature map thành windows. Swin Transformer chia thành ô vuông không chồng lấp rồi shift mỗi layer. Criss-cross attention chỉ attend trong horizontal hoặc vertical line. Axial attention attend dọc rồi attend ngang. Đều cùng ý tưởng: chia ra cho attention chỉ chạy trong sub-region, complexity giảm.
Vấn đề là việc "chia ra" này tự nó tốn compute và memory access. Window partition + reverse trong Swin có overhead riêng. Receptive field bị giới hạn trong window nên cần shift mỗi layer để inter-window communication có cơ hội xảy ra. Càng phức tạp càng chậm.

Area Attention làm chuyện đơn giản đến mức gần như "ngây thơ". Lấy feature map $(H, W)$, chia equal thành $l$ dải theo chiều dọc hoặc ngang. Default $l = 4$. Nghĩa là từ một feature map $(H, W)$ bạn được 4 cái $(H/4, W)$ hoặc 4 cái $(H, W/4)$. Mỗi dải chạy attention độc lập.

Cái khéo nằm ở chỗ implementation. Để chia thế này không cần window partition function phức tạp như Swin, chỉ cần một tensor.reshape(). Reshape không tốn compute, nó chỉ đổi cách interpret memory layout. Nghĩa là chuyện chia feature gần như free về cost.
Math: complexity giảm từ $2n^2 hd$ (vanilla) xuống $\frac{1}{2} n^2 hd$ (area, $l=4$). Vẫn là $n^2$, nhưng hệ số nhân giảm 4 lần. Receptive field còn $\frac{1}{4}$ original (mỗi dải chỉ thấy được $\frac{H}{4} \cdot W$ pixel), nhưng paper claim receptive field này vẫn đủ lớn cho object detection ở 640×640.
Một câu hỏi ngay khi đọc: tại sao $l = 4$? Tại sao không 8, không 16? Paper không ablate cụ thể $l$, chỉ nói "empirically chọn 4". Mình đoán logic là 4 vừa đủ giảm compute mà receptive field vẫn cover được majority object size trong COCO. Nếu $l$ quá lớn thì object lớn bị cắt thành nhiều dải, attention không thấy được toàn bộ object.
Một điểm thú vị từ bảng bóc tách 7c: bật area attention thực ra giảm mAP 0.2 (40.8 → 40.6) nhưng tăng tốc đáng kể (1.70 → 1.64ms). Tức là area attention không phải miễn phí, bạn trade một chút accuracy lấy speed. Trade-off này chấp nhận được vì lợi về speed lớn hơn nhiều, và compose với các improvement khác thì vẫn vượt xa baseline.
R-ELAN: vì sao ELAN gốc fail khi train model lớn
R-ELAN (Residual ELAN) là refinement của ELAN từ YOLOv7, thêm residual shortcut với scaling factor 0.01 và redesign aggregation thành bottleneck. Mục đích: fix optimization fail khi scale lên L/X với attention, ELAN gốc không có residual path từ input ra output, gradient không flow đẹp qua attention stack sâu.
Tới đây nếu bạn nghĩ "chỉ thay attention block, mọi thứ chạy ngon" thì mình đã nghĩ vậy lúc đọc lần đầu. Sai. Khi tác giả thử train YOLOv12 ở scale L và X với area attention, model không converge. Cả với SGD lẫn AdamW.
Đây là vấn đề optimization, không phải vấn đề expressivity. Model có khả năng học, nhưng gradient không flow đẹp qua attention stack sâu, training instability bùng lên ở scale lớn.
Để hiểu fix của paper, cần quay lại ELAN là gì trước đã.
ELAN (Efficient Layer Aggregation Network) là một cách tổ chức một cụm conv block, được giới thiệu trong YOLOv7 (2022). Vấn đề mà ELAN giải: nếu bạn xếp chồng 5-10 conv block liên tiếp (input → block1 → block2 → ... → output), gradient phải đi qua hết mọi block khi backprop, dễ bị vanish ở model sâu. Đồng thời, output cuối chỉ phản ánh feature của block cuối, các feature trung gian học được ở giữa bị bỏ.
ELAN fix bằng một thiết kế khá đặc thù: input đi qua một transition conv 1×1 (chỉ để adjust số channel cho phù hợp), rồi feature được chia làm 2 chunk theo channel. Chunk 1 giữ nguyên (shortcut). Chunk 2 đi qua chuỗi $N$ block (thường $N=3$). Sau khi qua xong, mọi output trung gian của chunk 2 (output sau block 1, sau block 2, sau block 3) được giữ lại. Cuối cùng concat tất cả lại, chunk 1 + 3 output trung gian, rồi đi qua một transition conv 1×1 nữa để ra output cuối.
Lợi ích: layer cuối có quyền truy cập feature ở mọi độ sâu (shallow chunk + intermediate + deep), tự chọn weighted combination tốt nhất. Gradient cũng có nhiều con đường ngắn để backprop về (qua chunk 1 shortcut). Đây là idea mà C2f trong YOLOv8 và C3K2 trong YOLOv11 đều mượn, chỉ khác chi tiết số block và cách concat.

Vấn đề ELAN ở scale lớn: không có residual path từ input ra output. Gradient phải chui qua hết các block trung gian. Với CNN block thì OK vì mỗi conv là well-conditioned. Với attention block thì attention matrix có thể có condition number xấu, gradient explode hoặc vanish.
R-ELAN (Residual ELAN) fix bằng hai thay đổi:
1. Residual shortcut với scaling factor. Thêm một skip connection từ input của block ra output, nhân với scaling factor (default 0.01). Ý tưởng giống layer scaling trong các deep ViT (Touvron et al., 2021). Scaling 0.01 nghĩa là output ban đầu gần như chỉ là transformed feature, nhưng gradient có một con đường tắt thẳng từ output về input mà không qua attention. Khi train ổn định hơn rồi, scaling factor có thể được model học để adjust nếu cần.
Ablation table 2 cho thấy scaling rất quan trọng: với YOLOv12-X, scaling 0.1 không converge, scaling 0.01 converge. Một con số nhỏ vô lý nhưng đó là chìa khoá.

Một finding ngoài lề thú vị: với YOLOv12-N (model nhỏ), residual không cần thiết. N converge ngon kể cả với ELAN gốc, và thêm residual còn làm mAP giảm nhẹ. Tức là R-ELAN là solution cho problem chỉ tồn tại ở scale lớn. Paper vẫn dùng R-ELAN cho mọi scale để consistent, nhưng nếu bạn quan tâm tối ưu N variant thì có thể bỏ residual.
2. Aggregation mới kiểu bottleneck. Thay vì split input thành 2 chunk rồi concat lại sau, R-ELAN đi qua transition conv ra một feature map duy nhất, đi qua chuỗi block, rồi concat tất cả intermediate output. Cấu trúc thành bottleneck (channel hẹp ở giữa, rộng ở hai đầu), giảm cả compute lẫn memory.
Cá nhân mình thấy thiết kế này ngược tinh thần ELAN gốc một chút. ELAN cố giữ được gradient redundancy bằng việc split input. R-ELAN bỏ split, dùng residual shortcut thay thế. Hai cách reach cùng mục tiêu (gradient flow đẹp) nhưng qua hai con đường khác nhau, và R-ELAN parameter-efficient hơn.
Sáu điều chỉnh nhỏ làm attention "vừa với YOLO"
Ngoài area attention và R-ELAN, paper liệt kê 6 micro-tweak để attention compatible với tinh thần real-time. Mỗi cái nhỏ nhưng cộng lại tạo ra speedup đáng kể. Mình đi nhanh:
FlashAttention. Bật mặc định. Ablation table 7g: speedup ~0.3ms cho N, ~0.4ms cho S. Cost = một dependency cứng vào GPU support. Đây là cái limitation lớn nhất của v12, mình sẽ nói kỹ ở section cuối.
Bỏ positional encoding. Mọi attention-based model truyền thống có hoặc absolute positional encoding (APE) hoặc relative (RPE). v12 thử cả ba: APE, RPE, và không có gì. Kết quả bóc tách 7d: không có gì cho mAP cao nhất (40.6 vs 40.5 APE, 40.3 RPE) và latency thấp nhất. Bỏ position encoding cho clean architecture và nhanh hơn, bonus thay vì trade-off.
Lý do v12 có thể bỏ positional encoding: vì area attention chỉ chạy trong một dải $(H/4, W)$, vị trí tương đối trong dải được ngầm encode bởi memory layout. Cộng thêm position perceiver (tiếp dưới) giúp model perceive vị trí qua một con đường khác.
Position Perceiver (large kernel separable conv). Thêm một depthwise separable convolution kernel 7×7 vào value tensor $v$. Output của conv này được cộng vào $v \cdot \text{attn}$. Conv smoothing tự nhiên preserve spatial structure, đóng vai trò như "soft positional bias" mà không cần explicit positional encoding.
Ablation table 7d: kernel 3×3 cho 40.4, 5×5 cho 40.4, 7×7 cho 40.6, 9×9 cho 40.7 (nhưng latency lên 1.79). Sweet spot ở 7×7. Idea này đã có trong PSA module của YOLOv10, v12 chỉ tăng kernel size.
MLP ratio 4 → 1.2. Trong vanilla ViT, MLP block sau attention có hidden dim gấp 4 lần input dim. Đây là default từ đầu của Transformer. v12 bóc tách bảng 7f cho YOLOv12-L: ratio 4.0 → 53.1 mAP, ratio 2.0 → 53.6, ratio 1.2 → 53.8. Latency gần như nhau. Tức là MLP đang lãng phí ở YOLO scale, model không cần feed-forward to thế.
Lý do: ViT gốc design cho ImageNet classification ở scale rất lớn (ViT-L có 300M params). Ở scale YOLO (2-60M params), MLP overcapacity. Giảm ratio xuống 1.2 chuyển compute budget từ MLP sang attention, và attention được dùng nhiều hơn nghĩa là area attention được leverage tốt hơn.
Đây là một cú đảo lầm tưởng đáng nhớ: nếu bạn copy một block ViT gốc vào YOLO mà không nghĩ lại, bạn đang waste khoảng 3 lần compute ở MLP để đổi 0.7 mAP. Số default từ paper khác không phải luôn tối ưu cho domain mới.
Conv + BN thay Linear + LN. Vanilla attention dùng nn.Linear với LayerNorm. v12 thay bằng nn.Conv2d 1×1 với BatchNorm. Linear và Conv 1×1 mathematically tương đương trên 4D tensor (chỉ khác cách reshape), nhưng implementation Conv2d trên CUDA tối ưu hơn. BN nhanh hơn LN ở inference vì stats được folding vào weight. Ablation table 7a: Conv+BN cho 40.6 vs Linear+LN cho 40.5, latency 1.64 vs 1.68.
Cũng xác nhận lại: dù LN thường better cho attention trong NLP, BN better cho attention trong CV khi dùng với Conv. Finding này đã có trong PSA của YOLOv10, v12 chỉ inherit.
Giảm depth ở stage cuối backbone. YOLOv8/v9/v10/v11 stack 3 block ở stage cuối backbone. v12 chỉ giữ 1 R-ELAN block. Ít block ở stage sâu giúp optimization dễ hơn (đây là chỗ attention dễ unstable nhất). Trade-off accuracy: paper claim không đáng kể vì 2 stage đầu (kế thừa từ v11 với C3K2 thường) đã extract feature đủ tốt.
YOLOv12 vs YOLOv11 vs YOLOv8: bảng so sánh mAP và latency
Đây là bảng so sánh chính từ paper (Table 1, COCO val, 640×640, T4 GPU TensorRT FP16):
| Model | FLOPs | Params | mAP | Latency |
|---|---|---|---|---|
| YOLOv8-N | 8.7G | 3.2M | 37.4 | 1.77ms |
| YOLOv10-N | 6.7G | 2.3M | 38.5 | 1.84ms |
| YOLOv11-N | 6.5G | 2.6M | 39.4 | 1.5ms |
| YOLOv12-N | 6.5G | 2.6M | 40.6 | 1.64ms |
| YOLOv8-S | 28.6G | 11.2M | 45.0 | 2.33ms |
| RT-DETR-R18 | 60.0G | 20.0M | 46.5 | 4.58ms |
| RT-DETRv2-R18 | 60.0G | 20.0M | 47.9 | 4.58ms |
| YOLOv11-S | 21.5G | 9.4M | 46.9 | 2.5ms |
| YOLOv12-S | 21.4G | 9.3M | 48.0 | 2.61ms |
| YOLOv8-X | 257.8G | 68.2M | 54.0 | 12.83ms |
| YOLOv11-X | 194.9G | 56.9M | 54.6 | 11.3ms |
| YOLOv12-X | 199.0G | 59.1M | 55.2 | 11.79ms |
So với v11 (cùng size): v12-N tăng 1.2 mAP với latency tăng 0.14ms. v12-S tăng 1.1 mAP với latency tăng 0.11ms. v12-X tăng 0.6 mAP với latency tăng 0.49ms. Tức là gain đẹp ở scale nhỏ và vừa, nhỏ dần ở scale lớn (dấu hiệu attention đã bão hoà).
So với RT-DETR-R18: v12-S đạt 48.0 mAP với 21.4G FLOPs trong 2.61ms. RT-DETR-R18 đạt 46.5 mAP với 60.0G FLOPs trong 4.58ms. Tức là v12-S tốt hơn 1.5 mAP, dùng 36% compute, 75% thời gian. Đây là cú đập mạnh vào thesis của RT-DETR ("transformer detector có thể real-time"). v12 nói: được, nhưng YOLO architecture với attention hợp lý vẫn nhanh và chính xác hơn pure transformer.

Heatmap visualization (figure 4 paper) thì subjective hơn nhưng đáng nhìn: ở X-scale, v12 activation tập trung sắc nét quanh object contour, ít nhiễu hơn v10/v11. Paper attribute việc này cho receptive field lớn hơn của area attention so với conv.
Năm finding bất ngờ từ thí nghiệm bóc tách YOLOv12
Đọc paper kiểu detective thì phần bóc tách thường có nhiều thông tin hơn phần main result. Vài điểm mình đánh dấu:
Hierarchical design vẫn cần thiết. Paper thử train v12 với plain ViT architecture (giống ViT-Det của Meta), kết quả: 38.3 mAP. So với 40.6 của hierarchical, mất 2.3 mAP. Bỏ stage 1 hoặc stage 4 mất 0.5-0.8 mAP. Tức là kể cả khi attention-centric, FPN-style multi-scale feature pyramid vẫn không thể bỏ. Đây là điểm khác biệt với detection field tổng quát, nơi ViT-Det chứng minh plain ViT đủ mạnh.

Scaling factor 0.01 không phải số magic. Mình đã hơi nghi ngờ con số 0.01 (sao không 0.005, 0.05?) nhưng bảng bóc tách 2 cho thấy: với YOLOv12-X, 0.1 không converge, 0.01 converge. Tức là 0.01 đủ nhỏ để gradient flow ổn định nhưng đủ lớn để feature learning có effect. Một sweet spot empirical, không có lý thuyết closed-form. Paper layer scaling gốc cũng vậy.
v12 train lâu hơn các version trước. v8/v9/v10 đạt peak ở ~500 epoch. v12 cần 600 epoch mới converge tốt. 800 epoch thì overfit nhẹ (40.4 < 40.6). Đây là cost ẩn của attention: optimization landscape phức tạp hơn, train lâu hơn. Nếu bạn fine-tune trên dataset nhỏ với ít epoch, v12 có thể không leverage hết potential. Cẩn thận khi compare v8 vs v12 ở custom dataset chưa train đủ epoch.
Augmentation vẫn như v8. Mosaic + HSV + flip + scale + translate. Mixup chỉ bật ở scale S+ (0.05/0.15/0.15/0.2). Copy-paste bật mạnh hơn (0.1 → 0.6 theo scale). Close mosaic 10 epoch cuối, giống v8.
Loss config y hệt v8. Box gain 7.5, class gain 0.5, DFL gain 1.5. CIoU + BCE + DFL. TaskAlignedAssigner. Không một thay đổi. Tức là từ v8 đến v12, đoạn từ feature pyramid output ra prediction về cơ bản đứng yên. Mọi đổi mới dồn vào backbone và neck.
Cá nhân mình thấy đây là một dấu hiệu mạnh rằng head + loss của v8 đã hit local optimum. 5 paper sau v8 không ai dám thay, vì thử thay thì degrade. DFL + TAL + decoupled head có vẻ là một trong những thiết kế bền nhất trong YOLO modern era.
YOLOv12 chạy được trên Jetson Orin Nano không? GPU dependency
Có. Jetson Orin Nano 8GB và Orin NX 8GB đều dùng kiến trúc Ampere (compute capability 8.7), support FlashAttention đầy đủ. YOLOv12-N expected ~3-4ms trên Orin Nano (vẫn real-time 30fps), v12-S ~5-6ms. Đừng nhầm với Jetson Nano cũ (2019, Maxwell), con đó không chạy được.
Đây là phần paper đặt cuối, một paragraph ngắn, nhưng quan trọng cho ai định deploy v12 trong production. v12 bắt buộc dùng FlashAttention. FlashAttention chỉ chạy được trên GPU kiến trúc Turing trở lên: T4, RTX 20-series, RTX 30-series, RTX 40-series, A100, H100, A5000/A6000.

Cụ thể không support: GTX 10-series và cũ hơn, K80 (Kepler), V100 (Volta, V100 có Tensor Core nhưng FlashAttention v1/v2 không support đầy đủ). Nhiều edge device như Jetson Nano (Maxwell), Jetson TX2 (Pascal) cũng không support.

Trên CPU thì sao? Paper có benchmark CPU và v12 vẫn nhanh hơn baseline, nhưng implementation cần fallback path khi không có FlashAttention, và mình chưa test code repo gốc xem fallback đó tốt thế nào. Nếu use case của bạn là edge inference trên CPU hoặc mobile NPU, v8/v11 vẫn safer bet.
Hệ quả thực tế cho hackathon hay project: nếu deploy lên Jetson Orin (Ampere, OK), Jetson Xavier (Volta, không OK, V100 thế hệ), hoặc desktop với RTX 30/40 series, v12 chạy ngon. Nếu deploy lên drone với Jetson Nano (Maxwell) hoặc on-device mobile, dừng lại check trước.
Một câu hỏi cụ thể mình đoán nhiều người trong hackathon UAV sẽ hỏi: Jetson Orin Nano 8GB và Orin NX 8GB có chạy được YOLOv12 không? Câu trả lời ngắn: cả hai đều chạy được. Hai con này cùng kiến trúc Ampere (compute capability 8.7, cùng 1024 CUDA cores + 32 Tensor Cores), cùng thế hệ với A100 và RTX 30-series, hoàn toàn support FlashAttention. Đừng nhầm "Orin Nano" với "Jetson Nano" cũ (2019, Maxwell), Jetson Nano không chạy được, Orin Nano và Orin NX (2023) chạy được. Khác biệt giữa Nano và NX nằm ở mức công suất và bandwidth: Orin Nano 8GB ~40 TOPS Sparse INT8, memory bandwidth 68 GB/s, TDP 7-15W, giá thị trường VN ~7-8 triệu cho module; Orin NX 8GB ~70 TOPS (gấp 1.7-2x), bandwidth 102 GB/s (gấp 1.5x), TDP 10-20W, giá ~12-15 triệu, gần gấp đôi.
Với YOLOv12, paper benchmark trên T4 (~8 TFLOPs FP16). Orin Nano 8GB chậm hơn T4 khoảng 1.5-2x, nên v12-N expected ~3-4ms, v12-S ~5-6ms, vẫn dư real-time 30fps. v12-M cần TensorRT FP16 + batch 1 mới giữ được latency thấp, v12-L/X không khuyến khích vì memory shared 8GB (sau OS chỉ còn ~5-6GB) và compute không đủ. Orin NX 8GB cho headroom đáng kể hơn: v12-N/S thoải mái multi-stream, v12-M single-stream real-time với TensorRT FP16, v12-L fit được với latency ~15-20ms (~50 fps, vẫn OK cho drone). Bandwidth gấp 1.5x đặc biệt đáng kể vì attention là memory-bound nhiều hơn compute-bound, model lớn ít bị nghẽn ở memory transfer hơn. Quy tắc chọn nhanh: chỉ cần 1 model detection ~30fps thì Orin Nano 8GB đủ, tiết kiệm tiền; nếu cần multi-task (detection + tracking + segmentation), multi-stream nhiều camera, hoặc muốn mở đường lên v12-L sau này thì đầu tư Orin NX 8GB. Nếu cần thêm headroom trên cả hai, TensorRT INT8 quantization sẽ giúp đáng kể vì Ampere có hardware INT8 Tensor Core dedicated.
FAQ, vài câu hỏi để tóm lại vấn đề:
YOLOv12 có gì khác YOLOv11?
Khác chính ở backbone/neck. v11 dùng C3K2 (CNN thuần), v12 chuyển sang attention-centric với Area Attention + R-ELAN. Head, loss, label assignment giống hệt nhau (decoupled head, anchor-free, DFL, TaskAlignedAssigner, BCE). v12 tăng 1-1.2 mAP so với v11 ở mọi scale, latency tăng nhẹ ~0.1-0.5ms. Switch v11 → v12 là replace ~30% architecture, không phải rewrite từ đầu.
Area Attention là gì?
Là cơ chế attention mới của YOLOv12. Thay vì cho mọi pixel attend tới mọi pixel khác (vanilla attention, complexity $L^2$), Area Attention chia feature map thành 4 dải bằng một tensor.reshape(), mỗi dải chỉ self-attend nội bộ. Complexity giảm 4 lần so với vanilla, không có overhead window partition như Swin Transformer. Trade-off: receptive field còn $\frac{1}{4}$, nhưng paper claim đủ cho object detection 640×640.
R-ELAN khác ELAN cũ thế nào?
R-ELAN thêm 2 thứ vào ELAN gốc của YOLOv7. Một, residual shortcut từ input ra output với scaling factor 0.01, fix optimization fail khi scale model lên L/X (ELAN gốc training không converge với attention). Hai, redesign aggregation thành bottleneck (channel hẹp ở giữa) thay vì split-then-concat của ELAN, tiết kiệm compute và memory. Với model nhỏ (N), R-ELAN không cần thiết, ELAN gốc vẫn converge.
YOLOv12 có chạy được trên Jetson Orin Nano không?
Có. Cả Orin Nano 8GB và Orin NX 8GB đều dùng Ampere (compute capability 8.7), support FlashAttention đầy đủ. v12-N expected ~3-4ms (real-time 30fps), v12-S ~5-6ms. Cảnh báo: đừng nhầm với Jetson Nano cũ (2019, Maxwell architecture), con đó không chạy được vì FlashAttention yêu cầu Turing trở lên.
YOLOv12 có bắt buộc dùng FlashAttention không?
Có, theo code repo gốc. FlashAttention là dependency cứng, không phải optional. Hệ quả: GPU phải là Turing (T4, RTX 20-series) trở lên. Không support: GTX 10-series, V100 (Volta), Jetson Nano cũ, Jetson TX2. Trên CPU có fallback path nhưng hiệu năng kém. Nếu deployment edge device không có FlashAttention-compatible GPU, v8/v11 vẫn safer bet.
YOLOv12 size nào nên dùng?
N (40.6 mAP, 1.64ms) cho edge device, mobile, real-time strict. S (48.0 mAP, 2.61ms) là sweet spot cho hầu hết case server/desktop. M (52.5 mAP, 4.86ms) khi cần accuracy hơn. L/X (53.7-55.2 mAP) chỉ khi không quan tâm latency. Rule of thumb: bắt đầu với S, scale lên/xuống tuỳ accuracy gap với requirement.
YOLOv12 train bao nhiêu epoch?
600 epoch (theo paper). Lâu hơn các version trước (v8/v9/v10 thường 500). 800 epoch overfit nhẹ. Lý do v12 cần lâu hơn: attention có optimization landscape phức tạp hơn CNN. Nếu fine-tune trên custom dataset nhỏ với ít epoch, v12 có thể không leverage hết potential, cẩn thận khi compare v8 vs v12 ở dataset chưa train đủ epoch.
YOLOv12 có vượt RT-DETR không?
Có, ở mọi scale. v12-S đạt 48.0 mAP với 21.4G FLOPs trong 2.61ms, trong khi RT-DETR-R18 đạt 46.5 mAP với 60.0G FLOPs trong 4.58ms. Tức là v12-S tốt hơn 1.5 mAP, dùng 36% compute, 75% thời gian. v12-X cũng vượt RT-DETR-R101 với 23% ít FLOPs hơn. v12 cho thấy YOLO architecture với attention hợp lý vẫn nhanh và chính xác hơn pure transformer detector.
Vài thứ để mang theo
YOLOv12 không phải composition của paper khác như v8 từng là. Area attention là idea mới. R-ELAN là refinement có chủ đích cho problem rất specific. Cộng với việc lần đầu tiên một YOLO chính thống dùng attention làm trung tâm và vẫn match latency CNN, v12 là step jump rõ ràng hơn các iterative improvement của v9/v10/v11.
Nhưng đồng thời v12 cũng kế thừa nhiều: backbone 2 stage đầu lấy nguyên từ v11 (C3K2 blocks), head + loss + assignment giống v8. Ultralytics framework, training recipe, augmentation config gần như y hệt. Nếu bạn đã có v8 hay v11 pipeline, switch sang v12 là replace 30% architecture chứ không phải rewrite from scratch.
Quay lại UAV Hackathon. Sau khi đọc xong paper, mental model của mình giờ là: v8 vẫn là baseline tốt cho prototype, train nhanh, ít rủi ro. v11 nếu muốn gain nhẹ với cùng deployment story. v12 nếu deployment chắc chắn có FlashAttention-compatible GPU và bạn muốn thêm 1-2 mAP. RT-DETR thì sau bài này mình ít quan tâm hơn, v12-S đã chứng minh YOLO architecture với attention hợp lý vẫn vượt RT-DETR ở mọi metric.
Bài tiếp theo có thể là benchmark thực tế trên dataset drone (small object detection ở altitude khác nhau), so sánh v8m, v11m, v12m trên cùng config training. Hoặc một bài về RT-DETR architecture để xem nó thật sự có ưu điểm gì so với YOLO không, hay chỉ là nhánh transformer detection rồi sẽ bị YOLO attention-centric hấp thụ. Sẽ thấy sau khi mình chạy thử.
Nếu bạn cũng đang đọc v12 và thấy mình đoán sai chỗ nào (đặc biệt phần area attention với receptive field, mình chưa hoàn toàn tin con số $\frac{1}{4}$ là đủ cho object lớn), mình muốn nghe.

Bài được viết ở một quán cafe ở quê mình, mọi người nghỉ lễ vui vẻ nhé
Bình.