Voice/Unvoiced/Silent Classification in Speech Processing: Algorithms and Implementation
Giải thích và implement lại một thuật toán phân loại âm thanh theo phương pháp xử lý tín hiệu số

Tóm tắt
Bài viết này trình bày phân tích về các kỹ thuật phân loại voiced/unvoiced/silent trong xử lý tiếng nói. Chúng tôi xem xét việc triển khai các phương pháp trích xuất đặc trưng âm thanh và phân loại để phân biệt giữa các đoạn:
- Hữu thanh (voiced)
- Vô thanh (unvoiced)
- Im lặng (silent)
trong tín hiệu tiếng nói. Việc triển khai trích xuất các đặc trưng:
- Zero-Crossing Rate (ZCR)
- Short-Time Energy (STE)
- Autocorrelation
Để thực hiện phân loại. Triển khai bằng Python của chúng tôi xử lý âm thanh theo khung, trích xuất các đặc trưng chính này và phân loại các đoạn dựa trên các ngưỡng, cung cấp cả kết quả phân loại và trực quan hóa.
Giới thiệu
Việc phân loại các đoạn tiếng nói thành hữu thanh (ví dụ: nguyên âm), vô thanh (ví dụ: phụ âm ma sát như 's', 'f') và các vùng im lặng là một nhiệm vụ cơ bản trong xử lý tiếng nói. Phân loại này đóng vai trò như một bước tiền xử lý quan trọng cho nhiều ứng dụng tiếng nói, bao gồm nhận dạng tiếng nói, nhận dạng người nói, nâng cao chất lượng tiếng nói và mã hóa tiếng nói.
Âm thanh hữu thanh được tạo ra khi dây thanh rung động, tạo ra dạng sóng chuẩn chu kỳ với năng lượng đáng kể ở tần số thấp. Âm thanh vô thanh hình thành từ luồng không khí nhiễu động mà không có rung động của dây thanh, tạo ra tín hiệu không theo chu kỳ, giống như tiếng ồn với năng lượng tập trung ở tần số cao hơn. Các vùng im lặng chỉ chứa tiếng ồn nền với năng lượng tối thiểu.
Triển khai của chúng tôi tập trung vào phương pháp dựa trên ngưỡng để phân loại voiced/unvoiced/silent, xử lý các tệp âm thanh theo từng khung và trích xuất các đặc trưng miền thời gian để phân loại.
Phân tích Âm thanh cho Phân loại Voiced/Unvoiced/Silent
Xử lý theo Khung
Trong quá trình triển khai của chúng tôi, âm thanh được xử lý trong các khung ngắn, chồng chéo:
$$x_n[m] = y[n+m] \cdot w[m], \quad 0 \leq m < M$$
trong đó:
- \(x_n[m]\) là khung thứ $n$ có độ dài $M$
- \(y[n]\) là tín hiệu âm thanh
- \(w[m]\) là hàm cửa sổ (cửa sổ Hamming)
- \(n\) tăng theo bước nhảy \(S\)
Cửa sổ Hamming được định nghĩa là:
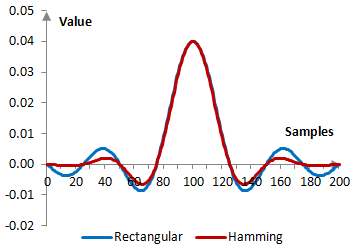
$$w[m] = 0.54 - 0.46 \cos\left(\frac{2\pi m}{M-1}\right), \quad 0 \leq m < M$$
Triển khai của chúng tôi sử dụng:
- Độ dài khung: 25 ms
- Bước nhảy khung: 10 ms
Đặc trưng Miền thời gian
Zero-Crossing Rate (ZCR)
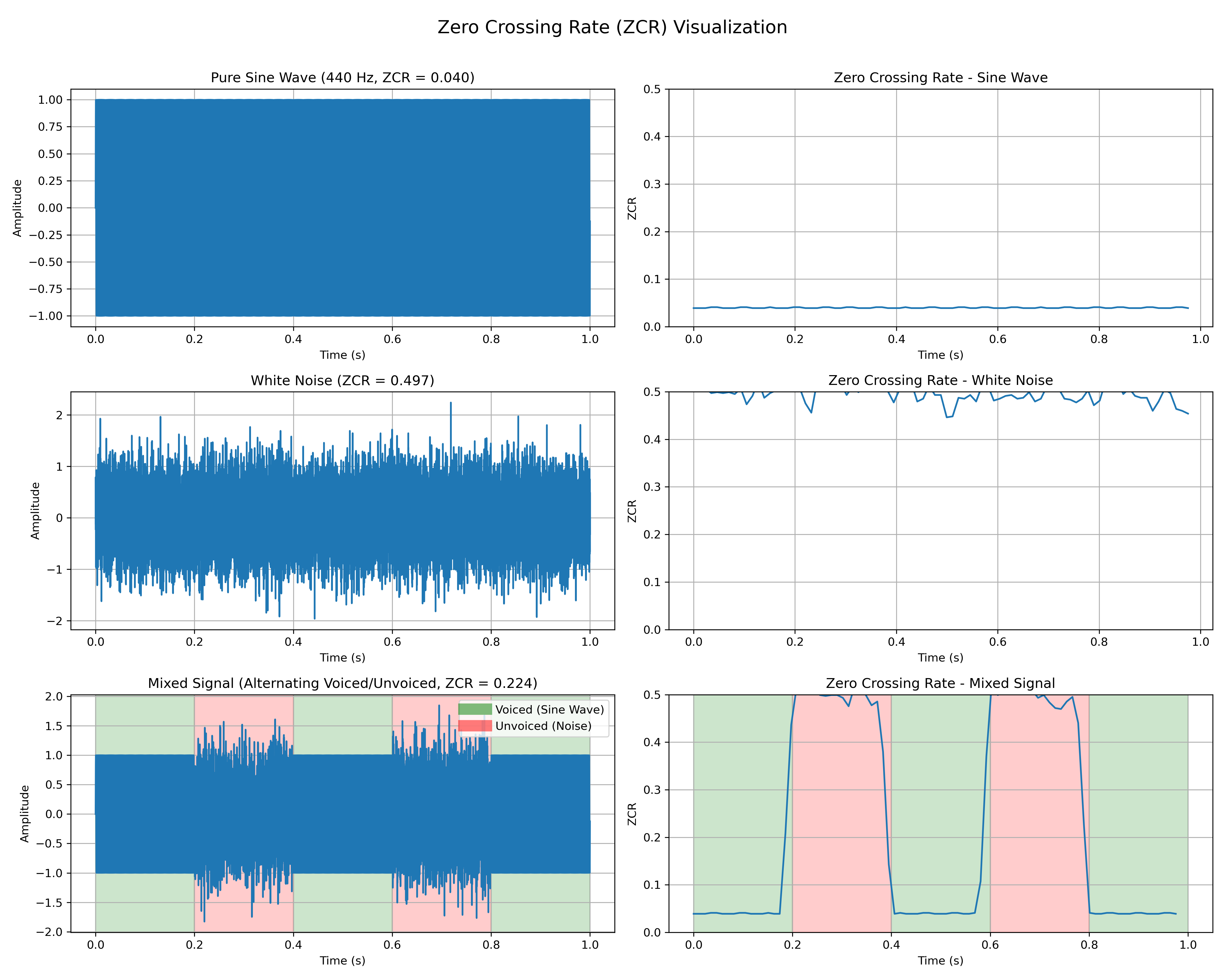
ZCR đo tốc độ mà tín hiệu thay đổi từ dương sang âm hoặc ngược lại:
\[\text{ZCR}_n = \frac{1}{2(M-1)} \sum_{m=1}^{M-1} |\text{sgn}(x_n[m]) - \text{sgn}(x_n[m-1])|\]
trong đó:
$$\text{sgn}(x) = \begin{cases} 1, & \text{if}\ x \geq 0\ -1, & \text{if}\ x < 0 \end{cases}$$
Âm thanh vô thanh thường có ZCR cao hơn âm thanh hữu thanh do đặc tính giống tiếng ồn của chúng.
Short-Time Energy (STE)
STE đo năng lượng hoặc cường độ của tín hiệu trong một khung:
\[\text{STE}_n = \frac{1}{M} \sum_{m=0}^{M-1} |x_n[m]|^2\]
Các đoạn hữu thanh thường có năng lượng cao hơn so với các đoạn vô thanh, trong khi các đoạn im lặng có năng lượng tối thiểu.
Hệ số tự tương quan (Autocorrelation coefficient)
Auto-correlation là quá trình so sánh một tín hiệu với chính nó nhưng ở các thời điểm khác nhau (dịch qua trái hoặc phải). Mục tiêu là để xem mẫu tín hiệu lặp lại như thế nào theo thời gian.
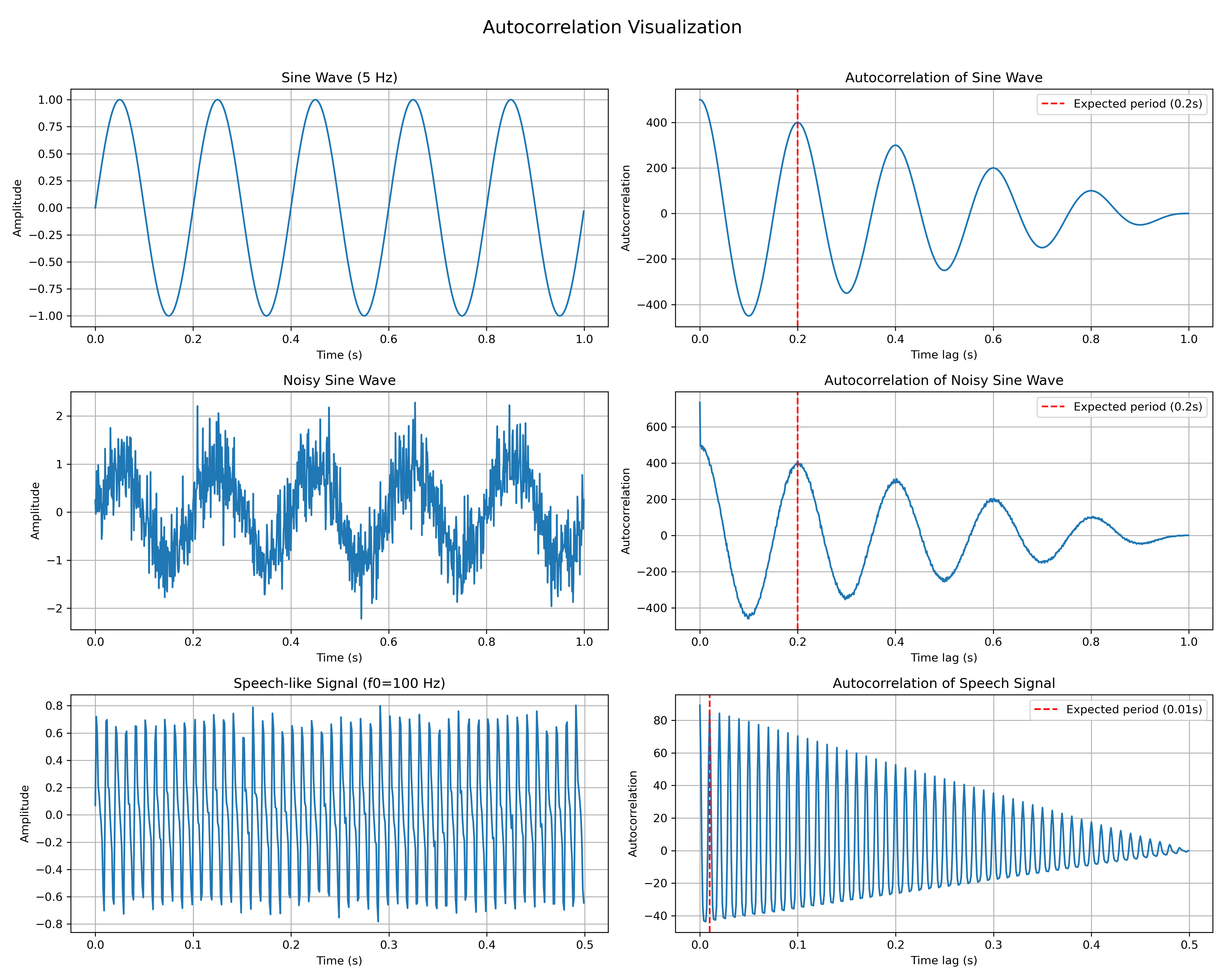
Để phát hiện pitch và phân tích tính chu kỳ, tự tương quan của một khung ở độ trễ \(k\) được định nghĩa là:
\[R_n[k] = \sum_{m=k}^{M-1} x_n[m] \cdot x_n[m-k], \quad k = 0, 1, \dots, M-1\]
Autocorrelation được chuẩn hóa là:
\[\hat{R}n[k] = \frac{R_n[k]}{R_n[0]} = \frac{\sum{m=k}^{M-1} x_n[m] \cdot x_n[m-k]}{\sum_{m=0}^{M-1} x_n[m]^2}, \quad k = 0, 1, \dots, M-1\]
Một đỉnh cao trong \(\hat{R}_n[k]\) cho \(k > 0\) chỉ ra tính chu kỳ, một đặc điểm của âm thanh hữu thanh.
Thuật toán Phân loại
Phân loại dựa trên Ngưỡng
Triển khai của chúng tôi sử dụng phương pháp đơn giản nhưng hiệu quả kết hợp thông tin ZCR, STE và pitch:
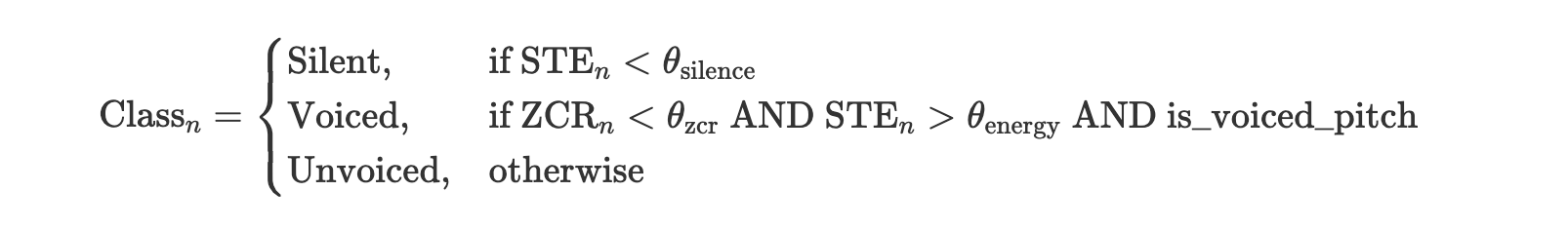
trong đó \(\theta_{\text{silence}}\), \(\theta_{\text{zcr}}\) và \(\theta_{\text{energy}}\) là các ngưỡng được xác định theo kinh nghiệm.
Tham số is_voiced_pitch được xác định từ giá trị đỉnh tự tương quan, với ngưỡng là 0.3.
Chi tiết Triển khai
Triển khai của chúng tôi bao gồm các thành phần sau:
- VoiceClassifier: Lớp cốt lõi triển khai việc trích xuất khung, tính toán đặc trưng (ZCR, STE, tự tương quan) và phân loại
- AudioFileHandler: Xử lý việc tải các tệp âm thanh (MP3, WAV) và lưu các đoạn đã phân loại
- AudioVisualizer: Tạo trực quan hóa tín hiệu âm thanh, đặc trưng và kết quả phân loại
- VoiceDownloader: Tải xuống các mẫu giọng nói sử dụng Google Text-to-Speech (gTTS)
Lựa chọn Tham số
Giá trị tham số trong triển khai của chúng tôi được thiết lập như sau:
- Ngưỡng ZCR: 0.1 (ZCR chuẩn hóa)
- Ngưỡng năng lượng: 0.0001 (năng lượng chuẩn hóa)
- Ngưỡng im lặng: 0.00001 (năng lượng chuẩn hóa)
- Phạm vi phát hiện pitch: 50-500 Hz
- Ngưỡng đỉnh tự tương quan: 0.3
Các tham số này được chọn dựa trên thử nghiệm thực tế và phù hợp với các giá trị thông thường được sử dụng trong tài liệu xử lý tiếng nói.
Kết luận
Triển khai của chúng tôi thể hiện một phương pháp thực tế để phân loại voiced/unvoiced/silent sử dụng các phương pháp dựa trên ngưỡng. Bằng cách trích xuất và phân tích các đặc trưng ZCR, STE và tự tương quan từ các khung âm thanh, chúng tôi có thể phân loại hiệu quả các đoạn tiếng nói thành các vùng hữu thanh, vô thanh và im lặng.
Triển khai này tạo ra các trực quan hóa thể hiện các đặc trưng đã trích xuất và kết quả phân loại, cũng như các tệp âm thanh tách biệt cho mỗi lớp đoạn tiếng nói. Công cụ này có thể hữu ích cho nhiều ứng dụng xử lý tiếng nói, bao gồm phân tích tiếng nói, nhận dạng và tổng hợp.
Phụ lục
Phát hiện Pitch và Quyết định Voiced/Unvoiced
Tham số is_voiced_pitch được sử dụng trong thuật toán phân loại của chúng tôi được xác định thông qua phân tích tự tương quan:
# Define the human vocal frequency range
min_pitch = 50 # Hz (lowest frequency)
max_pitch = 500 # Hz (highest frequency)
# Convert frequencies to lags
min_lag = int(sr / max_pitch)
max_lag = int(sr / min_pitch)
# Find the highest peak in this range
peak_idx = np.argmax(autocorr[min_lag:max_lag]) + min_lag
peak_value = autocorr[peak_idx]
# Determine if the frame is voiced based on peak value
is_voiced = peak_value > 0.3 # Threshold of 0.3
Phương pháp này dựa trên các nguyên tắc sau:
- Âm thanh hữu thanh tạo ra dạng sóng theo chu kỳ, dẫn đến các đỉnh tự tương quan mạnh
- Vị trí của đỉnh chỉ ra chu kỳ cơ bản (và do đó là pitch)
- Nếu đỉnh tự tương quan chuẩn hóa vượt quá ngưỡng (0.3), khung được phân loại là hữu thanh
- Ngưỡng này được xác định qua thực nghiệm để phân biệt giữa tín hiệu có chu kỳ (hữu thanh) và không có chu kỳ (vô thanh)
Pitch sau đó được tính từ vị trí đỉnh: pitch = sampling_rate / peak_index (đối với các khung hữu thanh).
Kết quả
*Note: đây là bài tập trong trương trình học sau đại học của tôi.
Many thanks to Teamates: chị Phương, Dũng Trương.