Nhận diện khuôn mặt từ A đến Á

Dự án nhận diện khuôn mặt đầu tiên của tôi đã được triển khai hồi năm 2019, loanh quanh một hồi thì trong khi đang học thạc sĩ tôi lại có một cơ hội để ôn lại về chủ đề này. Ngày hôm nay, bài viết này giống như một cuộc trò chuyện dài, nơi mình chia sẻ mọi thứ từ gốc rễ lý thuyết cho đến cách triển khai một pipeline điểm danh hoàn chỉnh. Nếu bạn kiên nhẫn đọc đến cuối, đảm bảo bạn sẽ nắm được đầy đủ kiến thức để tự mình thử nghiệm.
Nhận diện khuôn mặt không phải là một ý tưởng mới mẻ. Từ những năm 1960, các nhà khoa học đã tìm cách phân tích tỉ lệ khuôn mặt để nhận dạng người trong ảnh. Song phải đến khi deep learning bùng nổ, công nghệ này mới thực sự cất cánh. Ngày nay, chúng ta có thể xây dựng hệ thống nhận diện với độ chính xác cao chỉ bằng một chiếc GPU phổ thông. Sự phổ biến của camera và dữ liệu lớn cũng góp phần thúc đẩy quá trình này.
1. Mở Đầu: Nhận Diện Khuôn Mặt Có Gì Hay?
Nhận diện khuôn mặt (Face Recognition) không chỉ là trào lưu công nghệ. Nó đóng vai trò quan trọng trong nhiều lĩnh vực: an ninh, thanh toán, điểm danh tự động, cho đến các ứng dụng mang tính cá nhân như mở khóa điện thoại. Mình từng hỗ trợ triển khai hệ thống check-in bằng khuôn mặt cho một công ty quy mô tầm 1000 nhân sự. Trước khi hệ thống vận hành, mọi người phải quét thẻ từ thủ công khá bất tiện. Sau khi có nhận diện khuôn mặt, việc điểm danh trở nên nhanh chóng, gần như không còn hàng chờ.
Khi mới tìm hiểu, nhiều người hay nhầm lẫn hai khái niệm: Face Verification và Face Identification. Verification nghĩa là trả lời câu hỏi "Đây có phải người A không?" - tương tự khi bạn mở khóa điện thoại. Identification lại rộng hơn: "Người này là ai trong N người?". Trong dự án điểm danh, ta cần giải quyết bài toán Identification vì phải tìm ra đúng nhân viên trong danh sách lớn.
Ngoài điểm danh, mình còn từng ứng dụng nhận diện khuôn mặt cho hệ thống quản lý phòng gym. Việc tự động nhận dạng giúp nhân viên tiếp tân không phải kiểm tra thẻ thủ công, tiết kiệm thời gian vào giờ cao điểm. Khách hàng cũng cảm thấy chuyên nghiệp hơn. Từ kinh nghiệm này, mình nhận ra rằng tính năng nhận diện chỉ thực sự phát huy tác dụng khi được tích hợp khéo léo vào quy trình hiện có, thay vì áp đặt cứng nhắc.

Hôm nay ta chỉ bàn về việc face recognization nên việc detect ra khuôn mặt ta sẽ kể ở một buổi khác nhé
2. Nền Tảng Lý Thuyết
2.1 One-shot Learning - Cách Tiếp Cận Truyền Thống
Nếu có vô vàn ảnh mỗi người, bạn hoàn toàn có thể huấn luyện một classifier đa lớp. Vấn đề là: thêm nhân sự hay thay đổi danh sách là phải train lại. Đó là cơn ác mộng tốn kém thời gian và tài nguyên. Phương pháp one-shot learning nảy sinh để giải quyết bài toán chỉ có vài tấm ảnh mỗi người. Ta muốn mạng học được đặc trưng thật tốt chỉ từ một hoặc vài mẫu.
2.2 Từ One-shot Đến Similarity Learning
Thay vì dạy mô hình "Ảnh này thuộc về ai", ta dạy mô hình "Ảnh này giống hay khác ảnh kia bao nhiêu". Hướng tiếp cận này gọi là similarity learning. Bằng cách chuyển câu hỏi, ta không cần huấn luyện lại khi có người mới. Chỉ cần tính vector đặc trưng (embedding) của người mới rồi lưu vào database. Sau này so sánh trực tiếp embedding với các vector khác là xong.
2.3 Siamese Network - Kiến Trúc Song Sinh
Mô hình Siamese sử dụng hai (hoặc nhiều) nhánh mạng CNN có chung trọng số. Mỗi nhánh nhận một ảnh, cho ra embedding. Từ đó ta tính khoảng cách. Điểm mấu chốt là hai nhánh phải "nhìn" ảnh theo cách giống hệt nhau, nhờ vậy việc so sánh mới nhất quán.
Kiểu kiến trúc này rất phổ biến trong giai đoạn đầu của face recognition vì đơn giản mà hiệu quả. Tuy nhiên, để training tốt cần cặp ảnh (positive/negative) được chọn kỹ, tránh việc mô hình chỉ gặp các cặp quá dễ.
2.4 Chuẩn Bị Dữ Liệu và Augmentation
Dữ liệu chính là xương sống. Dù mô hình có mạnh đến đâu nhưng dữ liệu bẩn thì cũng khó đạt kết quả cao. Một số lời khuyên:
- Thu thập đa dạng: nhiều góc mặt, biểu cảm, điều kiện ánh sáng. Nếu chỉ toàn ảnh chụp thẳng, khi gặp ảnh nghiêng, mô hình dễ bối rối.
- Làm sạch: lọc ảnh mờ, trùng lặp, sai nhãn. Mình từng đau đầu vì vài tập dữ liệu tải về trên mạng dính nhãn sai, làm giảm hẳn accuracy.
- Augmentation: xoay nhẹ, thay đổi độ sáng, cắt xén… giúp mô hình quen với các biến đổi.
2.5 Tầm Quan Trọng Của Alignment
Trước khi đưa ảnh vào mạng, ta thường phải align (căn chỉnh) khuôn mặt. Điều này đảm bảo mắt, mũi, miệng nằm ở vị trí tương đối giống nhau giúp mạng học hiệu quả hơn. Nếu bước này làm qua loa, embedding có thể rất nhiễu.
3. FaceNet Và Triplet Loss
3.1 Sự Ra Đời Của FaceNet
Năm 2015, Google giới thiệu FaceNet, đánh dấu bước ngoặt lớn trong lĩnh vực. Thay vì chỉ học phân biệt giống/khác, FaceNet tối ưu trực tiếp không gian embedding sao cho khoảng cách giữa các khuôn mặt cùng người ngắn hơn một ngưỡng so với khuôn mặt khác người. Điều này được hiện thực bằng Triplet Loss.

Hình minh họa kiến trúc FaceNet trong bài báo gốc
3.2 Triplet Loss Hoạt Động Thế Nào?

Anchor là ảnh gốc, Positive là ảnh khác của chính người đó, còn Negative là ảnh của người khác. Mục tiêu: khoảng cách A-P phải nhỏ, trong khi A-N phải lớn hơn một margin. Nhờ đó, các mặt cùng người tập trung lại, mặt khác người bị đẩy xa.
3.3 Chọn Triplet: Chuyện Không Đơn Giản
Nếu chỉ chọn ngẫu nhiên, đa số triplet quá "dễ": Negative cách Anchor rất xa, Positive đã rất gần. Khi đó loss gần như bằng 0, mô hình không học gì thêm. Vì vậy, ta phải hard triplet mining – chọn những Negative gần với Anchor, Positive lại ở xa. Một mẹo là tính khoảng cách ngay trên batch hiện tại, sau đó chọn cặp "khó" nhất. Làm vậy, mô hình liên tục được thử thách, tránh việc học lờ đờ.
3.4 Ưu Và Nhược Điểm
FaceNet với Triplet Loss cho độ chính xác rất cao, nhưng quá trình training phức tạp. Việc chọn triplet khó đòi hỏi cẩn thận, đồng thời chi phí tính toán lớn. Chính điều này thôi thúc cộng đồng tìm kiếm loss khác đơn giản hơn nhưng vẫn mạnh mẽ.
4. CosFace - Khi Cosine Lên Ngôi
4.1 Ý Tưởng Chính
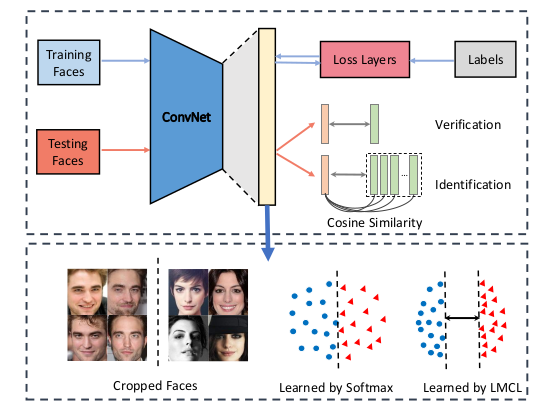
CosFace (2018) đề xuất dùng hàm Large Margin Cosine Loss (LMCL), thay vì dùng khoảng cách Euclid. Ý tưởng: ảnh thuộc cùng lớp phải có cosine similarity vượt trội so với các lớp khác. Nhờ thêm một margin vào phần cosine, mô hình buộc phải "tách" các lớp rõ ràng hơn.
4.2 Công Thức LMCL
$$L{CosFace} = -\frac{1}{N} \sum{i=1}^{N} \log \frac{e^{s(\cos(\theta{yi}) - m)}}{e^{s(\cos(\theta{yi}) - m)} + \sum{j \neq yi} e^{s\cos(\theta_j)}}$$
Trong đó m là margin, s là hệ số scale. Nếu không có m, Loss đơn thuần giống softmax truyền thống. Nhờ trừ thêm m, ảnh thuộc lớp đúng phải vượt qua một ngưỡng an toàn mới được coi là chính xác.
4.3 Ứng Dụng Và Hiệu Quả
CosFace loại bỏ bước hard mining triplet, training ổn định và nhẹ nhàng hơn FaceNet. Độ chính xác đạt được cũng tương đương, thậm chí nhỉnh hơn trên nhiều bộ dữ liệu. Khi làm thực tế, mình thấy CosFace cho kết quả tốt với dataset vừa phải (dưới 1 triệu ảnh) mà không cần điều chỉnh quá nhiều.
5. ArcFace - Bước Tiến Với Angular Margin
5.1 Tại Sao Cần ArcFace?
Dù CosFace đã mạnh, một số nghiên cứu chỉ ra rằng margin theo cosine có thể không nhất quán trên toàn bộ không gian góc. ArcFace (cũng 2018) đề xuất chuyển sang additive angular margin: thay vì cos(θ) - m, ta dùng cos(θ + m). Nhờ vậy, khoảng cách góc giữa các lớp được giữ ổn định bất kể vị trí của vector.

Hình từ bài báo ArcFace mô tả biên dạng margin theo góc
5.2 Additive Angular Margin Loss
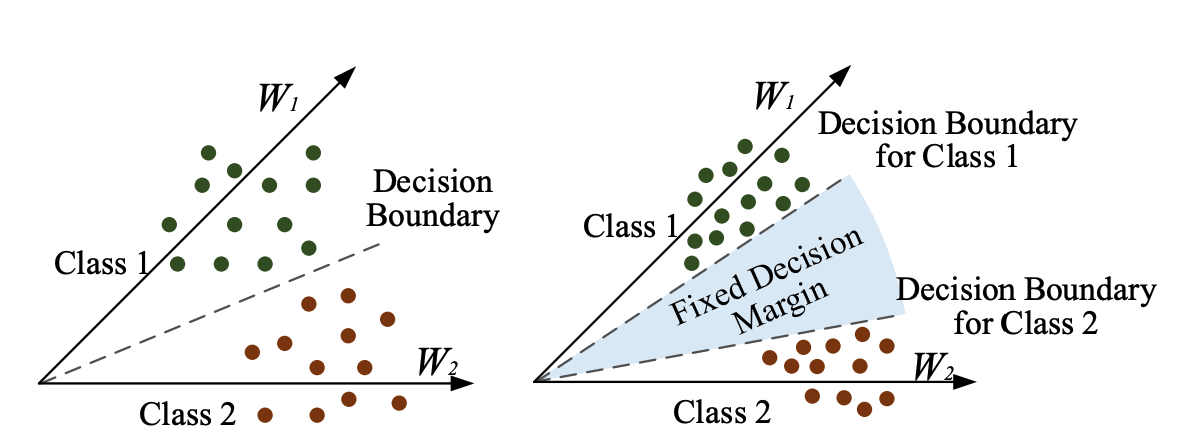
$$L{ArcFace} = -\frac{1}{N} \sum{i=1}^{N} \log \frac{e^{s \cdot \cos(\theta{yi} + m)}}{e^{s \cdot \cos(\theta{yi} + m)} + \sum{j \neq yi} e^{s \cdot \cos(\theta_j)}}$$
ArcFace thể hiện nhiều ưu điểm:
- Giải thích hình học rõ ràng: Góc giữa hai vector là đại lượng quen thuộc, margin trên góc dễ hình dung hơn margin trên cosine.
- Margin nhất quán: Mọi vị trí trên không gian góc đều chịu cùng một tác động của
m, giúp phân bố embedding gọn gàng hơn. - Thực nghiệm xuất sắc: Trên nhiều benchmark nổi tiếng, ArcFace đạt accuracy vượt trội, trở thành chuẩn mực mới.
6. Từ Lý Thuyết Đến Mô Hình Thực Tế
6.1 Các Bước Chuẩn Bị Dữ Liệu
- Thu thập ảnh: Có thể tự chụp hoặc sử dụng kho dữ liệu sẵn. Để đảm bảo chất lượng, nên có nhiều góc, nhiều điều kiện ánh sáng khác nhau. Ít nhất mỗi người cần 5-10 ảnh.
- Gán nhãn: Đặt tên file hoặc dùng metadata. Nhãn phải chính xác tuyệt đối; chỉ vài ảnh sai nhãn cũng gây lỗi trong nhận diện.
- Làm sạch: Xoá ảnh mờ, ảnh che mặt, ảnh không đúng chủ thể. Mình thường viết script tự động lọc độ mờ (dùng OpenCV) kết hợp kiểm tra thủ công.
- Face Detection + Alignment: Chạy qua một mạng detect (như MTCNN, RetinaFace) để crop khuôn mặt và align. Kết quả sau bước này rất quan trọng cho quá trình training.
6.2 Training Mô Hình ArcFace
- Framework: PyTorch hoặc TensorFlow đều ổn. Cá nhân mình thích PyTorch vì linh hoạt.
- Backbone: Có thể dùng ResNet, MobileFaceNet… tuỳ nhu cầu. Dự án lớn thì ResNet100, nhỏ gọn thì MobileFaceNet.
- Loss Function: Sử dụng ArcFace Loss. Nên kiểm thử vài giá trị
m,s. - Optimizer: SGD hoặc Adam. Mình thường bắt đầu với SGD + momentum 0.9, learning rate khoảng 0.1 rồi giảm dần.
- Data Augmentation: Random flip, color jitter, random crop… giúp mô hình không bị overfit.
- Validation: Chuẩn bị tập validation riêng. Các benchmark như LFW, CFP-FP sẽ giúp đo độ chính xác.
6.3 Lưu Trữ Và Quản Lý Embedding
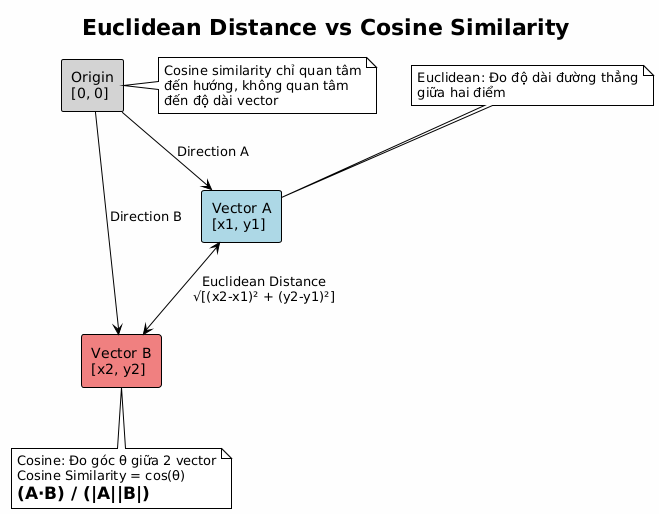
Sau khi có mô hình, bạn cần nơi lưu trữ vector embedding. Nhiều người dùng file hoặc database NoSQL, nhưng cách mà mình ưa thích nhất là PostgreSQL kèm extension pgvector. Nó cho phép lưu trữ vector và tìm kiếm theo cosine similarity cực nhanh.
6.4 Xây Dựng API
Một pipeline nhận diện khuôn mặt thường có các API sau:
- Enroll: Nhận ảnh nhân viên mới, chạy qua detector, aligner, extractor rồi lưu embedding vào database.
- Verify: So sánh ảnh live với embedding sẵn có của người A. Trả về kết quả giống hoặc khác.
- Identify: Nhận ảnh, tìm kiếm trong toàn bộ database để xem đó là ai. Đây là API dùng cho điểm danh.
Mỗi bước có thể đóng gói thành microservice riêng để dễ bảo trì và mở rộng.
6.5 Bảo Mật Và Quyền Riêng Tư
Khi lưu trữ khuôn mặt, câu chuyện bảo mật là ưu tiên số một. Bạn nên:
- Mã hoá ảnh gốc hoặc chỉ lưu embedding đã chuẩn hoá (vector 512 chiều) để giảm rủi ro lộ thông tin.
- Thiết lập cơ chế phân quyền chặt chẽ đối với database.
- Thông báo rõ ràng cho người dùng về việc sử dụng dữ liệu khuôn mặt.
7. Case Study: Hệ Thống Điểm Danh Trong Công Ty
Đây là phần mình thích chia sẻ nhất. Dưới đây là kinh nghiệm triển khai thực tế.
7.1 Bài Toán Đặt Ra
Công ty có khoảng 1000 nhân viên, làm việc theo ca. Mục tiêu là khi nhân viên đến văn phòng, chỉ cần đứng trước camera một vài giây để hệ thống ghi nhận. Dữ liệu này sau đó được gửi về server, lưu trữ và xử lý tính lương, chấm công tự động.
7.2 Kiến Trúc Tổng Quan
Camera đặt tại cổng, nối với một máy tính edge. Máy tính này chạy module detect và extract, sau đó gửi embedding lên server qua kết nối bảo mật. Server thực hiện truy vấn vector để tìm kiếm người phù hợp.
7.3 Quá Trình Enroll Nhân Viên
- Nhân viên được yêu cầu chụp 5-10 tấm ảnh ở các góc khác nhau.
- Ảnh được gửi về backend, qua bước detect + align.
- Embedding tạo ra từ mỗi ảnh được lưu vào bảng
face_embeddingstrong PostgreSQL. Bảng gồmemployee_id,vector(kiểuvector(512)), vàcreated_at. - Khi điểm danh, hệ thống lấy ảnh mới, so sánh với các vector đã lưu. Nếu similarity vượt ngưỡng, coi như nhận diện thành công.
7.4 Tối Ưu Tốc Độ
- Edge computing: Xử lý detect và extract ngay tại camera để giảm lượng dữ liệu phải gửi. Chỉ cần gửi vector nhỏ (512 float) nên rất nhanh.
- Batch search: Khi nhiều người check-in liên tục, gom embedding thành batch để tìm kiếm một lần.
- Cache: Những nhân viên check-in gần nhau về thời gian có thể được cache embedding tạm thời ở server để so sánh nhanh hơn.
- GPU: Nếu tải quá lớn, có thể trang bị GPU cho server để tăng tốc tính toán cosine.
7.5 Kết Quả Và Bài Học
Sau 3 tháng chạy thử, hệ thống đạt độ chính xác khoảng 99% trong điều kiện ánh sáng tốt. Một số lỗi còn lại chủ yếu do nhân viên đứng quá xa camera hoặc che mặt bằng vật dụng. Bài học quan trọng là cần giải thích rõ cho mọi người cách đứng trước camera và nên có người hỗ trợ ở giai đoạn đầu.
8. Nâng Cao: Phát Hiện Giả Mạo (Liveness Detection)
Mối nguy lớn khi dùng nhận diện khuôn mặt là người xấu có thể sử dụng ảnh chụp hoặc video để lừa hệ thống. Để giảm rủi ro này, ta áp dụng liveness detection.
8.1 Phương Pháp Cơ Bản
- Blink detection: Yêu cầu người dùng chớp mắt hoặc quay đầu. Hệ thống kiểm tra sự thay đổi khuôn mặt để xác nhận đang tương tác với người thật.
- Texture analysis: Phân tích độ sắc nét, nhiễu của ảnh xem có phải chụp lại từ màn hình hoặc in ra giấy không.
- Depth sensing: Sử dụng camera 3D đo khoảng cách, đảm bảo khuôn mặt có độ sâu thật.
8.2 Tích Hợp Vào Pipeline
Bước liveness nên được đặt trước khi tính embedding. Nếu không vượt qua, hệ thống từ chối ngay. Việc này hơi làm chậm quá trình, nhưng tăng độ tin cậy đáng kể.
9. Những Vấn Đề Thường Gặp Và Cách Khắc Phục
9.1 Sai Số Khi So Khớp
Một số trường hợp, similarity giữa hai ảnh cùng người lại thấp hơn threshold. Lý do có thể là ánh sáng quá khác biệt, người đeo kính hay khẩu trang. Giải pháp là:
- Thu thập thêm ảnh với điều kiện gần giống tình huống thực tế.
- Sử dụng mô hình đã được huấn luyện trên dữ liệu có khẩu trang (nếu cần).
- Điều chỉnh threshold theo từng môi trường cụ thể.
9.2 Quá Tải Hệ Thống
Khi số lượng người nhận diện tăng cao, truy vấn vector liên tục có thể tạo thành điểm nghẽn. Nên dùng index HNSW trong pgvector và đặt cấu hình tham số phù hợp (efsearch, efconstruction). Song song, cần tối ưu hạ tầng, có thể tách database đọc/ghi để chịu tải tốt hơn.
9.3 Bảo Vệ Dữ Liệu Người Dùng
Luôn cập nhật chính sách bảo mật rõ ràng. Nếu có thể, chỉ lưu embedding thay vì ảnh gốc. Nên có cơ chế xoá dữ liệu nếu người dùng yêu cầu. Việc mã hoá khi truyền và khi lưu trữ giúp tránh rò rỉ dữ liệu.
10. Mẹo Tăng Tốc Và Cải Thiện Chất Lượng
10.1 Pre-compute Embeddings
Đối với database lớn, bạn nên tính trước embedding và lưu vào cột vector. Khi truy vấn, chỉ cần lấy vector đó ra so sánh, không phải chạy model lại từ đầu.
10.2 Sử Dụng GPU
Nếu có GPU, hãy tận dụng để chạy feature extraction. Với các mô hình sâu như ResNet100, tốc độ trên GPU nhanh hơn CPU rất nhiều. Tuy nhiên, bạn cần cân nhắc chi phí và cách triển khai (server có GPU hay dùng cloud service).
10.3 Batch Processing
Khi phải xử lý nhiều ảnh cùng lúc, ví dụ camera quay liên tục, nên gom thành batch để đưa qua model. Nhờ khả năng tính toán song song của GPU, thời gian xử lý sẽ giảm đáng kể.
10.4 Theo Dõi Chất Lượng Định Kỳ
Đừng quên xây dựng cơ chế đánh giá định kỳ. Có thể mỗi tháng lấy một tập ảnh ngẫu nhiên để đo lại accuracy, kiểm tra threshold xem còn phù hợp không. Thực tế môi trường, ánh sáng, camera có thể thay đổi, cần hiệu chỉnh liên tục.
11. Tổng Kết Và Những Hướng Đi Tương Lai
Nhận diện khuôn mặt đã phát triển vượt bậc trong vài năm qua. Từ những mô hình dựa vào khoảng cách Euclid đơn thuần, chúng ta giờ có các loss theo góc cực kỳ hiệu quả như ArcFace. Tuy nhiên, vẫn còn nhiều hướng nghiên cứu thú vị:
- Lightweight models: Làm sao để chạy tốt trên thiết bị di động hay edge device với tài nguyên hạn chế.
- Domain adaptation: Huấn luyện mô hình dễ dàng thích ứng khi môi trường thay đổi (ánh sáng, quốc gia, văn hoá…).
- Fairness và bias: Đảm bảo mô hình không thiên vị nhóm người nào. Điều này đòi hỏi dataset đa dạng và kỹ thuật kiểm tra cẩn thận.
Với tư cách kỹ sư AI, mình luôn tin rằng công nghệ chỉ thực sự có ý nghĩa khi phục vụ con người một cách an toàn và có trách nhiệm.
12. Theo Dõi Và Cập Nhật Mô Hình
Hệ thống nhận diện khuôn mặt không phải cứ triển khai xong là "để đó". Môi trường luôn thay đổi: camera mới, ánh sáng khác, thậm chí thói quen của người dùng cũng biến chuyển. Vì thế ta cần một cơ chế theo dõi và cập nhật định kỳ.
Trước hết, hãy đặt lịch đánh giá lại mô hình. Ví dụ mỗi quý, lấy mẫu ảnh ngẫu nhiên trong thực tế để đo lại tỉ lệ đúng sai. Nếu thấy độ chính xác giảm, bạn nên điều tra nguồn dữ liệu mới và retrain. Việc này tránh trường hợp mô hình "lão hoá" theo thời gian.
Tiếp theo, hãy lưu lại log của mọi lần nhận diện: thời gian, kết quả, độ tương tự. Khi có khiếu nại rằng hệ thống nhận sai, ta tra được nguyên nhân. Những log này cũng hữu ích để kiểm tra xu hướng dài hạn (ví dụ, một số camera có tỷ lệ lỗi cao bất thường).
Đừng quên cơ chế versioning cho model. Mỗi khi retrain, hãy lưu lại phiên bản cũ để có thể quay lại nếu phiên bản mới hoạt động kém. Một giải pháp phổ biến là sử dụng hệ thống quản lý model (MLflow, DVC) kết hợp CI/CD để triển khai tự động.
Cuối cùng, dữ liệu người dùng có thể thay đổi: họ thay kiểu tóc, đeo kính, hoặc đơn giản là già đi. Cần cho phép cập nhật embedding định kỳ. Nhiều công ty khuyến khích nhân viên chụp lại ảnh mỗi năm một lần để hệ thống luôn "bắt kịp" sự thay đổi.
13. Ứng Dụng Rộng Hơn Của Face Recognition
Điểm danh chỉ là một trong vô số ứng dụng của nhận diện khuôn mặt. Ngày nay, công nghệ này còn xuất hiện ở sân bay, siêu thị, thậm chí các ứng dụng chăm sóc khách hàng.
- An ninh công cộng: Camera giám sát ở nơi đông người có thể quét khuôn mặt để phát hiện đối tượng bị truy nã. Điều này giúp lực lượng chức năng phản ứng nhanh hơn, tuy nhiên phải đi kèm quy định chặt chẽ để bảo vệ quyền riêng tư.
- Thanh toán không chạm: Một số cửa hàng ở Trung Quốc cho phép khách hàng thanh toán chỉ bằng cách nhìn vào camera. Ví của bạn được liên kết sẵn, quá trình mua hàng diễn ra cực kỳ nhanh gọn.
- Tương tác cá nhân hoá: Ở lĩnh vực bán lẻ, nhận diện khuôn mặt giúp gợi ý sản phẩm dựa trên lịch sử mua sắm của bạn. Tuy nhiên, người dùng nên được hỏi ý kiến vì đây là dữ liệu nhạy cảm.
- Quản lý ra vào: Thay thế thẻ từ trong toà nhà, tránh việc mượn thẻ hoặc quên thẻ. Cửa mở khi camera xác nhận đúng người.
Một điểm thú vị là với cùng một mô hình, ta có thể áp dụng cho nhiều kịch bản khác nhau bằng cách chỉ thay đổi ngưỡng similarity hoặc logic xử lý sau khi nhận dạng. Điều quan trọng là phải cân bằng giữa tiện lợi và quyền riêng tư của người dùng cuối.
14. Triển Khai Ở Quy Mô Lớn
Khi số lượng người dùng tăng lên hàng trăm nghìn, thậm chí hàng triệu, bạn sẽ đối mặt với những thử thách hoàn toàn mới.
Thứ nhất là dung lượng lưu trữ. Mỗi vector embedding 512 chiều dạng float32 chiếm khoảng 2 kB. Với một triệu người, lượng dữ liệu chỉ riêng embedding đã khoảng 2 GB, chưa kể thông tin phụ khác. Database cần được tối ưu bằng cách phân vùng hoặc sử dụng hệ thống lưu trữ phân tán.
Thứ hai là tốc độ tìm kiếm. Các thuật toán tìm kiếm gần đúng như HNSW trong pgvector hoặc FAISS sẽ phát huy tác dụng. Chúng cho phép truy vấn top-K vector gần nhất trong thời gian rất ngắn dù dataset lớn.
Thứ ba là khả năng mở rộng hệ thống. Một mô hình duy nhất khó đáp ứng hàng nghìn truy vấn mỗi giây. Lúc này, bạn nên thiết kế theo hướng microservices, có thể nhân bản nhiều instance của service nhận diện, đặt trước một load balancer. Dữ liệu cũng nên được cache tại nhiều lớp để giảm tải cho database.
Cuối cùng là giám sát hệ thống. Khi mạng lưới phức tạp, chỉ một thành phần gặp trục trặc có thể ảnh hưởng toàn bộ. Hãy sử dụng các công cụ monitoring như Prometheus, Grafana để theo dõi latency, tỉ lệ lỗi. Từ đó, bạn có thể chủ động xử lý trước khi người dùng phàn nàn.
15. Công Cụ Hữu Ích Cho Phát Triển
Trong quá trình xây dựng hệ thống, mình đã thử khá nhiều phần mềm và dịch vụ hỗ trợ. Dưới đây là một số công cụ đáng chú ý:
- MLflow: Quản lý toàn bộ vòng đời mô hình từ training đến deploy. Bạn có thể lưu lại các tham số, metric và dễ dàng so sánh giữa các phiên bản.
- DVC: Giúp theo dõi dữ liệu và model trong git. Khi dataset lớn, DVC cho phép lưu trữ ngoài (S3, GCS) nhưng vẫn quản lý bằng các file nhỏ trong repo.
- Weights & Biases: Một nền tảng theo dõi thí nghiệm, vẽ biểu đồ loss, accuracy theo thời gian. Rất tiện khi làm việc nhóm.
- FAISS: Thư viện của Facebook hỗ trợ tìm kiếm vector cực nhanh. Nếu bạn không dùng pgvector, FAISS là lựa chọn đáng cân nhắc để xây dựng chỉ mục riêng.
- Docker: Gói gọn môi trường chạy model, tránh lỗi "works on my machine". Nhờ Docker, việc triển khai lên server hay cloud trở nên đơn giản.
Sử dụng đúng công cụ giúp tiết kiệm hàng giờ đồng hồ, đặc biệt khi bạn phải lặp đi lặp lại các thí nghiệm hoặc triển khai cho nhiều môi trường khác nhau.
16. Kết Luận
Nhìn lại chặng đường, nhận diện khuôn mặt đã tiến một quãng dài từ những thuật toán đơn giản cho đến các mô hình sâu hiện đại như ArcFace. Khi ứng dụng vào thực tế, ta phải kết hợp nhiều yếu tố: từ việc chuẩn bị dữ liệu, chọn loss function, tối ưu tốc độ cho tới bảo mật và tuân thủ quy định pháp lý.
Điều quan trọng nhất là hãy luôn đặt trải nghiệm của người dùng lên hàng đầu. Công nghệ chỉ thực sự hữu ích khi nó làm cuộc sống dễ dàng hơn mà không xâm phạm quyền riêng tư. Nếu bạn dự định triển khai hệ thống của riêng mình, hy vọng những chia sẻ trong bài sẽ giúp bạn tránh được một số bỡ ngỡ ban đầu.
Đừng quên rằng mỗi dự án thành công đều bắt đầu từ bước nhỏ. Bạn có thể thử nghiệm với một tập dữ liệu vài nghìn ảnh, chạy trên một chiếc máy tính cá nhân. Từ những trải nghiệm đó, khi mở rộng lên quy mô lớn hơn, bạn sẽ có nền tảng vững chắc để tối ưu hoá mọi khía cạnh: từ pipeline xử lý ảnh đến hạ tầng lưu trữ và truy vấn. Hãy kiên nhẫn lặp đi lặp lại quá trình "thu thập → huấn luyện → đánh giá" cho tới khi hệ thống đạt yêu cầu.
17. Lời Cảm Ơn
Cảm ơn bạn đã dành thời gian theo dõi bài viết khá dài này. Hy vọng sau khi đọc xong, bạn có một cái nhìn toàn diện hơn về nhận diện khuôn mặt: từ giai đoạn hình thành ý tưởng, các thuật toán nổi bật cho đến cách triển khai thực tế trong doanh nghiệp. Nếu bạn định xây dựng hệ thống cho riêng mình, hãy bắt đầu từ những bước nhỏ: thu thập dữ liệu thật tốt, chọn mô hình phù hợp, và quan trọng nhất là giữ cho quy trình đơn giản, dễ kiểm soát.
Hẹn gặp lại trong những bài chia sẻ tiếp theo!
Tài Liệu Tham Khảo
- FaceNet: A Unified Embedding for Face Recognition and Clustering
- CosFace: Large Margin Cosine Loss for Deep Face Recognition
- ArcFace: Additive Angular Margin Loss for Deep Face Recognition
- InsightFace Documentation
Chúc các bạn nhận diện khuôn mặt vui vẻ.