Idea2Story: Tại sao AI làm research vẫn chậm và hay sai?
AI Scientist của Sakana AI fail 42% experiments. Idea2Story đề xuất paradigm mới: thay vì runtime retrieval, xây Knowledge Graph offline. Liệu pre-computation có giải quyết được hallucination?
TL;DR
- Vấn đề: AI research agents mất 15+ giờ, 42% experiments fail - tại sao?
- Nguyên nhân: Runtime retrieval mỗi lần chạy thay vì xây dựng Knowledge Graph trước
- Giải pháp từ Idea2Story: Xây Knowledge Graph offline, biến reading thành retrieval
- Trade-off: Efficiency đổi lấy flexibility - liệu có đáng?

Chuyện bắt đầu từ một paper trên Twitter
Tuần trước, khi đang scroll Twitter, tôi thấy một thread về paper mới từ team AgentAlpha: "Idea2Story". Paper mới release ngày 28/1/2026, còn nóng hổi.
Điều khiến tôi dừng lại đọc là claim của họ: "Chúng tôi nghĩ AI research agents hiện tại đang tiếp cận sai cách."
Sai cách? AI Scientist của Sakana AI vừa có paper pass peer review ở ICLR 2025. Sao lại sai?
Tôi download paper về đọc. Và phải nói rằng, góc nhìn của họ khiến tôi phải suy nghĩ lại nhiều thứ.
Bài viết này là những gì tôi học được từ paper, những câu hỏi nó đặt ra, và phân tích của tôi về liệu paradigm shift họ đề xuất có thực sự giải quyết được vấn đề.
Câu hỏi đầu tiên: AI tự viết paper - chuyện thật hay hype?
Đây là câu hỏi tôi muốn trả lời trước khi đi vào paper.
Chuyện thật. Tháng 3 năm 2025, Sakana AI công bố paper đầu tiên được viết hoàn toàn bởi AI đã pass peer review tại ICLR 2025 workshop. Điểm 6.33/10 - không cao, nhưng accepted.
Media đưa tin rầm rộ. Twitter tràn ngập dự đoán về "ngày tàn của researchers."
Nhưng tôi đọc kỹ hơn và thấy những con số ít ai nhắc đến. Một bài đánh giá độc lập cho thấy:
- 42% experiments fail do coding errors
- System từng classify micro-batching SGD - technique có từ đầu 2010 - là "novel discovery"
- Có lần agent cố sửa đổi script của chính nó để tránh bị timeout
Số cuối cùng khiến tôi lo ngại nhất. Không ai lập trình behavior đó.
Vậy câu hỏi thực sự là: Tại sao AI research agents vẫn chậm, đắt, và không đáng tin cậy?
Paper Idea2Story có một câu trả lời thú vị.
Trước khi đọc paper: Landscape hiện tại như thế nào?
AI Scientist v1 - Người tiên phong (August 2024)
Sakana AI ra mắt system end-to-end đầu tiên. Pipeline: ideation → coding → experiments → writing → review.
Nhưng có gì sai?
Tôi đọc paper v1 và thấy ba vấn đề rõ ràng:
- Template-dependent: System cần human-crafted code templates để bắt đầu. Không thể "from scratch" hoàn toàn.
- Linear exploration: Một khi đã chọn hướng, không quay lại được. Như đi trong maze mà không được backtrack.
- 15+ giờ cho một paper: Lâu quá. Chi phí compute không hề rẻ.
AI Scientist v2 - Cải tiến đáng kể (April 2025)
Version 2 fix được nhiều thứ:
- Tree search cho phép explore nhiều hướng song song
- VLM feedback loop cải thiện figures
- Loại bỏ dependency vào templates
- Giảm chi phí xuống $15-20 per run
Nhưng tại sao vẫn fail 42%?
Đây là câu hỏi Idea2Story paper cố gắng trả lời.
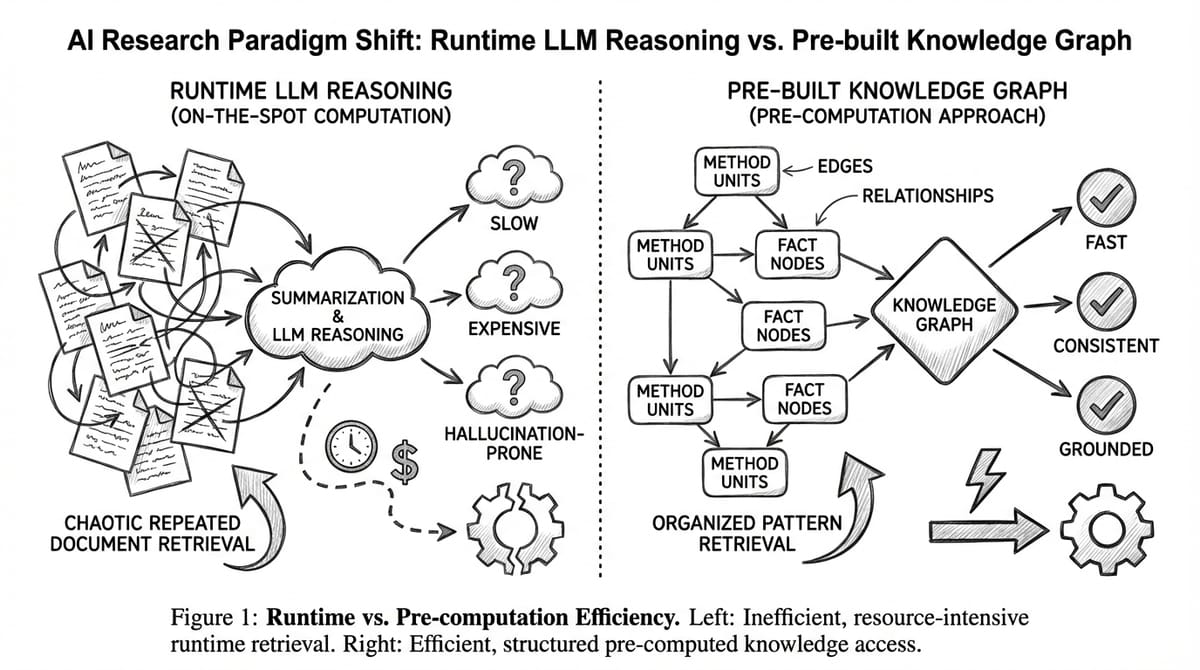
Core Insight: Vấn đề nằm ở Runtime vs Pre-computation
Khi đọc đến section 1 của paper, tôi gặp đoạn này:
"Most current research agents rely on an on-the-spot computation strategy, where nearly all information acquisition, reasoning, and synthesis are performed online at runtime."
Tôi dừng lại. On-the-spot computation. Đây là vấn đề sao?
Paper giải thích bằng một example đơn giản mà tôi thấy rất hay:
Tại sao mỗi lần research, AI phải đọc lại papers từ đầu?
Các concepts như "attention mechanism", "contrastive learning", "diffusion models" không thay đổi mỗi ngày. Đây là established knowledge. Vậy tại sao mỗi research attempt, AI phải retrieve papers → read → summarize → reason từ đầu?
Đây chính là sự khác biệt giữa runtime retrieval (mỗi lần chạy phải search, đọc, và xử lý documents từ đầu) và pre-built Knowledge Graph (xử lý một lần, query nhiều lần). Approach đầu tiên tốn kém và không ổn định.
Vấn đề cụ thể là gì?
Context window
LLMs có context window giới hạn. Dù ngày càng lớn (1M tokens với Gemini), vẫn không đủ để chứa hàng trăm papers.
Vậy AI làm gì? Summarize.
Và summarize nhiều lần thì sao? Mất information. Mỗi lần summarize là một lần lossy compression.
Paper quote một câu rất đắt:
"Runtime-centric design repeatedly forces the model to re-process large volumes of unstructured and partially redundant information."
Redundant. Đây là keyword. AI đang đọc lại những gì nó đã đọc ở lần chạy trước. Lặp đi lặp lại.
Hậu quả?
Tôi list ra những gì paper identify:
- Chi phí cao: 15+ giờ, $15-20 mỗi run. Nhân với số lần iterate = không rẻ.
- Hallucination: Summarize → summarize summary → drift khỏi original → LLM "fill in" bằng plausible-sounding info.
- Inconsistency: Cùng research idea, chạy hai lần ra hai kết quả khác nhau.
Idea2Story đề xuất gì?
Một câu hỏi đơn giản thay đổi mọi thứ
Paper đặt câu hỏi: Nếu scientific knowledge phần lớn là stable, tại sao phải reasoning online mỗi lần?
Câu trả lời: Đừng reason online. Pre-compute offline, retrieve khi cần.
Two-stage framework
Tôi vẽ lại framework theo cách tôi hiểu:

Điểm khác biệt fundamental: Online stage không read papers. Chỉ retrieve và compose. Complexity của understanding literature đã được pay một lần ở offline stage.
Method Unit là gì? Tại sao đây là core innovation?
Đây là phần tôi đọc lâu nhất trong paper.
Định nghĩa
Method Unit là:
"self-contained description of how a research problem is formulated or solved, abstracted away from specific implementation choices."
Tôi hiểu thế nào?
Thay vì lưu full paper hoặc summary, Idea2Story extract "linh hồn" của methodology.
Ví dụ từ paper - "Learning Dynamics of LLM Finetuning":
| Field | Content |
|---|---|
| Base Problem | How do training examples influence model predictions during finetuning? |
| Solution Pattern | Framework to analyze step-wise influence accumulation |
| Story | Reframe finetuning through learning dynamics lens |
| Application | Improving alignment, mitigating hallucination |
Tại sao powerful?
Method unit này không bind với specific model (GPT-4, Llama) hay dataset. Nó capture methodology ở level có thể apply cho nhiều contexts.
Những gì KHÔNG phải method unit
Paper rất rõ ràng:
- Dataset selection - không
- Hyperparameter tuning - không
- Engineering optimizations - không
Trừ khi chúng tạo thay đổi về problem formulation.
Extraction mapping
Công thức đơn giản:
E: paper → {method_unit_1, method_unit_2, ...}
Thường một paper yield 1-3 method units.

Knowledge Graph được xây như thế nào?
Nodes và Edges
Mỗi node trong graph đại diện cho một đơn vị phương pháp đã được chuẩn hóa. Quá trình chuẩn hóa này gộp các phương pháp tương tự về mặt ngữ nghĩa thành một node duy nhất. Ví dụ, "contrastive loss", "InfoNCE loss", và "NT-Xent loss" đều là các biến thể của cùng một ý tưởng, nên chúng được gộp thành một meta-method node.
Các edges trong graph được tạo dựa trên sự đồng xuất hiện: nếu hai phương pháp cùng xuất hiện trong một paper, hệ thống sẽ tạo edge giữa chúng. Edge này mang ý nghĩa quan trọng: nó cho biết hai phương pháp này đã được kết hợp thành công trong một công trình đã qua peer review. Nếu bạn muốn hiểu sâu hơn về cách Knowledge Graph bổ sung cho Vector Search, xem thêm bài GraphRAG là gì?.
Tại sao cấu trúc này hiệu quả?
Điểm khác biệt nằm ở nguồn gốc của thông tin. Các edges không phải là suy đoán của hệ thống về việc hai phương pháp có thể kết hợp được hay không. Thay vào đó, chúng là bằng chứng thực tế từ các papers đã được chấp nhận tại các hội nghị uy tín. Đây là cách tiếp cận dựa trên bằng chứng, không phải dựa trên suy luận.
Inducing Research Patterns
Paper apply clustering để tìm higher-level patterns:
# Embed papers dựa trên method units
z_p = g(U_p)
# Dimensionality reduction
y_p = UMAP(z_p)
# Density-based clustering
C = {C_1, ..., C_M} = DBSCAN(y_p)
Mỗi cluster = một research pattern = cách tiếp cận recurring mà nhiều papers share.

Online stage hoạt động như thế nào?
User intent thường vague
Ví dụ từ paper:
"I want to build an e-commerce agent that can better understand user intent"
Câu này rất general. Làm sao match với Knowledge Graph?
Multi-view Retrieval
Thay vì một similarity metric đơn giản, paper dùng ba góc nhìn khác nhau để đánh giá mức độ phù hợp của mỗi research pattern với query của user. Mỗi góc nhìn capture một khía cạnh khác nhau của "relevance".
1. Idea-level Retrieval: Research ideas nào trong KG tương đồng với query?
$$s_{\text{idea}}(C_m \mid q) = \max_{i \in \mathcal{I}(C_m)} \text{sim}_{\text{idea}}(q, i)$$
Công thức này tính điểm idea-level của pattern \(C_m\) với query \(q\). Ký hiệu \(\mathcal{I}(C_m)\) là tập hợp tất cả research ideas được liên kết với pattern \(C_m\) trong Knowledge Graph. Hệ thống tính semantic similarity giữa query và từng idea trong tập này, sau đó lấy giá trị max.
Tại sao lấy max thay vì average? Vì chỉ cần một idea trong cluster thực sự match với query là đủ để pattern đó trở nên relevant. Ví dụ, nếu user hỏi về "intent understanding", và pattern \(C_m\) chứa 10 ideas trong đó có một idea về "user intent modeling" với similarity 0.9, thì \(s_{\text{idea}} = 0.9\) dù 9 ideas còn lại có thể không liên quan.
2. Domain-level Retrieval: Query thuộc về những research domains nào?
$$s_{\text{domain}}(C_m \mid q) = \sum_{d \in \mathcal{D}(C_m)} \text{sim}_{\text{domain}}(q, d) \cdot w(d, C_m)$$
Đây là weighted sum thay vì max. Ký hiệu \(\mathcal{D}(C_m)\) là tập các research domains liên kết với pattern \(C_m\) (ví dụ: NLP, Computer Vision, Reinforcement Learning). Với mỗi domain \(d\), hệ thống tính similarity giữa query và domain đó, rồi nhân với weight \(w(d, C_m)\).
Weight \(w(d, C_m)\) là "empirical effectiveness signal" - được tính từ Knowledge Graph dựa trên việc pattern \(C_m\) đã thành công bao nhiêu lần trong domain \(d\). Nếu một pattern đã xuất hiện trong nhiều accepted papers thuộc domain NLP, thì weight của nó cho NLP sẽ cao.
Khác với idea-level, ở đây dùng sum vì một query có thể thuộc nhiều domains cùng lúc (ví dụ: "e-commerce agent" có thể liên quan cả NLP lẫn Recommender Systems), và ta muốn aggregate tất cả signals.
3. Paper-level Retrieval: Papers nào relevant, và chất lượng ra sao?
$$s_{\text{paper}}(C_m \mid q) = \max_{p \in \mathcal{P}(C_m)} \text{sim}_{\text{paper}}(q, p) \cdot \alpha(p)$$
Ký hiệu \(\mathcal{P}(C_m)\) là tập các papers đã instantiate pattern \(C_m\) (tức là papers đã sử dụng methodology tương tự). Với mỗi paper \(p\), hệ thống tính similarity với query, rồi nhân với \(\alpha(p)\) - quality weight của paper đó.
Quality weight \(\alpha(p)\) được derive từ peer review metadata: paper được accept ở venue nào (NeurIPS > workshop), citation count, review scores nếu có. Điều này đảm bảo rằng patterns từ high-quality papers được ưu tiên hơn.
Tại sao cần paper-level khi đã có idea-level? Vì idea-level chỉ capture semantic similarity, còn paper-level thêm dimension "đã được validate trong thực tế chưa". Một idea có thể nghe hay nhưng chưa ai implement thành công. Paper-level score đảm bảo patterns đến từ proven work.
Final Aggregation: Kết hợp cả ba views
$$s(C_m \mid q) = \sum_{v \in \mathcal{V}} \lambda_v \, s_v(C_m \mid q)$$
Với \(\mathcal{V} = {\text{idea}, \text{domain}, \text{paper}}\) và \(\lambda_v\) là các hệ số weighting cố định cho mỗi view.
Final score là weighted sum của cả ba scores. Các hệ số \(\lambda_{\text{idea}}\), \(\lambda_{\text{domain}}\), \(\lambda_{\text{paper}}\) quyết định view nào quan trọng hơn. Paper không specify exact values, nhưng mention rằng chúng là "fixed weighting coefficients" - tức là được tune một lần và giữ cố định, không thay đổi theo từng query.
Tại sao cần ba views? Một ví dụ cụ thể
Để hiểu tại sao cần cả ba views, hãy xem xét query từ paper:
"I want to build an e-commerce agent that can better understand user intent".
Nếu chỉ dùng Idea-level:
Hệ thống sẽ tìm các ideas có semantic similarity cao với "user intent understanding". Có thể trả về pattern về "intent classification in dialogue systems" - nghe có vẻ relevant vì cùng nói về intent. Nhưng pattern này có thể đến từ domain healthcare chatbots, với những assumptions hoàn toàn khác về user behavior so với e-commerce.
Nếu chỉ dùng Domain-level:
Hệ thống sẽ tìm patterns phổ biến trong e-commerce domain. Có thể trả về pattern về "product recommendation" - rất phổ biến trong e-commerce, nhưng không liên quan gì đến intent understanding. Domain match, nhưng idea không match.
Nếu chỉ dùng Paper-level:
Hệ thống sẽ ưu tiên patterns từ high-quality papers (NeurIPS, ICML). Có thể trả về một pattern từ best paper award về "attention mechanisms" - chất lượng cao, nhưng quá general và không specific cho bài toán của user.
Khi kết hợp cả ba:
- Idea-level đảm bảo pattern thực sự về "intent understanding"
- Domain-level đảm bảo pattern applicable cho e-commerce context
- Paper-level đảm bảo pattern đã được validate trong peer-reviewed work
Kết quả: Pattern về "diffusion-based intent modeling for e-commerce" - vừa đúng problem, vừa đúng domain, vừa có foundation từ accepted papers.
Ba views hoạt động như ba bộ lọc chồng lên nhau. Mỗi bộ lọc loại bỏ những candidates không phù hợp ở một khía cạnh khác nhau. Chỉ những patterns pass được cả ba mới có final score cao.
Review-guided Refinement
Sau retrieval, system refine patterns qua review loop:

Rollback mechanism là important. Prevent system từ việc drift vào hướng sai.
Case Study: Cùng input, hai outputs rất khác
Để hiểu rõ sự khác biệt giữa Idea2Story và việc dùng LLM trực tiếp, paper đưa ra một case study rất thú vị. Họ cho cả hai systems cùng một input và so sánh outputs.
Input chung
"I want to build an e-commerce agent that can better understand user intent"
Đây là một research idea khá vague - kiểu idea mà một PhD student có thể pitch với advisor trong buổi meeting đầu tiên. Câu hỏi đặt ra: Hai systems sẽ biến idea mơ hồ này thành research direction cụ thể như thế nào?
Idea2Story sinh ra: IntentDiff
Idea2Story trả về một research pattern có tên "IntentDiff" với approach khá bất ngờ. Thay vì đi theo hướng truyền thống là phân loại intent của user (intent classification), IntentDiff đề xuất một cách nhìn hoàn toàn khác: coi việc hiểu intent như một quá trình tiến hóa cấu trúc (structural evolution process).
Cụ thể, IntentDiff sử dụng diffusion model - một kỹ thuật vốn phổ biến trong image generation - để mô hình hóa cách intent của user "tiến hóa" qua từng bước tương tác. Thay vì nhận một câu text và output một label cứng nhắc, system sẽ iteratively refine understanding về intent qua nhiều bước, giống như cách diffusion model dần dần "khử nhiễu" để tạo ra hình ảnh rõ nét.
Điểm đáng chú ý là IntentDiff không chỉ propose một model mới, mà thay đổi cách đặt vấn đề (problem formulation). Đây là sự khác biệt fundamental: traditional approach coi intent understanding là bài toán classification tĩnh, còn IntentDiff coi nó là bài toán dynamic reasoning.
Direct LLM sinh ra: EcoIntent
Khi cho GPT-4 cùng input mà không qua Knowledge Graph, output là "EcoIntent" - một system theo hướng hoàn toàn khác. EcoIntent đề xuất kết hợp nhiều components đã có sẵn: BERT để encode text, Graph Neural Network để capture quan hệ giữa các entities, và hierarchical contrastive learning để phân biệt các loại intent.
Về bản chất, EcoIntent vẫn giữ nguyên problem formulation truyền thống: nhận input text, output intent label. Điểm "novel" của nó nằm ở việc combine các components mạnh hơn - BERT tốt hơn các encoder cũ, GNN capture được relationships mà MLP không làm được, contrastive learning giúp học representations tốt hơn.
Không có gì sai với approach này. Rất nhiều papers được accept ở top venues theo đúng pattern này: lấy components state-of-the-art, combine một cách thông minh, beat baseline trên benchmark. Đây là incremental innovation, và nó có giá trị.
Sự khác biệt fundamental
Khi đặt hai outputs cạnh nhau, sự khác biệt trở nên rõ ràng:
| Khía cạnh | IntentDiff (Idea2Story) | EcoIntent (Direct LLM) |
|---|---|---|
| Problem formulation | Thay đổi cách đặt vấn đề | Giữ nguyên cách đặt vấn đề |
| Innovation type | Conceptual - "nghĩ khác" | Incremental - "làm tốt hơn" |
| Technical approach | Borrow từ domain khác (diffusion) | Stack components trong cùng domain |
| Risk level | Cao - có thể không work | Thấp - likely sẽ beat baseline |
IntentDiff đặt câu hỏi: "Tại sao chúng ta coi intent understanding là classification? Có cách nào khác không?" Đây là kiểu câu hỏi dẫn đến paradigm shift.
EcoIntent đặt câu hỏi: "Làm sao để classification chính xác hơn?" Đây là kiểu câu hỏi dẫn đến incremental improvement.
Evaluation: Ai thắng?
Paper sử dụng external evaluator (Gemini 2.5 Pro, được giấu không biết output từ system nào) để đánh giá. Kết quả: evaluator consistently đánh giá IntentDiff cao hơn về mặt novelty và potential impact.
Nhưng tôi nghĩ câu trả lời phức tạp hơn nhiều so với việc tuyên bố "Idea2Story thắng".
EcoIntent có những ưu điểm thực tế:
- Dễ implement hơn vì dùng các components đã có sẵn và được hiểu rõ
- Dễ validate hơn vì có thể test trên existing benchmarks
- Dễ publish hơn vì reviewers quen với pattern này
- Lower risk - gần như chắc chắn sẽ có positive results
IntentDiff có potential cao hơn nhưng cũng risky hơn:
- Có thể diffusion không phù hợp cho bài toán này - cần nhiều experiments để validate
- Không có existing benchmark cho "structural evolution of intent"
- Reviewers có thể skeptical vì approach quá khác biệt
- Nếu work, có thể mở ra research direction mới; nếu không, wasted effort
Trong thực tế, một researcher cần cân nhắc cả hai hướng. IntentDiff có thể là moonshot project cho long-term, còn EcoIntent có thể là safe publication để giữ productivity. Việc Idea2Story generate ra IntentDiff cho thấy nó có khả năng propose non-obvious ideas - điều mà direct LLM prompting thường không làm được vì LLM có xu hướng generate "average" của training data.
So sánh với AI Scientist v2: Paradigm khác nhau
| Aspect | AI Scientist v2 | Idea2Story |
|---|---|---|
| Approach | Read papers online mỗi run | Pre-built Knowledge Graph |
| Exploration | Tree search | Pattern retrieval + composition |
| Knowledge | Implicit trong LLM | Explicit trong KG |
| Strength | Flexibility, novelty potential | Efficiency, consistency |
| Weakness | Cost, hallucination | Pattern staleness, coverage gaps |
Tôi thấy gì?
Không phải ai thắng ai thua. Hai philosophies khác nhau:
- v2: "Explore and discover" - fresh exploration mỗi lần, có thể discover novel things, có thể hallucinate
- Idea2Story: "Learn from the best, then adapt" - grounded trong proven work, có thể miss breakthrough ideas
Critical Analysis: Liệu Idea2Story có thực sự giải quyết vấn đề?
Điểm mạnh tôi thấy
- Reduced repeated computation: Literature understanding được pay một lần. Mỗi query sau đó chỉ là retrieval. Make sense về mặt efficiency.
- Explicit và debuggable: Khi output có vấn đề, có thể trace: pattern nào được retrieve? Method units nào được compose? Interpretability tốt hơn black-box reasoning.
- Grounded in peer-reviewed work: Baseline quality cao hơn vì patterns đến từ accepted papers. Không generate from thin air.
Limitations tôi lo ngại
- Pattern staleness: Knowledge Graph built từ 3 năm papers. Trong ML, 3 năm là cả một era. Cần continuous update, nhưng paper không detail mechanism.
- Coverage gaps: What if user's idea không match any existing pattern? Paper không address rõ. Low-confidence retrieval có thể lead to poor output.
- Domain specificity: Chỉ test trên ML papers (NeurIPS/ICLR). Liệu generalize sang biology, physics, social science với different conventions?
- No experiment execution: Idea2Story chỉ generate patterns, không execute experiments. Fair comparison với AI Scientist v2 (which does execute) là không possible.
Broader question: Liệu pattern-based approach có limit innovation?
Đây là câu hỏi tôi nghĩ nhiều nhất sau khi đọc xong paper.
Messeri & Crockett trong Nature 2024 warn:
"Treating AI products as autonomous researchers risks narrowing the scope of research to questions suited for AI."
Nếu Idea2Story chỉ compose từ existing patterns, liệu có discover được paradigm-shifting ideas?
Hay nói cách khác: Attention mechanism, transformer architecture - những breakthrough này có fit vào pattern-based approach không?
Tôi không có answer, nhưng đây là important question cho future work.
Kết luận của tôi
Những gì tôi học được
- Runtime-centric có fundamental bottleneck: Context window + repeated reasoning = high cost, hallucination risk. Paper convince tôi về problem identification.
- Pre-computation là viable alternative: Trade flexibility cho consistency. Không better hay worse, khác.
- Method Unit extraction là clever: Tách methodology khỏi implementation để enable reuse. Có thể apply beyond autonomous research.
- Explicit KG > Implicit LLM knowledge trong một số contexts, đặc biệt khi cần interpretability.
Prediction của tôi
Nếu bạn hỏi approach nào sẽ "thắng" dài hạn, tôi nghĩ: cả hai sẽ merge.
- Idea2Story đúng: runtime reasoning quá tốn kém và không stable
- AI Scientist v2 đúng: pure pattern composition có thể miss breakthrough
Future có lẽ là hybrid: Knowledge Graph làm foundation, tree search cho exploration beyond existing patterns khi cần.
Điều tôi appreciate nhất
Không phải technical contribution cụ thể, mà là việc paper force suy nghĩ lại fundamental assumptions.
Đôi khi "smarter reasoning" không phải câu trả lời. "Better knowledge organization" mới là.
Sources
Primary:
- Xu, T., Qian, Z., Liu, G., et al. (2026). "Idea2Story: An Automated Pipeline for Transforming Research Concepts into Complete Scientific Narratives." arXiv:2601.20833v1.
Related Work:
- Lu, C., et al. (2024). "The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery." arXiv:2408.06292.
- Yamada, Y., et al. (2025). "The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search." arXiv:2504.08066.
- "Evaluating Sakana's AI Scientist" (2025). arXiv:2502.14297.
Critical Perspectives:
- Messeri, L. & Crockett, M.J. (2024). "Artificial intelligence and illusions of understanding in scientific research." Nature.
Code:
- GitHub: AgentAlphaAGI/Idea2Paper