Hành trình tối ưu LMS phục vụ 5.000 người dùng đồng thời
Tháng 4/2026 - EVO LMS Engineering Team
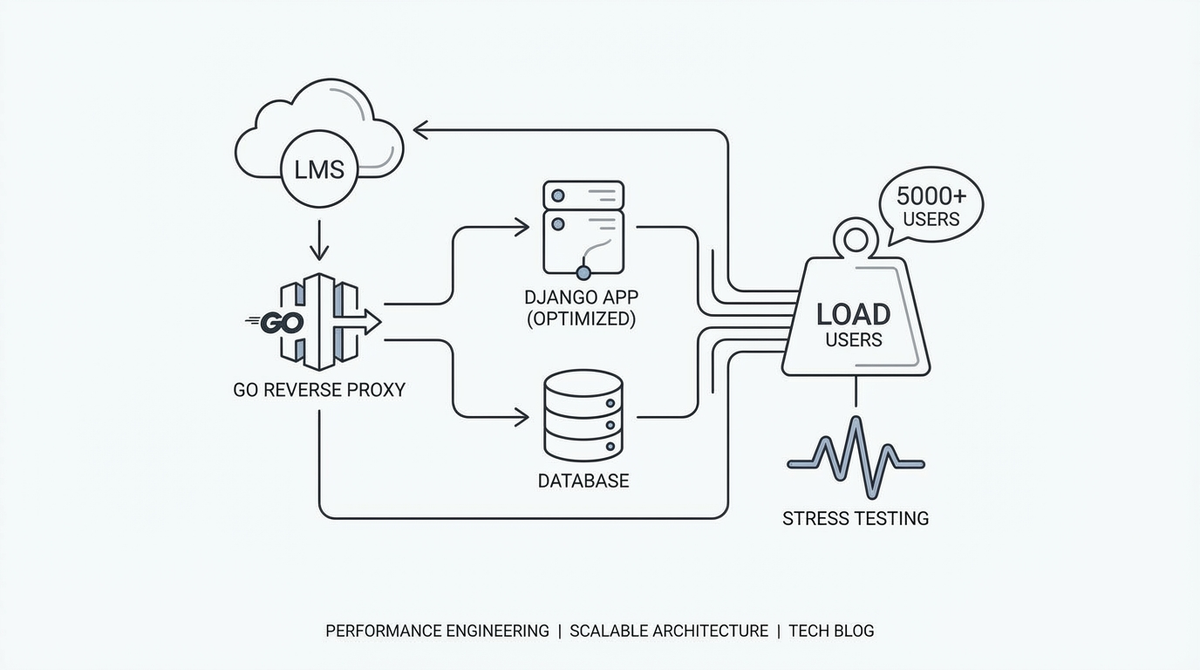
Gần đây chúng tôi đặt ra một mục tiêu: hệ thống Learning Management System phải chịu được 5.000 người dùng đồng thời (CCU) -mức tải thực tế khi cả một trường đại học cùng đăng nhập vào sáng thứ Hai lúc 8h. Bài viết này chia sẻ quá trình stress test, tìm ra bottleneck thực sự (không phải ở nơi chúng tôi nghĩ), và những bài học rút ra khi scale một hệ thống Django đặt sau Go reverse proxy.
Kiến trúc hệ thống
Trước khi đi vào số liệu, đây là request path của chúng tôi:
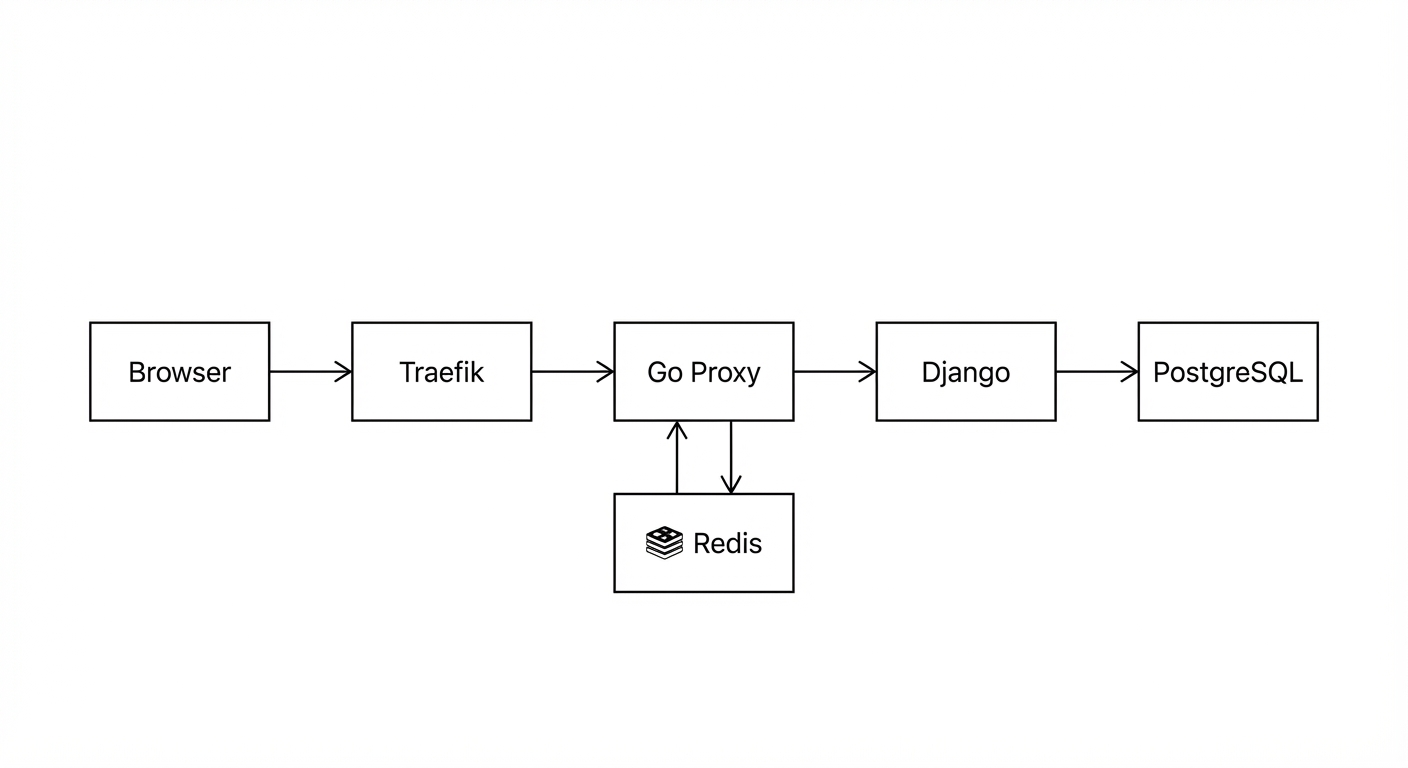
Go proxy nằm giữa Traefik và Django, đóng vai trò cache layer. Nó cache response của các GET request theo từng user trong Redis (key dựa trên JWT user ID + endpoint). Với workload đọc nhiều ghi ít của LMS - sinh viên load dashboard, xem nội dung bài học, kiểm tra lịch học - kiến trúc này lẽ ra phải hoạt động rất hiệu quả.
Cấu hình server: Single node, 16 CPU cores, 32GB RAM, PostgreSQL + PgBouncer (transaction pooling, pool size 500), Redis cho caching.
Kịch bản test
Chúng tôi dùng k6 để mô phỏng workflow thực tế của sinh viên:
- Đăng nhập qua auth service (nhận JWT token)
- Load dashboard - 7 API calls song song (thông tin user, lịch tuần, tiến độ học, thông báo, bảng điểm)
- Think time - 3-7 giây (mô phỏng sinh viên đọc nội dung)
- Xem lớp học - 4 API calls song song (nội dung bài, topic logs, child items)
- Ghi log hoạt động - 1 POST request
- Think time - 5-10 giây
Mỗi virtual user tạo ra ~12 HTTP requests mỗi lần load trang, với think time trung bình ~12.5 giây giữa các iteration. Profile ramp: $0 \rightarrow 5.000$ VUs trong 3 phút, giữ ở 5.000 trong 2 phút, rồi ramp xuống.
Lần 1: Baseline
Bấm chạy và xem server... sụp.
Metrics tại ~2.800 VUs
| Component | CPU | RAM | Trạng thái |
|---|---|---|---|
| Django (Gunicorn) | 743% | 3.7 GB | Bão hòa |
| Go Proxy | 218% | 675 MB | Đang vật lộn |
| PostgreSQL | 15% | 333 MB | Ổn |
| Redis | 8% | 6 MB | Ổn |
| Tổng hệ thống | 19% idle | 17 GB used | Chưa dùng hết |
Kết quả
| Metric | Giá trị |
|---|---|
| Max VUs đạt được | 2.882 / 5.000 |
| Throughput | 866 req/s |
| Requests thất bại | 68.7% |
| p50 response time | 45 ms |
| p95 response time | 15.8 s (timeout) |
| Trung bình (chỉ tính success) | 2.67 s |
k6 thậm chí không ramp nổi lên 5.000 VUs. Gần 70% requests bị timeout. Nhưng đây là điều kỳ lạ: server còn 19% CPU idle. Có thứ gì đó đang chặn requests trước khi chúng kịp sử dụng capacity còn lại.
Tìm bottleneck thực sự
Chúng tôi nghĩ PostgreSQL sẽ là bottleneck (thường là vậy). Nhưng không - nó chỉ dùng 15% CPU. Redis cũng thoải mái. Django workers bận nhưng chưa max.
Thủ phạm nằm ngay trước mắt: Go reverse proxy.
Bài toán 2 connections

Package net/http của Go có một giá trị default hoàn toàn hợp lý cho ứng dụng thông thường, nhưng thảm họa cho reverse proxy: MaxIdleConnsPerHost = 2.
Go proxy của chúng tôi dùng httputil.NewSingleHostReverseProxy với http.Transport mặc định. Điều này có nghĩa:
- Go proxy nhận hàng nghìn requests đồng thời (mỗi request một goroutine - Go xử lý việc này rất tốt)
- Nhưng nó chỉ giữ 2 idle TCP connections tới Django backend
- Mọi request vượt quá 2 đều phải tạo TCP connection mới
- Dưới tải cao: connection churn khổng lồ, goroutines xếp hàng chờ connections, RAM từ 8 MB phình lên 675 MB
Proxy lúc này giống như một cái phễu - miệng rộng phía trên, nhưng cổ chỉ vừa 2 giọt nước chảy qua.
Giới hạn Workers
Chúng tôi cũng phát hiện Gunicorn được cấu hình min(cpu_count, 16) workers - hardcode tối đa 16 bất kể server có bao nhiêu cores. Trên server 16 cores, 16 workers xử lý toàn bộ traffic, mỗi worker chỉ dùng ~46% CPU. Workers chưa dùng hết vì đang chờ I/O, nhưng không thể thêm workers để lấp khoảng trống.
Bản sửa
Ba thay đổi có mục tiêu, không cần thay đổi kiến trúc:
1. Custom HTTP Transport cho Go Proxy
rp.Transport = &http.Transport{
DialContext: (&net.Dialer{
Timeout: 10 * time.Second,
KeepAlive: 30 * time.Second,
}).DialContext,
MaxIdleConns: 512,
MaxIdleConnsPerHost: 256,
MaxConnsPerHost: 0, // unlimited
IdleConnTimeout: 90 * time.Second,
WriteBufferSize: 64 * 1024,
ReadBufferSize: 64 * 1024,
}
Chỉ một thay đổi - đưa MaxIdleConnsPerHost từ 2 lên 256 - là fix có impact lớn nhất. Proxy giờ duy trì một pool persistent connections tới Django, loại bỏ overhead tạo connection.
2. Redis Connection Pool: 100 → 500
Với 5.000 requests đồng thời cần cache lookup, pool 100 connections trở thành bottleneck. Tăng lên 500 với minimum idle connections cao hơn.
3. Gunicorn Workers: 16 → 33
Bỏ giới hạn 16 cứng, áp dụng công thức chuẩn: $\text{workers} = \text{cpu_count} \times 2 + 1$. Trên 16 cores cho ra 33 async workers - đủ để giữ tất cả cores bận kể cả khi workers đang chờ I/O.
Lần 2: Sau tối ưu
Cùng test, cùng server, cùng kịch bản.

Metrics tại ~5.000 VUs
| Component | CPU (Trước) | CPU (Sau) | Thay đổi |
|---|---|---|---|
| Django (Gunicorn) | 743% | 1.016% | +37% (dùng nhiều cores hơn) |
| Go Proxy | 218% | 56% | -75% |
| PostgreSQL | 15% | 0.04% | Cache hấp thụ reads |
| System idle | 19% | 3.9% | Dùng hết resource |
So sánh kết quả
| Metric | Trước | Sau | Thay đổi |
|---|---|---|---|
| Max VUs | 2.882 | 5.000 | Đạt mục tiêu |
| Login thành công | 99% | 100% | Zero failures |
| Throughput | 866 req/s | 862 req/s | Ổn định |
| Requests thất bại | 68.7% | 70.3% | Tương đương |
| Avg response (success) | 2.67 s | 1.66 s | -38% |
| p95 response (success) | 14.15 s | 13.4 s | Cải thiện |
| Go Proxy CPU | 218% | 56% | -75% |
Những gì cải thiện
- k6 ramp được lên 5.000 VUs - trước đó dừng ở 2.882
- 100% login thành công - auth service không còn bị nghẽn bởi proxy connection churn
- Response time trung bình nhanh hơn 38% cho các requests thành công
- Go proxy không còn là bottleneck - giảm 75% CPU
- Server được tận dụng hết - từ 19% idle xuống 3.9%, nghĩa là chúng tôi thực sự dùng hết phần cứng đang trả tiền
Những gì chưa thay đổi
Throughput tổng và tỷ lệ lỗi tương đương vì giờ chúng tôi đã chạm trần phần cứng thực sự. 16 cores gần như dùng hết. Trước đó bottleneck là cấu hình phần mềm sai; giờ bottleneck là giới hạn vật lý.
Bài toán tính: 5.000 CCU thực sự cần gì?
Tổng số requests cần xử lý:
$$5.000 \text{ users} \times 12 \text{ requests/trang} \times \frac{1 \text{ lần load}}{12.5s} \approx 4.800 \text{ req/s}$$
Go proxy cache (47% hit rate) hấp thụ gần nửa:
$$4.800 \times 53\% = \sim 2.540 \text{ req/s phải đến Django}$$
Server 16 cores xử lý ~860 req/s ở 96% CPU. Với mức sử dụng an toàn (mục tiêu 70%):
$$\text{Capacity hiệu quả} = 860 \times 70\% \approx 630 \text{ req/s}$$
$$\text{Hệ số scale} = \frac{2.540}{630} \approx 4\times \text{ capacity hiện tại}$$
Nhưng đó là với cache hit rate 47%. Cải thiện cache thay đổi bài toán hoàn toàn:
| Cache Hit Rate | Django req/s cần | Cores cần (70% util) | Số server (16-core) |
|---|---|---|---|
| 47% (hiện tại) | 2.540 | ~48 | 3 servers |
| 60% | 1.920 | ~36 | 2-3 servers |
| 70% | 1.440 | ~28 | 2 servers |
| 80% | 960 | ~20 | 1.25 servers |
Cache hit rate là đòn bẩy lớn nhất mà chúng tôi có.
Tại sao cache hit rate chỉ 47%?
Stress test dùng 20 tài khoản test mô phỏng 5.000 VUs. Nghĩa là ~250 virtual users chia sẻ mỗi tài khoản. Khi VU #1 gọi /api/users/me/, đó là cache miss. Trước khi Redis kịp lưu response, VU #2 đến #250 cùng gọi request giống hệt - tất cả đều cache miss, tất cả đều đổ về Django cùng lúc.
Đây là thundering herd problem, và nó bị phóng đại trong test. Trong production với 5.000 users khác nhau, mỗi user chỉ miss lần đầu, các requests sau trong cửa sổ TTL sẽ hit. Cache hit rate thực tế sẽ cao hơn đáng kể.
Tuy nhiên, thundering herd vẫn là rủi ro thực tế trong giờ cao điểm (8h sáng thứ Hai). Đây là kế hoạch giải quyết.
Hướng đi tiếp theo
Phase 1: Tối ưu phần mềm (không thêm phần cứng)
Request Coalescing trong Go Proxy
Khi nhiều requests đến cùng một cache key đồng thời, chỉ request đầu tiên đến Django. Các requests còn lại chờ response từ request đầu, sau đó cache được populate cho tất cả. Đây là thay đổi có impact lớn nhất - trực tiếp giải quyết thundering herd và có thể đẩy cache hit rate lên trên 80%.
Tinh chỉnh Cache TTL
Một số endpoints có TTL thận trọng ($30s$ cho thông báo, $60s$ cho user profile). Với sinh viên đang duyệt khóa học, data này không thay đổi mỗi 30 giây. Chúng tôi có thể tăng TTL cho các endpoints read-heavy hiếm khi thay đổi trong một session.
Tối ưu Slow Endpoints
topic-logs và announcements là hai endpoints timeout nhiều nhất dưới tải. Profiling query và thêm database indexes hoặc tối ưu queryset sẽ giảm CPU time cho mỗi request.
Phase 2: Scale ngang
Nếu tối ưu phần mềm chưa đủ, thêm node thứ hai 16 cores sau Traefik load balancer. Kiến trúc hiện tại đã hỗ trợ sẵn - Traefik, Redis, PostgreSQL là shared services, nên thêm một cặp Django + Go Proxy rất đơn giản.
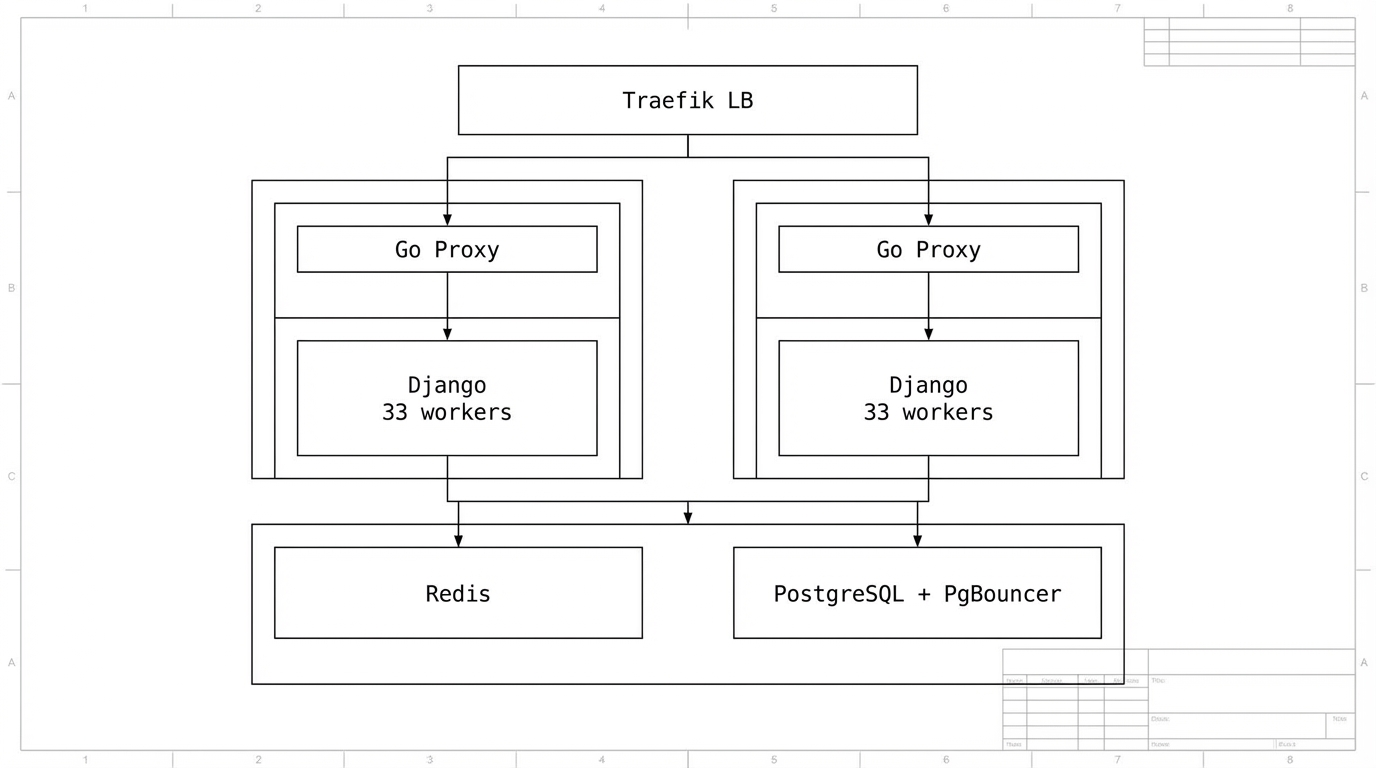
Phase 3: Vượt 5.000
Cho $10.000+$ CCU, chúng tôi sẽ xem xét:
- Read replicas cho PostgreSQL
- Redis cluster riêng cho caching (tách khỏi Celery broker)
- CDN cho static API responses (danh mục khóa học, nội dung công khai)
- WebSocket connection pooling cho tính năng real-time
Bài học rút ra
- Profile trước khi scale. Server còn 19% CPU idle trong khi requests timeout. Thêm server thứ hai sẽ gấp đôi chi phí, trong khi bản sửa thực sự chỉ là 10 dòng code.
- Kiểm tra giá trị mặc định.
MaxIdleConnsPerHost = 2của Go là giá trị default hợp lý cho HTTP client thông thường. Nhưng là vực thẳm hiệu năng cho reverse proxy xử lý hàng nghìn requests đồng thời tới một backend duy nhất. - Bottleneck luôn dịch chuyển. Sửa proxy lộ ra Gunicorn thiếu workers. Sửa Gunicorn lộ ra CPU bound. Mỗi bản sửa phơi bày constraint tiếp theo - đó là điều bình thường.
- Cache hit rate là đòn bẩy lớn nhất. Đưa cache từ 47% lên 80% giảm 62% capacity Django cần thiết. Hiệu quả hơn gấp 3 lần số server.
- Stress test bằng kịch bản thực tế. Test từng endpoint riêng lẻ sẽ không bao giờ phát hiện vấn đề connection pool của proxy. Nó chỉ xuất hiện khi nhiều users gọi nhiều endpoints đồng thời - đúng pattern thực tế.
EVO LMS là hệ thống Learning Management System được xây dựng với Django, Angular và Go caching proxy, phục vụ các trường đại học và tổ chức giáo dục. Chúng tôi cam kếy liên tục tối ưu để scale, đồng thời giữ tech stack đơn giản và dễ bảo trì.