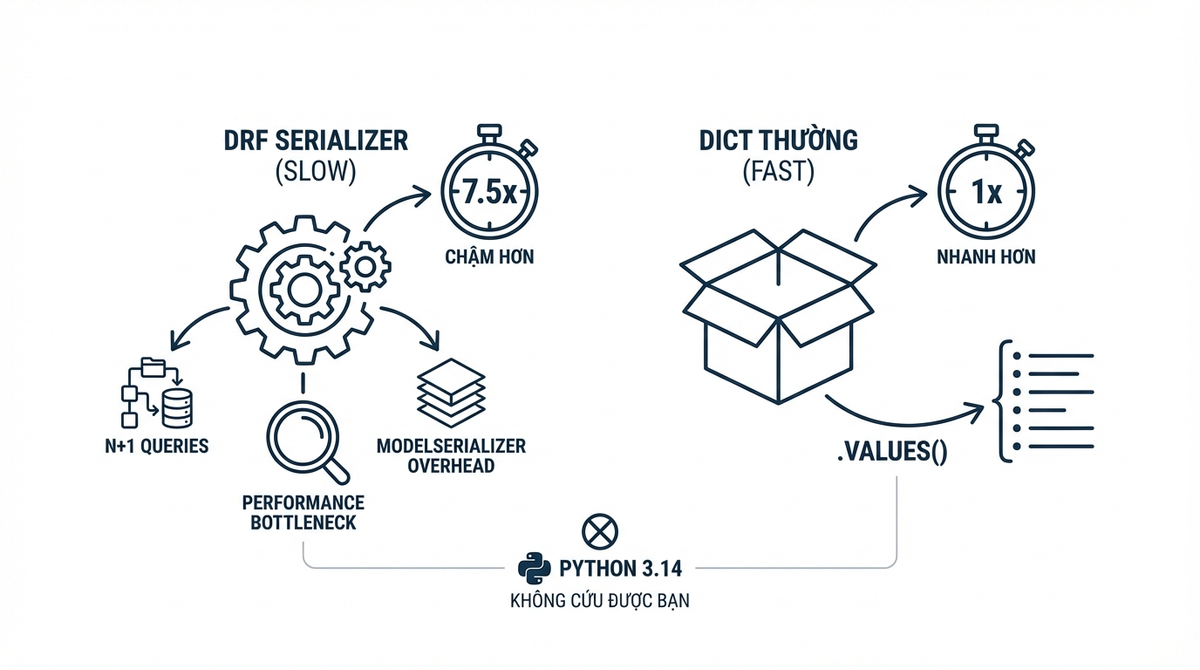
DRF Serializer chậm hơn dict thường 7.5 lần - và Python 3.14 không cứu được bạn
Benchmark thực tế: ModelSerializer chậm hơn manual dict 7.5x, .values() nhanh hơn 20x. Python 3.14 chỉ tăng 1-3% cho Django. Optimize đúng chỗ trước khi migrate framework.
Thật lòng mà nói, mình đã tin DRF chậm suốt gần hai năm. Tin theo kiểu tin-không-nghĩ-lại - mỗi lần ai đó ở meetup hỏi "sao API Django chậm thế", câu trả lời mặc định trong đầu mình là "ừ, DRF mà, ai cũng biết". Mình repeat câu đó đủ nhiều lần để nó thành một fact trong đầu, chứ không phải một giả thuyết cần kiểm chứng.
Cho đến tuần trước.
CỤ THỂ LÀ NÓ CHẬM ĐẾN MỨC NÀO ?
Tuần trước mình ngồi profile một Django REST Framework API đang serve 200K requests/ngày. Response time trung bình 800ms cho list endpoint trả về 100 products. Team đã thử đủ mọi cách: tăng Gunicorn workers, thêm RAM, bump instance size trên AWS. Hóa đơn EC2 tháng trước nhảy 40% nhưng latency không nhúc nhích một millisecond. Tới chiều thứ năm, mình đã sẵn sàng nói với team "chắc tới lúc nghĩ đến FastAPI rồi" - câu nói mà mọi Django dev đều biết nó có nghĩa là "bỏ 3-6 tháng viết lại mọi thứ".
Rồi mình thay một dòng code. Response time giảm từ 800ms xuống 200ms.
Dòng code đó không phải cache. Không phải index. Không phải async. Mình chỉ đổi từ ModelSerializer sang Serializer - và bỗng dưng app nhanh gấp 4 lần mà không tốn thêm một đồng EC2 nào. Nhanh hơn gấp 4 lần. Bằng một dòng. Sau khi mình đã nghi ngờ framework gần hai năm.
Cảm giác lúc đó không phải eureka. Nó khó chịu hơn thế. Nó là cái cảm giác bạn nhận ra mình đã bludgeon một vấn đề bằng sai công cụ suốt một năm rưỡi, và suốt thời gian đó vấn đề không phải ở framework - mà ở chính giả định của mình về framework. Mình tắt laptop, đi pha trà, và tự hỏi: nếu mình sai về chuyện này, mình còn đang sai về cái gì nữa?
Câu hỏi đó ngứa đủ lâu để mình bỏ cuối tuần ra build một benchmark suite chạy trên Docker - test 7 phương pháp serialization, 3 chiến lược query optimization, pagination, caching, tất cả trên cùng một dataset realistic. Không phải vì mình muốn viết một bài "DRF vs FastAPI". Mà vì mình muốn biết chính xác mình đã sai ở chỗ nào.
Kết quả là một tập data khiến mình phải viết lại cách mình nghĩ về performance trong Django - và mình nghĩ nó cũng có thể làm bạn viết lại cách bạn nghĩ. Nếu phải gói cái mình học được vào một câu, thì câu đó là thế này: DRF không chậm. ModelSerializer mới chậm. Và phần lớn cái mà mọi người gọi là "performance problems của DRF" có thể fix trong một buổi chiều - nếu bạn chịu đo đúng chỗ thay vì đổi framework.
Chỗ đầu tiên mình đào: ModelSerializer, con quái vật ai cũng nuôi
Mình quyết định bắt đầu từ chỗ đau nhất - chính cái ModelSerializer mà mình đã thay đi. Setup một Django project với data model đủ realistic để không bị accuse là cherry-pick:
Product → Category (FK, self-referential parent)
Product → Tags (M2M)
Product → Images (reverse FK, 3 per product)
Product → Reviews (reverse FK, 5 per product)
10,000 products, 50,000 reviews, 30,000 images - đủ realistic cho một e-commerce API. Mỗi product được serialize với 2-3 level nesting: category có parent, images sorted by order, reviews sorted by date.
In-process trước, HTTP tính sau
Đầu tiên mình muốn loại bỏ hoàn toàn HTTP overhead - vì nếu mình đo qua Gunicorn thì sẽ không biết bao nhiêu phần trăm latency là của serializer và bao nhiêu là của network stack. Load 100 products vào memory, đo thuần thời gian serialization:
| Serializer | Avg (ms) | P95 (ms) | So với nhanh nhất |
|---|---|---|---|
| Manual Dict | 2.53 | 3.09 | 1.0x (baseline) |
| Serpy | 3.56 | 3.95 | 1.4x |
DRF Serializer (plain) |
17.21 | 20.51 | 6.8x |
DRF ModelSerializer (read-only) |
18.64 | 21.54 | 7.4x |
DRF ModelSerializer (writable) |
18.88 | 24.41 | 7.5x |
Benchmark: 50 iterations, 100 objects/iteration, Django 5.2, Python 3.13, PostgreSQL 16. Source code
Đọc kỹ bảng này. ModelSerializer mất 18.88ms để serialize 100 objects. Manual dict mất 2.53ms. Cùng data, cùng output, cùng Python version - chỉ khác cách build response. Gap là 7.5 lần.
Lần đầu nhìn con số này mình đã reload lại benchmark ba lần vì không tin. Không phải vì 7.5x là số lớn - mà vì khoảng cách giữa Serializer (plain, 17.21ms) và ModelSerializer (18.88ms) lại nhỏ đến thế. Mình đã expect Serializer phải nhanh hơn ModelSerializer vài lần vì nó không có model binding. Nhưng không - nó chỉ nhanh hơn ~10%. Điều đó nghĩa là bottleneck không nằm ở chỗ mình từng đoán. Nó không phải model introspection.
Nó nằm ở một chỗ tinh vi hơn: field initialization overhead.
Tại sao DRF chậm - và tại sao mình đoán sai
Mỗi khi bạn gọi ProductSerializer(queryset, many=True), DRF không chỉ iterate qua data và map fields. Nó làm một loạt việc mà phần lớn bạn không cần đến - và đây là những thứ mình đã phải đọc source code DRF để hiểu:
1. Field binding on every instance. DRF tạo lại field instances cho MỖI object trong queryset. 100 products × 14 fields = 1,400 field instantiations. Mỗi field chạy qua __init__, validators, source resolution. Đây là chi phí O(n × fields) mà manual dict không có.
2. Validator chain. Ngay cả khi bạn đọc data (GET request), ModelSerializer vẫn setup validators cho write operations. UniqueValidator cho slug, MaxLengthValidator cho name - tất cả được instantiate dù không bao giờ chạy.
3. Django lazy() bug. Một bug đã được fix trong Django cho thấy lazy() function tạo 33.5x performance penalty cho string operations trong serializers. Nếu bạn chạy Django < 5.0, bạn đang chịu penalty này mà không biết.
4. Nested serializer multiplier. Mỗi nested serializer (CategorySerializer bên trong ProductSerializer) nhân đôi overhead trên. Product có 4 nested serializers (category, tags, images, reviews) → mỗi product không phải 14 field inits mà là 14 + 4 + 2 + 5 + 7 = 32 field inits.
Serpy giải quyết vấn đề này bằng cách compile field access tại class definition time thay vì instance time. Manual dict bypass hoàn toàn - bạn chỉ access attributes trực tiếp.
Điều mình thấy nhói là cái thứ 2: validator chain cho write operations chạy ngay cả khi GET. Bạn đọc data read-only, nhưng server của bạn vẫn đang âm thầm setup UniqueValidator cho từng record. Đó là tiền bạn trả cho một feature bạn không bao giờ dùng trên endpoint đó.
Lab đẹp, thế giới thực thì sao?
Mình biết in-process benchmark dễ bị nghi ngờ - "nhưng production code chạy qua Gunicorn + network, số đó không count". Fair. Nên mình setup HTTP benchmark luôn, dùng hey load generator (30 concurrent connections, 3000 requests per run, 3 repetitions lấy median) trên Docker với CPU/memory limits (2 cores, 2GB RAM). PostgreSQL chạy cùng Docker network (latency ~0.5ms), gần giống setup production trên cùng VPC.
Quan trọng: tất cả HTTP benchmarks dùng optimized queryset (select_related + prefetch_related) - chỉ 5 SQL queries bất kể limit. Điều này isolate serializer overhead khỏi N+1 problem.
Giải thích các methods:
- ModelSerializer (writable): serializers.ModelSerializer mặc định - auto-generate fields + validators từ model
- ReadOnly ModelSerializer: Cùng ModelSerializer nhưng tất cả fields đều read_only=True - skip validator setup
- Serializer (plain): serializers.Serializer - khai báo fields thủ công, không có model binding
- Serpy: Thư viện thay thế, compiled field access tại class definition time
Đây là full results - 4 serializer types, 4 payload sizes, Gunicorn 4 sync workers:
limit=1 object (single product with nested relations):
| Method | RPS | Avg Latency | P95 Latency | vs ModelSerializer |
|---|---|---|---|---|
| Serpy | 483 | 62ms | 85ms | 7.8x nhanh hơn |
DRF Serializer (plain) |
385 | 77ms | 97ms | 6.2x |
| DRF ReadOnly ModelSerializer | 313 | 95ms | 128ms | 5.0x |
| DRF ModelSerializer (writable) | 62 | 478ms | 856ms | 1.0x (baseline) |
Chỉ 1 object - một object duy nhất - và khoảng cách đã gần 8 lần giữa Serpy và ModelSerializer writable. Mình đọc lại bảng này mấy lần để chắc chắn mình không nhầm column. Một request, một product, mà ModelSerializer mất trung bình 478ms, P95 856ms. Đây là với queryset đã được optimize hoàn hảo bằng select_related + prefetch_related - nghĩa là SQL chỉ 5 queries, toàn bộ phần còn lại là Python. Nửa giây của một request đi qua một serializer cho một object. Nếu bạn chưa bao giờ đo, đây chính là lý do hóa đơn EC2 của team bạn cứ tăng đều đều mỗi quý.
limit=10 objects:
| Method | RPS | Avg Latency | P95 Latency | vs ModelSerializer |
|---|---|---|---|---|
| Serpy | 258 | 115ms | 175ms | 6.5x |
DRF Serializer |
213 | 140ms | 183ms | 5.3x |
| DRF ReadOnly | 188 | 158ms | 193ms | 4.7x |
| DRF ModelSerializer | 40 | 745ms | 1,316ms | 1.0x |
limit=100 objects:
| Method | RPS | Avg Latency | P95 Latency | vs ModelSerializer |
|---|---|---|---|---|
| Serpy | 56 | 536ms | 682ms | 3.5x |
DRF Serializer |
40 | 747ms | 854ms | 2.5x |
| DRF ReadOnly | 39 | 770ms | 892ms | 2.4x |
| DRF ModelSerializer | 16 | 1,897ms | 2,187ms | 1.0x |
Ở 100 objects, ModelSerializer mất gần hai giây mỗi request. Hai giây. Cho một list endpoint. Serpy vẫn giữ gap 3.5x nhưng mình chú ý thấy plain Serializer và ReadOnly bắt đầu converge - cả hai đều bị dominate bởi field processing overhead khi volume lên cao. Đây là chi tiết mà benchmark ở nhỏ không cho bạn thấy.
limit=500 objects - chỗ mọi thứ bắt đầu hội tụ:
| Method | RPS | Avg Latency | vs ModelSerializer |
|---|---|---|---|
| Serpy | 12 | 2,431ms | 1.5x |
DRF Serializer |
9 | 3,457ms | 1.1x |
| DRF ReadOnly | 9 | 3,506ms | 1.1x |
| DRF ModelSerializer | 8 | 3,512ms | 1.0x |
Đây là chỗ mình phải đổi cách nghĩ. Ở payload lớn, mọi DRF variant đều converge về ~3.5 giây. Không phải vì serializer tốt lên - mà vì bottleneck đã chuyển hoàn toàn sang database I/O, JSON encoding, và network. Ở scale này, optimize serializer không còn nhiều ý nghĩa; bạn phải optimize tầng bên dưới. Chỉ Serpy giữ được lead 50% nhờ compiled field access.
Nhưng trong lúc so sánh các DRF variants với nhau, mình đã gần như bỏ qua một thứ khác - một phương pháp mà không cuốn tutorial DRF nào mình từng đọc nhắc đến như một optimization nghiêm túc. Và cái đó mới là con số làm mình phải đứng dậy đi lại trong phòng mất 5 phút.
.values() - thứ nhanh nhất mà không ai nói với mình
.values() bypass hoàn toàn Python object creation. Không có Model instance, không có Field binding, không có Serializer. Database driver trả thẳng dicts:
| limit | .values() RPS |
ModelSerializer RPS | Gap |
|---|---|---|---|
| 1 | 1,262 | 62 | 20x |
| 10 | 1,133 | 40 | 28x |
| 100 | 452 | 16 | 28x |
| 500 | 191 | 8 | 24x |
Đọc lại giùm mình: 1,262 requests per second so với 62. Hai mươi lần. Và ở 500 objects, khi mọi serializer khác đang lê lết ở 8-12 rps và mất 2.5-3.5 giây mỗi request, .values() vẫn xử lý 191 rps với latency 156ms. Vì nó không tạo 500 Product instances, không bind 32 fields cho mỗi instance, không chạy qua serializer pipeline. Nó hỏi PostgreSQL "cho mình mấy cột này" và trả thẳng kết quả thành dicts.
Mình ngồi nhìn con số 1,262 khá lâu và tự nghĩ: tại sao suốt ba năm làm Django mình chưa bao giờ nghĩ đến cái này? Câu trả lời hơi bẽ bàng - vì mọi tutorial DRF đều dạy bạn serializer-first, mọi stackoverflow answer đều là "use a serializer", và cái tool duy nhất trong tay bạn là một cái búa tên ModelSerializer. Khi mọi thứ trông giống đinh, bạn sẽ không bao giờ nghĩ đến việc bỏ búa xuống.
Trade-off: .values() không support nested relations (tags, images, reviews) hay computed fields. Nó phù hợp nhất cho list endpoints cần flat data - product catalogs, search results, dropdowns, autocomplete.
Full Comparison Table (tất cả methods, tất cả sizes)
| Method | 1 obj | 10 obj | 100 obj | 500 obj |
|---|---|---|---|---|
.values() |
1,262 | 1,133 | 452 | 191 |
| Manual Dict | 505 | 291 | 57 | 12 |
| Dict + orjson | 498 | 287 | 60 | 13 |
| Serpy | 483 | 258 | 56 | 12 |
| django-ninja (Pydantic) | 451 | 242 | 45 | 10 |
| DRF Serializer | 385 | 213 | 40 | 9 |
| DRF ReadOnly | 313 | 188 | 39 | 9 |
| DRF ModelSerializer | 62 | 40 | 16 | 8 |
(Đơn vị: requests/second. Gunicorn 4 workers, 2 CPU, 2GB RAM, 30 concurrent connections)
Pattern rõ ràng: có 3 tiers performance - .values() (tier 1, bypass everything), Dict/Serpy (tier 2, bypass DRF), DRF variants (tier 3). Và khoảng cách giữa tier 1 và tier 3 là 20-28 lần.
Insight: Serializer optimization matters nhất ở small-to-medium payloads (1-100 objects). Sau 200+ objects, Dict/Serpy converge với DRF vì data volume dominate. Nhưng .values() duy trì advantage ở MỌI scale vì nó eliminate cả object creation lẫn serialization.
Chỗ thứ hai mình đào: N+1 query, kẻ giết người thầm lặng
Nếu serializer là nơi đau nhất khi mình nhìn thấy, thì N+1 query là nơi đau nhất khi mình không nhìn thấy. Mình đã viết Django ba năm và vẫn quên prefetch_related ít nhất một lần mỗi tháng - thường là ở một endpoint mình tưởng mình đã optimize rồi. Cái đáng sợ của N+1 là nó không crash, không throw error, không show trong log. Nó chỉ làm mọi thứ chậm dần đều, theo cách mà bạn đổ lỗi cho "scale" thay vì cho chính mình.
Mình setup 3 endpoint trả về cùng một data, chỉ khác queryset strategy:
# Naive: Product.objects.all()
# Select: Product.objects.select_related('category', 'category__parent')
# Prefetch: select_related + prefetch_related('tags', 'images', 'reviews')
Đếm query - và giật mình
Mình capture query count qua X-Query-Count response header:
| Strategy | limit=10 | limit=50 | limit=100 |
|---|---|---|---|
| Naive (N+1) | 50 queries | 244 queries | 479 queries |
| select_related only | 31 queries | 151 queries | 301 queries |
| Full prefetch | 4 queries | 4 queries | 4 queries |
479 SQL queries cho một request trả về 100 products. Bốn trăm bảy chín. Mỗi product trigger khoảng 4 lazy queries - tags, images, reviews, category parent - và Python + ORM + network round-trip với PostgreSQL cộng dồn thành một bữa ăn miễn phí cho latency.
Lần đầu mình hiểu ra N+1 thực sự là gì (không phải đọc definition trong textbook, mà là nhìn thấy nó trên query log của chính mình) là một buổi tối ở startup cũ, năm 2022. Tụi mình đang chạy một endpoint admin dashboard mà PM complain là "chậm", và mình assumed là do query phức tạp. Mở django-debug-toolbar ra - 1,200 queries cho một trang. Một nghìn hai trăm. Cảm giác lúc đó y như bạn thấy một cục nợ mà bạn không biết mình đang nợ.
Full prefetch luôn 4 queries bất kể bạn fetch 10 hay 1000 products: 1 cho products (với category JOIN), 1 cho tags (through M2M), 1 cho images, 1 cho reviews. select_related giảm xuống 301 queries ở limit=100 nhưng vẫn O(n) vì reverse FK và M2M vẫn lazy load.
Response Time Impact (HTTP Benchmark)
| Strategy | limit=10 (RPS / Avg) | limit=50 (RPS / Avg) | limit=100 (RPS / Avg) |
|---|---|---|---|
| N+1 naive | 60 rps / 166ms | 14 rps / 737ms | 7 rps / 1,439ms |
| select_related only | 81 rps / 122ms | 19 rps / 522ms | 10 rps / 1,020ms |
| select + prefetch | 189 rps / 53ms | 69 rps / 143ms | 39 rps / 257ms |
Ở 100 objects: từ 1,439ms xuống 257ms - nhanh hơn 5.6 lần chỉ bằng 3 dòng code. Throughput tăng từ 7 rps lên 39 rps. Nếu bạn đang serve 200K requests/ngày mà chưa có prefetch, bạn đang waste 80% capacity của server.
Chú ý: select_related alone chỉ giúp 30% (7→10 rps ở limit=100) vì nó chỉ giải quyết FK relationship (category). Reverse FK (images, reviews) và M2M (tags) vẫn lazy load - bạn PHẢI thêm prefetch_related để cover chúng.
Tự Động Hóa: django-auto-prefetching
Nếu bạn quản lý 50+ ViewSets và không muốn manually setup eager loading cho từng cái, django-auto-prefetching tự động inspect serializer fields và tính toán prefetch strategy:
from django_auto_prefetching import AutoPrefetchViewSetMixin
class OrderViewSet(AutoPrefetchViewSetMixin, viewsets.ModelViewSet):
queryset = Order.objects.all()
serializer_class = OrderSerializer
Reccoon (startup Đan Mạch) report 30-40% speedup toàn bộ API chỉ bằng việc thêm mixin này - không phải refactor queries, không phải thay serializer, không phải đụng vào một dòng business logic nào.
Chỗ thứ ba: Python 3.14 - headline nói 30%, thực tế thì không hẳn
Mình sẽ thú nhận: khi Python 3.14 release tháng 10 năm ngoái, mình đã rất phấn khích. "Nhanh hơn 30%" - mình đọc headline đó trên HN, chia sẻ lên Slack của team, tính luôn kế hoạch upgrade quarter sau. Mình đã sắp commit một câu sai lên công khai chỉ vì mình tin headline mà không đọc benchmark gốc.
Rồi mình ngồi đọc. Và câu trả lời hơi khó nuốt: con số 30% kia không sai về mặt kỹ thuật - nhưng nó sai hoàn toàn về mặt liên quan đến bạn.
Bóc từng claim một
Python 3.14 mang đến 3 thay đổi performance chính:
1. Tail-call interpreter - cải thiện thực sự: 3-5% geometric mean trên pyperformance suite. Nelson Elhage phân tích độc lập cho thấy chỉ 1-3% trên hardware của ông. Con số "30%" ban đầu là do vô tình work around một regression bug trong LLVM 19, không phải do tail-call interpreter tốt hơn nhiều.
2. Free-threading (no-GIL) - promise lớn nhất nhưng chưa dùng được cho Django:
- psycopg2 sẽ re-enable GIL khi chạy trên free-threaded build (C extension chưa declare Py_GIL_DISABLED)
- psycopg3 cũng chưa hoàn thành free-threading support
- Django internals có Field.creation_counter contention, lru_cache bottleneck - Django Forum discussion cho thấy đây là vấn đề structural
Vì database adapter là bottleneck lớn nhất và chưa support free-threading, toàn bộ promise "true parallelism" hiện tại vô nghĩa cho Django production.
3. JIT compiler - thường CHẬM hơn interpreter. Ken Jin (CPython core developer) thừa nhận: "CPython 3.13's JIT ranges from slower to roughly equivalent to the interpreter." Benchmark trên Python 3.14 với Clang 20 cho thấy JIT chậm hơn 6-13% trên một số workloads.
Với một Django app thực tế: 1-3% là tất cả
Một Django/DRF app điển hình spend thời gian:
- 60-80%: Database queries (C extension, không bị ảnh hưởng bởi Python interpreter speed)
- 10-20%: Serialization/deserialization (Python code, hưởng lợi 3-5%)
- 5-10%: Middleware, URL routing (Python code, hưởng lợi 3-5%)
- 5%: Network I/O (không ảnh hưởng)
3-5% improvement × 20-30% Python code = ~1-3% overall throughput improvement.
So sánh: thay ModelSerializer bằng Serializer cho bạn 60% improvement cho phần serialization. Select_related/prefetch_related cho bạn 400-2000% improvement cho phần database. Python 3.14 cho bạn 1-3%.
Incremental GC là thứ duy nhất mình thấy thực sự đáng cho Django trong 3.14 - nó giảm maximum GC pause times một bậc độ lớn (từ ~100ms xuống ~10ms). Không tăng throughput, nhưng cắt P99 latency spikes khá đẹp cho long-running processes. Nếu bạn đang care về tail latency hơn là avg, đây là phần đáng upgrade.
Vậy còn con số 30% từ đâu ra?
Mình đi ngược về source của mọi headline "Python 3.14 is 30% faster" và thấy tất cả đều cite cùng một benchmark: Fibonacci recursive. Pure Python, CPU-bound, zero I/O - workload mà không ai chạy trong production. Đúng là 3.14 nhanh hơn ở cái benchmark đó. Nhưng Django app của bạn không tính Fibonacci. Nó query database, parse JSON, serialize response, và 80% thời gian là chờ C extension hoặc chờ network.
Mình không nghĩ ai đó cố ý nói dối khi share con số 30%. Mình nghĩ chuyện này buồn hơn thế - nó là cách một fact nhỏ và đúng trong một context rất hẹp biến thành một claim lớn và sai trong mọi context rộng, chỉ vì nó đi qua đủ nhiều cái retweet và headline mà không ai dừng lại đọc phần footnote. Mình từ đó tự hỏi: mình còn đang lặp lại bao nhiêu con số mà mình chưa bao giờ verify?
Vậy mình đã làm gì - playbook thực tế
Sau tất cả benchmark, mình ngồi viết lại một cái checklist cho chính mình - không phải để publish như "best practices" mà để lần tới mình không lặp lại cùng một sai lầm. Xếp theo thứ tự effort thấp → impact cao, vì đây là cách mình actually work qua một project performance:
Tier 1: Làm Ngay (< 1 giờ, impact lớn nhất)
1. select_related + prefetch_related cho MỌI ViewSet
class ProductViewSet(viewsets.ReadOnlyModelViewSet):
def get_queryset(self):
return (
Product.objects
.select_related('category', 'category__parent')
.prefetch_related('tags', 'images', 'reviews')
)
Impact: 5-20x speedup. Đây là optimization #1 cho bất kỳ DRF project nào. Nếu bạn chưa làm, dừng đọc bài này và đi làm ngay.
2. Dùng Serializer thay ModelSerializer cho read endpoints
# TRƯỚC: 18.88ms/100 objects
class ProductSerializer(serializers.ModelSerializer):
class Meta:
model = Product
fields = '__all__'
# SAU: 17.21ms/100 objects (chưa ấn tượng? Đọc tiếp)
class ProductSerializer(serializers.Serializer):
id = serializers.IntegerField()
name = serializers.CharField()
price = serializers.DecimalField(max_digits=10, decimal_places=2)
# ... explicit field declarations
Hoặc tốt hơn - tách read/write serializers:
class ProductReadSerializer(serializers.Serializer):
# Chỉ fields cần cho GET
id = serializers.IntegerField()
name = serializers.CharField()
price = serializers.DecimalField(max_digits=10, decimal_places=2)
class ProductWriteSerializer(serializers.ModelSerializer):
# Full ModelSerializer cho POST/PUT/PATCH
class Meta:
model = Product
fields = ['name', 'price', 'description', 'category']
Tier 2: Low-Effort / High-Impact (< 1 ngày)
3. .values() cho list endpoints không cần nesting
class SimpleProductListView(APIView):
def get(self, request):
products = (
Product.objects
.select_related('category')
.values('id', 'name', 'price', 'stock',
'category__name', 'created_at')[:100]
)
return Response(list(products))
Impact: Gần như zero serialization overhead. .values() trả về dicts trực tiếp từ database driver - bypass hoàn toàn DRF serializer layer. Benchmark cho thấy đây là method nhanh nhất trong tất cả.
4. Cursor Pagination thay Offset cho large datasets
class TimelinePagination(CursorPagination):
page_size = 20
ordering = '-created_at'
Offset pagination degrade theo O(offset): page 10,000 phải scan và discard 200,000 rows. Cursor pagination luôn O(1) vì dùng index seek. Benchmark data cho thấy ở offset 50,000+, cursor nhanh hơn 17x.
5. GZip middleware
MIDDLEWARE = ['django.middleware.gzip.GZipMiddleware', ...]
Giảm 88% response size, 29% response time cho JSON APIs. Free lunch.
Tier 3: Medium-Effort (1-3 ngày)
6. Thay serializer library - Serpy hoặc django-ninja
Serpy là drop-in replacement nhanh hơn DRF 5-7x:
import serpy
class ProductSerpySerializer(serpy.Serializer):
id = serpy.IntField()
name = serpy.StrField()
price = serpy.MethodField()
def get_price(self, obj):
return str(obj.price)
django-ninja dùng Pydantic v2 (core viết bằng Rust), nhanh hơn DRF 5-20x tùy use case, và có thể chạy song song với DRF trong cùng project:
# urls.py - DRF và django-ninja cùng tồn tại
urlpatterns = [
path('api/v1/', include('myapp.drf_urls')), # DRF (legacy)
path('api/v2/', ninja_api.urls), # django-ninja (new)
]
Migration strategy: viết endpoints MỚI bằng django-ninja, giữ DRF cho existing. Zero risk, gradual migration.
7. Redis caching cho read-heavy endpoints
from django.views.decorators.cache import cache_page
class ProductListView(APIView):
@method_decorator(cache_page(300)) # 5 min
def get(self, request):
...
Benchmark của mình cho thấy: cùng endpoint trả về 100 products, no cache đạt 39 rps với avg 1,290ms, Redis @cache_page đạt 576 rps với avg 86ms - nhanh gấp 15 lần. Nhưng đừng để con số đó làm bạn lười: cache invalidation là nơi complexity thực sự nằm, và nó sẽ cắn bạn lúc bạn ít ngờ nhất. Mình khuyên dùng signal-based invalidation hoặc version-based strategy ngay từ đầu - đừng đợi tới lúc user báo "sao data cũ thế".
Tier 4: Khi Nào Cần Đổi Framework?
Không cần đổi nếu:
- Bottleneck là database (optimize queries trước)
- Bottleneck là serialization (đổi serializer, không đổi framework)
- Cần Django Admin, auth system, migration framework
Nên xem xét django-ninja nếu:
- Serialization đã confirm là bottleneck (qua profiling)
- Cần async cho external API fan-out
- Đang viết endpoints mới (không cần migrate cũ)
Chỉ migrate sang FastAPI nếu:
- Rời Django hoàn toàn (không dùng ORM, Admin)
- Pure microservice, không cần Django ecosystem
- Team đã comfortable với SQLAlchemy + Alembic
Một case study 2026 cho thấy: migrate Webhook Processor (47 models) sang FastAPI mất 3 tuần, mất Django Admin, FastAPI-Admin chỉ cover 60% functionality. Kết luận: NOT WORTH IT cho CRUD-heavy services.
Nhưng chờ đã - còn counter-argument mình đã tự nói với mình
Khi mình viết draft đầu tiên của bài này, mình đã tự argue ngược lại suốt hai ngày. Counter-argument mạnh nhất là thế này: ModelSerializer chậm nhưng nó tiết kiệm thời gian dev. Auto-generate fields từ model, built-in validation, nested creation/update - bạn setup một endpoint trong 10 phút thay vì 1 giờ. Và với team nhỏ ở giai đoạn early, 50 phút tiết kiệm × 30 endpoint = 25 giờ, tương đương 3 ngày engineering. Đó là thật, không phải hand-wave.
Mình đồng ý phần này. Thật sự đồng ý. Cho prototype, MVP, internal dashboard - ModelSerializer là lựa chọn đúng. Development speed quan trọng hơn runtime speed khi bạn chưa có users, và nếu bạn dành cả tuần đầu tiên optimize serializer thay vì ship feature, bạn là đang tối ưu sai thứ.
Nhưng argument này break down ở ba chỗ, và mình đã nhìn thấy cả ba:
Thứ nhất là khi bạn có users. 200K requests mỗi ngày với response time 800ms và P95 trên 2 giây - đó không phải "premature optimization", đó là tax mà user đang trả bằng sự kiên nhẫn của họ. Mỗi giây chờ là một lý do để rời đi.
Thứ hai là khi team bắt đầu throw money vào vấn đề thay vì profile. Mình đã thấy nhiều hơn một công ty tăng chi phí infra 3-5 lần vì không ai chịu mở django-silk lên nhìn. EC2 bill là con số cuối cùng bạn thấy - nhưng nó thường là symptom của một sai lầm ở layer serializer hoặc query.
Thứ ba là compound effect, và đây là chỗ mình thấy nhói nhất. Serializer overhead một mình thì chấp nhận được. N+1 query một mình cũng chấp nhận được. Offset pagination một mình cũng chấp nhận được. Nhưng stack ba thứ đó lại - và mỗi thứ chỉ "hơi chậm" - thì response time của bạn là 5 giây, mỗi phần đổ lỗi cho phần kia, và không ai muốn là người rebuild lại stack.
Điều làm mình đổi ý về cả argument này là nhận ra một thứ đơn giản: thay ModelSerializer bằng Serializer cho read endpoints không mất productivity. Bạn vẫn giữ ModelSerializer cho write - nơi validation thực sự quan trọng. Read/write split là pattern mà DRF docs nhắc đến từ lâu, nhưng hầu như không ai thực sự áp dụng, vì mọi tutorial bạn đọc đều dùng một serializer cho tất cả. Mình cũng dùng một serializer cho tất cả. Cho đến tuần trước.
Điều mình sẽ làm khác đi lần tới
Nếu bạn đang maintain một DRF project - và bài viết này có ảnh hưởng gì đó lên bạn - thì đây là bốn thứ mình ước mình đã làm sớm hơn hai năm.
Đầu tiên là profile trước khi đoán. Mình từng là kiểu dev đọc một blog post về performance rồi về áp dụng luôn optimization cho project của mình mà không đo gì cả. Kết quả là mình optimize nhầm layer suốt một thời gian dài. django-silk hoặc django-debug-toolbar mở ra trong 5 phút, cho bạn biết chính xác đâu là bottleneck. 5 phút đó cứu bạn khỏi ba tháng optimize nhầm.
Thứ hai, fix queries trước. Luôn luôn. select_related và prefetch_related có ROI cao nhất trong tất cả optimization bạn có thể làm cho một DRF API - không có gì cạnh tranh được. Và setup nplusone hoặc assertNumQueries trong tests để regression không xảy ra. Mình đã quên prefetch quá nhiều lần để tin vào discipline của chính mình; bạn cũng nên.
Thứ ba, tách read/write serializers. Đây là architectural change nhỏ nhất mình biết với impact performance lớn nhất. Zero risk. Mười phút refactor. Mình vẫn không hiểu tại sao pattern này không phải default.
Cuối cùng - và đây là phần mình muốn nhấn mạnh nhất - benchmark trên data của chính bạn. Fork repo benchmark của mình, thay models thành models của bạn, chạy make full. Ba mươi phút setup. Đổi lại, bạn sẽ biết chính xác performance profile của API bạn thay vì tin vào blog post (kể cả bài này). Mình không muốn bạn tin mình - mình muốn bạn tin data của chính bạn.
Một câu mình nghĩ bạn có thể mang theo, nếu không mang theo gì khác: lần tới trong standup có người nói "DRF chậm, hay mình migrate sang FastAPI", thử hỏi họ một câu - "bạn đã profile chưa? bottleneck ở đâu - serializer, hay database, hay cả hai?". Nếu câu trả lời là một cái nhún vai, thì cả phòng đang sắp ký vào một quyết định architecture trị giá 3-6 tháng engineering dựa trên vibes. Team mình đã trả giá đó bằng hoá đơn EC2 tăng 40%. Mình không muốn team bạn trả lại.
Mình không nghĩ mình đã có câu trả lời cuối cùng về DRF performance. Còn rất nhiều câu hỏi mình chưa đào: async views với Django 5.2 thay đổi picture thế nào, HTTP/2 multiplexing có làm thay đổi tradeoff giữa request-per-object và batched endpoints không, hay Pydantic v3 (rumored tháng 6 năm nay) sẽ làm django-ninja nhanh tới mức nào. Mình sẽ đào tiếp trong những tuần tới, và nếu có gì mới, mình sẽ viết lại.
Nếu bạn có benchmark results khác - hoặc nghĩ mình đang sai ở đâu đó - mở issue trên repo, hoặc reply lại bài này. Mình muốn nghe. Không phải vì bài viết này cần comment cho vui, mà vì nếu mình đã sai về DRF suốt hai năm mà không nhận ra, thì khả năng mình còn đang sai ở chỗ khác là rất cao. Và cách duy nhất mình biết để phát hiện là có ai đó cãi lại mình bằng data.
Cảm ơn bạn nếu đã đọc tới đây. Thật.
Bình
Toàn bộ benchmark code, raw data, và Docker setup reproduce được tại github.com/binhna/drf-performance-benchmark. Chạy make full và bạn sẽ có results trong 30 phút.
Nếu bạn đang bận và chỉ đọc được phần này
ModelSerializerchậm hơn manual dict 7.5x in-process và 6-8x qua HTTP - gap này real, đo được, reproducible- Python 3.14 chỉ cải thiện 1-3% cho một Django app thực tế; con số "30% nhanh hơn" là benchmarketing, không phải lừa dối nhưng cũng không phải cho bạn
select_related+prefetch_relatedcó ROI cao nhất trong mọi optimization - làm đầu tiên, luôn luôn- Tách read/write serializers là zero-cost improvement; mười phút refactor, impact đo được ngay
django-ninjalà upgrade path mình khuyên nếu serializer đã confirm là bottleneck sau khi profile - không phải trước- Và nếu bạn không tin bất cứ điều gì trong bài này - tốt. Fork repo, benchmark trên data của chính bạn, rồi cãi lại mình