DeepSeek Local: Cách Tự Host DeepSeek -Bảo Mật và ổn định
8 GB GPU ... boom Deepseek on your 💻

Giới Thiệu
Trong kỷ nguyên của trí tuệ nhân tạo, việc tự host các mô hình AI trên hệ thống của riêng bạn mang lại nhiều lợi ích về bảo mật, hiệu năng và khả năng tùy chỉnh. Bài viết này sẽ hướng dẫn bạn cách tự host mô hình DeepSeek – một mô hình AI mạnh mẽ – trên máy chủ trong home lab hoặc văn phòng tại gia. Nhờ đó, bạn có thể kiểm soát dữ liệu của mình, giảm độ trễ mạng và tối ưu hóa cấu hình phần cứng theo nhu cầu sử dụng.
Lưu ý: DeepSeek-R1 là mô hình có 671 tỷ tham số với kiến trúc Mixture of Experts (MoE) và đòi hỏi khoảng 1.5 TB VRAM, không khả thi với phần cứng tiêu dùng. Các phiên bản "distilled" như DeepSeek-R1-Distill-Qwen-7B và DeepSeek-R1-Distill-LLaMA-70B được tinh chỉnh từ các mô hình mã nguồn mở (như LLaMA và Qwen) sẽ là lựa chọn phù hợp hơn cho việc tự host trên hệ thống cá nhân.
Mục Lục
- DeepSeek Local: Cách Tự Host DeepSeek (Bảo Mật và Kiểm Soát)
- Giới Thiệu
- Mục Lục
- 1. Tại Sao Nên Tự Host DeepSeek
- 2. Những Thách Thức Khi Tự Host
- 3. Chuẩn Bị Để Tự Host DeepSeek
- So Sánh Cấu Hình Phần Cứng và Khuyến Nghị
- 4. Cài Đặt DeepSeek Trên Linux
- 5. Chạy DeepSeek Với Giao Diện Web (Open WebUI)
- 6. Sử Dụng SSH Tunnel (Khuyến Nghị)
- 7. Sử Dụng Reverse Proxy Với Nginx
- 8. Tư vấn chi phí triển khai
- 9. Kết Luận
- Reference
1. Tại Sao Nên Tự Host DeepSeek
Ưu điểm của việc tự host DeepSeek:
- Bảo mật: Dữ liệu của bạn sẽ được lưu trữ trên hệ thống của riêng bạn, không phụ thuộc vào các máy chủ bên thứ ba.
- Tốc độ: Giảm độ trễ mạng, đặc biệt khi chạy các mô hình nhỏ hơn.
- Tùy chỉnh phần cứng: Có thể cấu hình CPU, GPU và bộ nhớ theo nhu cầu sử dụng.
- Khả năng mở rộng: Bạn có thể mở rộng hệ thống home lab theo thời gian.
- Kiểm soát: Không bị ràng buộc bởi các dịch vụ đám mây hay các nhà cung cấp bên ngoài.
- Học hỏi: Quản lý và tối ưu hóa hạ tầng AI giúp bạn nâng cao kỹ năng cá nhân.
2. Những Thách Thức Khi Tự Host
Mặc dù có nhiều ưu điểm, việc tự host DeepSeek cũng kèm theo một số khó khăn:
- Thiên lệch mô hình và kiểm duyệt: Một số phiên bản có thể có phản hồi hạn chế đối với các chủ đề nhạy cảm.
- Chi phí: Đầu tư ban đầu và chi phí điện năng cao cho phần cứng chuyên dụng.
- Tính bền vững: Các mô hình AI tương lai có thể yêu cầu nâng cấp phần cứng thường xuyên.
- Bảo trì: Cần cập nhật và duy trì hệ thống liên tục.
- Giới hạn mở rộng: Vấn đề về không gian, tiếng ồn và nhiệt độ có thể ảnh hưởng đến khả năng mở rộng hệ thống.
3. Chuẩn Bị Để Tự Host DeepSeek
Trước khi cài đặt DeepSeek, hãy đảm bảo hệ thống của bạn đáp ứng các yêu cầu phần cứng cần thiết, đặc biệt nếu bạn định chạy các mô hình lớn:
- CPU: Bộ xử lý đa nhân mạnh mẽ (khuyến nghị 12 nhân trở lên) để xử lý nhiều yêu cầu cùng lúc.
- GPU: GPU NVIDIA có hỗ trợ CUDA (hoặc GPU AMD – tuy chưa được kiểm chứng nhiều).
- RAM: Tối thiểu 16 GB, tốt nhất là 32 GB trở lên đối với các mô hình lớn.
- Bộ nhớ lưu trữ: Ổ NVMe để tăng tốc độ đọc/ghi.
- Hệ điều hành: Ubuntu hoặc các version dựa trên Ubuntu được ưu tiên vì tính tương thích cao.
Ngoài ra, nếu bạn cần phiên bản DeepSeek không bị kiểm duyệt, hãy thử sử dụng phiên bản open-r1. Các mô hình "distilled" cũng sẽ tiết kiệm tài nguyên hơn và phù hợp hơn với phần cứng tiêu dùng.
So Sánh Cấu Hình Phần Cứng và Khuyến Nghị
Ngoài các bước cài đặt và chạy DeepSeek, mình thấy việc so sánh cấu hình phần cứng rất hay. Bạn có thể tham khảo đường link này để tìm kiếm và lọc những mô hình DeepSeek R1 tốt nhất để tải về: HuggingFace sorted by downloads.
1. Yêu Cầu Phần Cứng cho DeepSeek R1 (8-bit Quantized)
| Model | RAM Hệ thống | Số lõi CPU | VRAM GPU | GPU Nvidia Đề xuất | GPU AMD Đề xuất |
|---|---|---|---|---|---|
| 1.5B | 16 GB | 4 | 8 GB | RTX 4060 Ti 8GB | RX 7600 8GB |
| 7B | 32 GB | 8 | 16 GB | RTX 4060 Ti 16GB | RX 7700 XT 12GB |
| 8B | 32 GB | 16 | 16 GB | RTX 4060 Ti 16GB | RX 7800 XT 16GB |
| 14B | 64 GB | 24 | 16–24 GB | RTX 4090 24GB | RX 7900 XT 24GB |
| 32B | 128 GB | 32 | 32–48 GB | RTX A6000 48GB | Instinct MI250X |
| 70B | 256 GB | 48 | 48+ GB | A100 80GB | Instinct MI250X |
| 671B | 1 TB+ | 64+ | 80+ GB | H100 80GB (multi‑GPU) | Instinct MI300 (multi‑GPU) |
Chú ý:
- Một GPU 16GB có thể hoạt động với các tối ưu hóa mạnh, nhưng nếu có GPU với VRAM cao hơn (hoặc sử dụng cấu hình đa GPU) sẽ giúp hệ thống có thêm không gian hoạt động.
- Đối với môi trường Production (đặc biệt với các mô hình lớn), bạn có thể cần điều chỉnh thêm cấu hình hoặc sử dụng chiến lược multi-GPU để đáp ứng tối đa yêu cầu về bộ nhớ và băng thông.
2. Yêu Cầu Phần Cứng cho DeepSeek R1 (4-bit Quantized)
| Model | RAM Hệ thống | Số lõi CPU | VRAM GPU | GPU Nvidia Đề xuất | GPU AMD Đề xuất |
|---|---|---|---|---|---|
| 1.5B | 16 GB | 4 | 8 GB | RTX 3050 (8 GB) | RX 6600 (8 GB) |
| 7B | 16 GB | 6 | 8 GB | RTX 3060 (8 GB) | RX 6600 XT (8 GB) |
| 8B | 16–32 GB | 8 | 8–12 GB | RTX 3060 (12 GB) | RX 6700 XT (12 GB) |
| 14B | 32 GB | 12 | 12–16 GB | RTX 4060 Ti (16 GB) | RX 7800 XT (16 GB) |
| 32B | 64 GB | 16 | 16–24 GB | RTX 4090 (24 GB) | RX 7900 XTX (24 GB) |
| 70B | 128 GB | 16–24 | 24–32 GB | A100 40 GB (hoặc H100) | Instinct MI250X |
| 671B | 512 GB+ | 32+ | 40+ GB | A100/H100 (multi‑GPU) | Instinct MI300 (multi‑GPU) |
Chú ý:
- Với các mô hình nhỏ (1.5B, 7B, 8B), chế độ 4-bit có thể chạy tốt trên các GPU tầm trung với VRAM từ 8-12 GB.
- Đối với mô hình 14B, một GPU tầm trung như RTX 4060 Ti (hoặc RTX 4070) có thể đáp ứng đủ nhu cầu khi chạy ở chế độ 4-bit.
- Dù sử dụng 4-bit quantization, các mô hình lớn (32B và trên) vẫn yêu cầu phần cứng mạnh mẽ; ví dụ, một mô hình 32B có thể chạy trên GPU 24GB (như RTX 4090) với tối ưu hóa, trong khi các mô hình 70B và 671B thường cần GPU cấp doanh nghiệp, cấu hình multi-GPU hoặc Cluster.
3. So Sánh Hiệu Năng và Độ Chính Xác Giữa Các Phiên Bản
Để giúp bạn lựa chọn mô hình phù hợp nhất với nhu cầu sử dụng, hãy cùng xem xét hiệu năng của từng phiên bản DeepSeek R1:
DeepSeek R1 và R1-Zero (Mô hình Gốc)
| Mô hình | Tổng Tham số | Tham số Hoạt động | Độ dài Context | Đặc điểm nổi bật |
|---|---|---|---|---|
| DeepSeek-R1-Zero | 671B | 37B | 128K | - Huấn luyện thuần túy bằng RL không qua SFT - Khả năng suy luận tự nhiên - Có thể lặp lại hoặc trộn ngôn ngữ |
| DeepSeek-R1 | 671B | 37B | 128K | - Kết hợp RL và SFT - Cân bằng giữa suy luận và đọc hiểu - Hiệu suất tương đương OpenAI-o1 |
Các Mô hình Distilled (Tinh chỉnh)
| Mô hình | Mô hình Gốc | Điểm mạnh | Ứng dụng phù hợp |
|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | Qwen2.5-Math-1.5B | - Nhẹ nhất - Phù hợp thiết bị cá nhân |
- Chatbot đơn giản - Xử lý văn bản cơ bản |
| DeepSeek-R1-Distill-Qwen-7B | Qwen2.5-Math-7B | - Cân bằng kích thước/hiệu năng - Tối ưu cho máy tính cá nhân |
- Phân tích dữ liệu - Hỗ trợ lập trình |
| DeepSeek-R1-Distill-Llama-8B | Llama-3.1-8B | - Tương thích LLaMA - Cộng đồng lớn |
- Xử lý ngôn ngữ tự nhiên - Tích hợp ứng dụng |
| DeepSeek-R1-Distill-Qwen-14B | Qwen2.5-14B | - Hiệu năng cao - Đa nhiệm tốt |
- Phân tích phức tạp - Nghiên cứu học thuật |
| DeepSeek-R1-Distill-Qwen-32B | Qwen2.5-32B | - Vượt trội OpenAI-o1-mini - SOTA cho mô hình dense |
- Ứng dụng doanh nghiệp - Nghiên cứu chuyên sâu |
| DeepSeek-R1-Distill-Llama-70B | Llama-3.3-70B | - Gần với mô hình gốc - Hiệu năng cao nhất trong nhóm distilled |
- Hệ thống quy mô lớn - Ứng dụng đòi hỏi độ chính xác cao |
Khuyến nghị sử dụng:
-
Cho người dùng cá nhân/máy tính để bàn:
- Tốt nhất: DeepSeek-R1-Distill-Qwen-7B hoặc Llama-8B
- Cân nhắc: DeepSeek-R1-Distill-Qwen-14B nếu có GPU mạnh
-
Cho doanh nghiệp vừa và nhỏ:
- Khuyến nghị: DeepSeek-R1-Distill-Qwen-32B
- Phương án dự phòng: DeepSeek-R1-Distill-Qwen-14B
-
Cho nghiên cứu và phát triển:
- Tốt nhất: DeepSeek-R1 hoặc DeepSeek-R1-Zero
- Thay thế: DeepSeek-R1-Distill-Llama-70B
-
Cho ứng dụng edge/IoT:
- Khuyến nghị: DeepSeek-R1-Distill-Qwen-1.5B
- Cân nhắc: DeepSeek-R1-Distill-Qwen-7B nếu có đủ tài nguyên
Lưu ý quan trọng:
- Nhiệt độ (temperature) nên được đặt trong khoảng 0.5-0.7 (khuyến nghị 0.6) để tránh lặp lại vô tận hoặc đầu ra không mạch lạc
- Không nên thêm system prompt; tất cả hướng dẫn nên đưa vào user prompt
- Với bài toán toán học, nên thêm chỉ dẫn như: "Hãy lập luận từng bước và đặt câu trả lời cuối cùng trong \boxed{}"
- Khi đánh giá hiệu năng mô hình, nên thực hiện nhiều lần kiểm thử và lấy kết quả trung bình
4. So Sánh Độ Chính Xác và Hiệu Năng Chi Tiết
Dưới đây là kết quả đánh giá chi tiết về độ chính xác của các mô hình DeepSeek trên nhiều bộ benchmark khác nhau. Tất cả các mô hình được cấu hình với độ dài tối đa 32,768 token, nhiệt độ 0.6, và top-p 0.95.
So Sánh Với Các Mô Hình Hàng Đầu
| Category | Benchmark (Metric) | Claude-3.5-Sonnet-1022 | GPT-4o 0513 | DeepSeek V3 | OpenAI o1-mini | OpenAI o1-1217 | DeepSeek R1 |
|---|---|---|---|---|---|---|---|
| Architecture | - | - | MoE | - | - | MoE | |
| # Activated Params | - | - | 37B | - | - | 37B | |
| # Total Params | - | - | 671B | - | - | 671B | |
| English | MMLU (Pass@1) | 88.3 | 87.2 | 88.5 | 85.2 | 91.8 | 90.8 |
| MMLU-Redux (EM) | 88.9 | 88.0 | 89.1 | 86.7 | - | 92.9 | |
| MMLU-Pro (EM) | 78.0 | 72.6 | 75.9 | 80.3 | - | 84.0 | |
| DROP (3-shot F1) | 88.3 | 83.7 | 91.6 | 83.9 | 90.2 | 92.2 | |
| IF-Eval (Prompt Strict) | 86.5 | 84.3 | 86.1 | 84.8 | - | 83.3 | |
| GPQA-Diamond (Pass@1) | 65.0 | 49.9 | 59.1 | 60.0 | 75.7 | 71.5 | |
| SimpleQA (Correct) | 28.4 | 38.2 | 24.9 | 7.0 | 47.0 | 30.1 | |
| FRAMES (Acc.) | 72.5 | 80.5 | 73.3 | 76.9 | - | 82.5 | |
| AlpacaEval2.0 (LC-winrate) | 52.0 | 51.1 | 70.0 | 57.8 | - | 87.6 | |
| ArenaHard (GPT-4-1106) | 85.2 | 80.4 | 85.5 | 92.0 | - | 92.3 | |
| Code | LiveCodeBench (Pass@1-COT) | 33.8 | 34.2 | - | 53.8 | 63.4 | 65.9 |
| Codeforces (Percentile) | 20.3 | 23.6 | 58.7 | 93.4 | 96.6 | 96.3 | |
| Codeforces (Rating) | 717 | 759 | 1134 | 1820 | 2061 | 2029 | |
| SWE Verified (Resolved) | 50.8 | 38.8 | 42.0 | 41.6 | 48.9 | 49.2 | |
| Aider-Polyglot (Acc.) | 45.3 | 16.0 | 49.6 | 32.9 | 61.7 | 53.3 | |
| Math | AIME 2024 (Pass@1) | 16.0 | 9.3 | 39.2 | 63.6 | 79.2 | 79.8 |
| MATH-500 (Pass@1) | 78.3 | 74.6 | 90.2 | 90.0 | 96.4 | 97.3 | |
| CNMO 2024 (Pass@1) | 13.1 | 10.8 | 43.2 | 67.6 | - | 78.8 | |
| Chinese | CLUEWSC (EM) | 85.4 | 87.9 | 90.9 | 89.9 | - | 92.8 |
| C-Eval (EM) | 76.7 | 76.0 | 86.5 | 68.9 | - | 91.8 | |
| C-SimpleQA (Correct) | 55.4 | 58.7 | 68.0 | 40.3 | - | 63.7 |
So Sánh Các Mô Hình Distilled
| Model | AIME 2024 pass@1 | AIME 2024 cons@64 | MATH-500 pass@1 | GPQA Diamond pass@1 | LiveCodeBench pass@1 | CodeForces rating |
|---|---|---|---|---|---|---|
| GPT-4o-0513 | 9.3 | 13.4 | 74.6 | 49.9 | 32.9 | 759 |
| Claude-3.5-Sonnet-1022 | 16.0 | 26.7 | 78.3 | 65.0 | 38.9 | 717 |
| o1-mini | 63.6 | 80.0 | 90.0 | 60.0 | 53.8 | 1820 |
| QwQ-32B-Preview | 44.0 | 60.0 | 90.6 | 54.5 | 41.9 | 1316 |
| DeepSeek-R1-Distill-Qwen-1.5B | 28.9 | 52.7 | 83.9 | 33.8 | 16.9 | 954 |
| DeepSeek-R1-Distill-Qwen-7B | 55.5 | 83.3 | 92.8 | 49.1 | 37.6 | 1189 |
| DeepSeek-R1-Distill-Qwen-14B | 69.7 | 80.0 | 93.9 | 59.1 | 53.1 | 1481 |
| DeepSeek-R1-Distill-Qwen-32B | 72.6 | 83.3 | 94.3 | 62.1 | 57.2 | 1691 |
| DeepSeek-R1-Distill-Llama-8B | 50.4 | 80.0 | 89.1 | 49.0 | 39.6 | 1205 |
| DeepSeek-R1-Distill-Llama-70B | 70.0 | 86.7 | 94.5 | 65.2 | 57.5 | 1633 |
Phân tích hiệu năng:
-
Khả năng tổng quát:
- DeepSeek R1 vượt trội cả Claude-3.5 và GPT-4 trong hầu hết các benchmark
- Đặc biệt mạnh trong các bài toán toán học và lập trình
- Hiệu suất cao trong cả tiếng Anh và tiếng Trung
-
Mô hình Distilled:
- Qwen-32B và Llama-70B đạt hiệu suất gần với mô hình gốc
- Qwen-7B và Llama-8B là lựa chọn tốt cho người dùng cá nhân, với hiệu suất khá tốt
- Ngay cả mô hình nhỏ nhất (Qwen-1.5B) cũng cho kết quả khả quan trong các tác vụ cơ bản
-
Điểm mạnh theo lĩnh vực:
- Toán học: Các mô hình DeepSeek thể hiện xuất sắc trong MATH-500 và AIME
- Lập trình: Rating Codeforces cao cho thấy khả năng giải quyết vấn đề tốt
- Ngôn ngữ: Hiệu suất cao trong cả benchmark tiếng Anh và tiếng Trung
-
Cân nhắc chi phí-hiệu năng:
- Qwen-14B là điểm cân bằng tốt giữa hiệu năng và yêu cầu tài nguyên
- Qwen-32B phù hợp cho doanh nghiệp cần độ chính xác cao
- Qwen-7B và Llama-8B là lựa chọn tốt cho người dùng cá nhân
5. So Sánh Toàn Diện Với Các Giải Pháp Khác
Để giúp bạn có cái nhìn tổng quan hơn về vị thế của DeepSeek trong hệ sinh thái AI, dưới đây là bảng so sánh chi tiết với các giải pháp hàng đầu hiện nay:
Benchmark Tổng Quát (% Chính Xác)
| Mô hình | MMLU | MMLU-Redux | MMLU-Pro | DROP | IF-Eval | GPQA | SimpleQA | FRAMES | AlpacaEval |
|---|---|---|---|---|---|---|---|---|---|
| Claude-3.5 | 88.3 | 88.9 | 78.0 | 88.3 | 86.5 | 65.0 | 28.4 | 72.5 | 52.0 |
| GPT-4 | 87.2 | 88.0 | 72.6 | 83.7 | 84.3 | 49.9 | 38.2 | 80.5 | 51.1 |
| DeepSeek R1 | 90.8 | 92.9 | 84.0 | 92.2 | 83.3 | 71.5 | 30.1 | 82.5 | 87.6 |
| OpenAI-o1-mini | 85.2 | 86.7 | 80.3 | 83.9 | 84.8 | 60.0 | 7.0 | 76.9 | 57.8 |
| OpenAI-o1 | 91.8 | - | - | 90.2 | - | 75.7 | 47.0 | - | - |
Benchmark Lập Trình và Toán Học
| Mô hình | LiveCodeBench | Codeforces Rating | AIME 2024 | MATH-500 | CNMO 2024 |
|---|---|---|---|---|---|
| Claude-3.5 | 33.8 | 717 | 16.0 | 78.3 | 13.1 |
| GPT-4 | 34.2 | 759 | 9.3 | 74.6 | 10.8 |
| DeepSeek R1 | 65.9 | 2029 | 79.8 | 97.3 | 78.8 |
| OpenAI-o1-mini | 53.8 | 1820 | 63.6 | 90.0 | 67.6 |
| OpenAI-o1 | 63.4 | 2061 | 79.2 | 96.4 | - |
So Sánh Các Mô Hình Distilled
| Mô hình | AIME 2024 | MATH-500 | LiveCodeBench | Codeforces |
|---|---|---|---|---|
| GPT-4 | 9.3 | 74.6 | 32.9 | 759 |
| Claude-3.5 | 16.0 | 78.3 | 38.9 | 717 |
| OpenAI-o1-mini | 63.6 | 90.0 | 53.8 | 1820 |
| QwQ-32B-Preview | 44.0 | 90.6 | 41.9 | 1316 |
| DeepSeek-R1-Distill-Qwen-1.5B | 28.9 | 83.9 | 16.9 | 954 |
| DeepSeek-R1-Distill-Qwen-7B | 55.5 | 92.8 | 37.6 | 1189 |
| DeepSeek-R1-Distill-Qwen-14B | 69.7 | 93.9 | 53.1 | 1481 |
| DeepSeek-R1-Distill-Qwen-32B | 72.6 | 94.3 | 57.2 | 1691 |
| DeepSeek-R1-Distill-Llama-8B | 50.4 | 89.1 | 39.6 | 1205 |
| DeepSeek-R1-Distill-Llama-70B | 70.0 | 94.5 | 57.5 | 1633 |
Nhận xét chính:
-
Vượt trội trong toán học và lập trình:
- DeepSeek R1 đạt kết quả ấn tượng trong MATH-500 (97.3%) và AIME 2024 (79.8%)
- Rating Codeforces 2029 cho thấy khả năng lập trình xuất sắc
-
Cạnh tranh với các mô hình hàng đầu:
- Vượt trội GPT-4 và Claude-3.5 trong nhiều benchmark
- Hiệu suất tương đương hoặc cao hơn OpenAI-o1 trong một số lĩnh vực
-
Hiệu quả của mô hình Distilled:
- Qwen-32B và Llama-70B duy trì hiệu suất cao, gần với mô hình gốc
- Qwen-14B cung cấp sự cân bằng tốt giữa hiệu năng và tài nguyên
- Các mô hình nhỏ (1.5B-8B) vẫn đạt hiệu suất khả quan cho người dùng cá nhân
-
Điểm đặc biệt:
- Khả năng xử lý ngôn ngữ đa dạng (cả Anh và Trung)
- Hiệu suất cao trong các tác vụ đòi hỏi suy luận (MMLU-Pro, DROP)
- Tỷ lệ thành công cao trong AlpacaEval (87.6%)
4. Cài Đặt DeepSeek Trên Linux
Để cài đặt và chạy DeepSeek, hãy làm theo các bước dưới đây:
- Cài đặt:
curl -fsSL https://ollama.com/install.sh | sh ollama run deepseek-r1:8b - Đối với hướng dẫn chi tiết hơn, bạn có thể tham khảo bài "Cài đặt DeepSeek trên Linux trong 3 phút".
5. Chạy DeepSeek Với Giao Diện Web (Open WebUI)
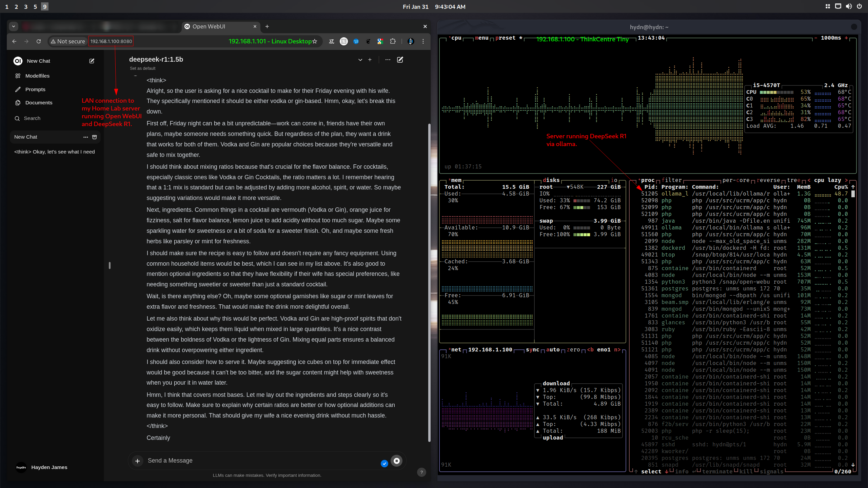
Việc tích hợp giao diện web giúp bạn dễ dàng tương tác với DeepSeek qua một bảng điều khiển trung tâm, có thể truy cập từ bất kỳ thiết bị nào trong mạng nội bộ.
Cài đặt Open WebUI:
- Cài đặt qua pip:
pip install open-webui - Hoặc cài đặt qua Snap:
sudo apt update sudo apt install snapd sudo snap install open-webui --beta
Khởi chạy Open WebUI:
Chạy lệnh sau trong terminal:
open-webui serve
Sau đó, bạn có thể truy cập giao diện tại: http://localhost:8080
(Thay thế localhost bằng địa chỉ IP cục bộ của máy chủ nếu cần truy cập từ các thiết bị khác trong mạng nội bộ.)
6. Sử Dụng SSH Tunnel (Khuyến Nghị)
Để đảm bảo kết nối bảo mật giữa máy tính cá nhân và máy chủ DeepSeek trong mạng nội bộ, bạn nên sử dụng SSH tunnel:
Các bước thực hiện:
-
Cài đặt SSH Server trên máy chủ:
sudo apt update sudo apt install openssh-server -
Khởi động và kích hoạt dịch vụ SSH:
sudo systemctl start ssh sudo systemctl enable ssh(Một số phiên bản có thể sử dụng tên service
sshd.) -
Cấu hình Firewall cho phép kết nối SSH và cổng Open WebUI:
- Cho phép SSH (Cổng 22) cho mạng nội bộ:
sudo ufw allow from 192.168.1.0/24 to any port 22 proto tcp - Cho phép Open WebUI (Cổng 8080) cho mạng nội bộ:
sudo ufw allow from 192.168.1.0/24 to any port 8080 proto tcp
(Thay đổi
192.168.1.0/24cho phù hợp với dải mạng của bạn.) - Cho phép SSH (Cổng 22) cho mạng nội bộ:
-
Thiết lập SSH Tunnel từ máy tính cá nhân:
ssh -L 8080:localhost:8080 [email protected]- Giải thích:
-L 8080:localhost:8080chuyển tiếp cổng 8080 của máy tính cá nhân tới cổng 8080 của máy chủ.
Thayuserbằng tên đăng nhập SSH và192.168.1.100bằng địa chỉ IP cục bộ của máy chủ.
- Giải thích:
-
(Tùy chọn) Sử dụng autossh để tự động tái kết nối khi cần:
sudo apt install autossh autossh -M 0 -f -N -L 8080:localhost:8080 [email protected]
Truy cập giao diện: Mở trình duyệt và vào http://localhost:8080.
7. Sử Dụng Reverse Proxy Với Nginx
Nếu bạn muốn truy cập DeepSeek thông qua một tên miền nội bộ, có thể cấu hình Nginx làm reverse proxy.
Các bước thực hiện:
-
Cài đặt Nginx:
sudo apt install nginx -
Tạo cấu hình Reverse Proxy:
Tạo file cấu hình mới tại
/etc/nginx/sites-available/deepseekvới nội dung:server { listen 80; server_name your-local-domain.local; location / { proxy_pass http://localhost:8080; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; } } -
Kích hoạt cấu hình và khởi động lại Nginx:
sudo ln -s /etc/nginx/sites-available/deepseek /etc/nginx/sites-enabled/ sudo nginx -t # Kiểm tra cấu hình sudo systemctl restart nginx -
Truy cập:
Mở trình duyệt và truy cập http://your-local-domain.local/.
8. Tư vấn chi phí triển khai
Nếu bạn muốn triển khai DeepSeek R1 trên môi trường doanh nghiệp của bạn thì đây là những lựa chọn chi phí bạn có thể tham khảo.
8.1. Dịch Vụ Đám Mây (Cloud Hosting)
Đây là lựa chọn linh hoạt và dễ triển khai nhất:
-
AWS (g5.2xlarge)
- Chi phí: Khoảng 1.25 USD/giờ
- Ví dụ: Xử lý 50 triệu token đầu vào và 10 triệu token đầu ra chỉ tốn ~37.50 USD cho 30 giờ hoạt động
- Phù hợp: Quy mô nhỏ, thử nghiệm ban đầu
-
Azure ML
- Chi phí tương đương AWS: ~40.00 USD cho cùng khối lượng công việc
- Ưu điểm: Tích hợp tốt với hệ sinh thái Microsoft, bảo mật cao
- Phù hợp: Doanh nghiệp đang sử dụng Azure
-
Vultr (L40S GPU)
- Chi phí: ~325.63 USD cho 8 GPU trong 48 giờ
- Phù hợp: Tác vụ yêu cầu hiệu suất cao
8.2. Nền Tảng AI Chuyên Dụng
- Together.ai
- Giá: 7.00 USD/1 triệu token
- Tổng chi phí cho 60 triệu token: 420.00 USD
- Ưu điểm: Triển khai nhanh, không cần quản lý hạ tầng
- Phù hợp: Startup, doanh nghiệp muốn tập trung vào phát triển ứng dụng
8.3. Tự Triển Khai (Self-Hosted)
GPU VPS (A4000 16GB)
- Phù hợp cho các phiên bản:
- DeepSeek-R1 1.5B
- DeepSeek-R1 7B
- DeepSeek-R1 8B
- DeepSeek-R1 14B
- Chi phí: Thấp nhất trong các phương án, phù hợp thử nghiệm cá nhân
GPU Server Chuyên Dụng
-
Cấu hình trung bình:
- A5000 24GB/RTX4090 24GB/A100 40GB
- Hỗ trợ phiên bản 32B
- Chi phí thuê: 2-4 USD/giờ
-
Cấu hình cao cấp:
- A6000 48GB/A100 80GB
- Dành cho phiên bản 70B
- Yêu cầu: Server đa GPU (4x RTX 5090 hoặc A100 80GB)
- Chi phí: 10-20 USD/giờ
4. Chiến Lược Tối Ưu Chi Phí
-
Lựa Chọn Phiên Bản Phù Hợp:
- Phiên bản nhỏ (1.5B-14B): Phù hợp máy tính cá nhân, chi phí thấp
- Phiên bản trung bình (32B): Cân bằng hiệu năng và chi phí
- Phiên bản lớn (70B): Chỉ khi thực sự cần thiết
-
Tận Dụng Mã Nguồn Mở:
- Triển khai trên phần cứng sẵn có (như Mac Mini)
- Chấp nhận hiệu suất hạn chế để tiết kiệm chi phí
Bảng So Sánh Chi Phí
| Loại Hosting | Chi phí ước tính (USD) | Phù hợp cho |
|---|---|---|
| AWS/Azure (quy mô nhỏ) | 35-50/tác vụ | Thử nghiệm, dự án nhỏ |
| Together.ai | 7.00/1M token | Triển khai nhanh |
| GPU VPS (A4000) | 0.5-1/giờ | Cá nhân, phiên bản nhỏ |
| GPU Server (A100) | 2-20/giờ | Doanh nghiệp, mô hình lớn |
Lưu Ý Quan Trọng
-
Chi Phí Theo Quy Mô:
- Phiên bản 70B đòi hỏi GPU cao cấp (A100 80GB)
- Chi phí tăng đáng kể với mô hình lớn
-
Tính Toán Token:
- Cần ước lượng nhu cầu sử dụng token
- Tránh chi phí phát sinh không cần thiết
-
Bảo Mật:
- Dịch vụ giá rẻ có thể không đảm bảo an toàn dữ liệu
- Cân nhắc kỹ khi sử dụng phần cứng từ các nhà cung cấp chưa được kiểm chứng
9. Kết Luận
Tự host DeepSeek trên hệ thống của bạn không chỉ mang lại hiệu năng và bảo mật cao hơn mà còn giúp bạn kiểm soát hoàn toàn hạ tầng AI của mình. Dù đòi hỏi sự đầu tư về phần cứng và thời gian bảo trì, nhưng việc này mở ra cơ hội học hỏi và tùy chỉnh theo nhu cầu cá nhân hoặc doanh nghiệp.
Với các bước hướng dẫn trên, bạn đã có thể:
- Tự host DeepSeek trên máy chủ tại nhà hoặc văn phòng.
- Sử dụng giao diện web thông qua Open WebUI.
- Thiết lập SSH tunnel để đảm bảo kết nối bảo mật.
- Cấu hình Reverse Proxy với Nginx để truy cập dễ dàng qua tên miền nội bộ.
Hãy thử nghiệm và chia sẻ kinh nghiệm của bạn với cộng đồng Linux và AI. Nếu có thắc mắc hay ý kiến đóng góp, hãy để lại bình luận phía dưới bài viết.
- Cấu hình Reverse Proxy với Nginx để truy cập dễ dàng qua tên miền nội bộ.
Hãy thử nghiệm và chia sẻ kinh nghiệm của bạn với cộng đồng Linux và AI. Nếu có thắc mắc hay ý kiến đóng góp, hãy để lại bình luận phía dưới bài viết.
Nếu bạn cần thêm thông tin chi tiết về việc triển khai DeepSeek, đừng ngần ngại liên hệ với mình qua Contact nhé! 👍😃