B-Tree vs LSM-Tree: Ghi dữ liệu giữa MySQL và Cassandra khác gì nhau
Tại sao MySQL dùng B-Tree còn Cassandra chọn LSM-Tree? So sánh chi tiết Random I/O vs Sequential I/O, Write Amplification và cách chọn database phù hợp.

B-Tree vs LSM-Tree: Cuộc chiến "ghi đĩa" giữa MySQL và Cassandra
Đây là bài viết tôi đọc từ Chapter 3 của cuốn "Designing Data-Intensive Applications" (DDIA) của Martin Kleppmann. Nếu bạn làm backend mà chưa đọc cuốn này thì... nên đọc đi, nghiêm túc đấy.

Research Question: Tại sao MySQL (ra đời 1995) lại chọn cấu trúc B-Tree, trong khi các "ngôi sao" NoSQL hiện đại như Cassandra, RocksDB lại tôn thờ LSM-Tree? Sự khác biệt cốt lõi về hiệu năng nằm ở đâu?
TL;DR
- B-Tree (MySQL, PostgreSQL): Tối ưu cho READ. Dữ liệu được sắp xếp ngăn nắp trên đĩa. Đọc nhanh, Ghi chậm.
- LSM-Tree (Cassandra, RocksDB): Tối ưu cho WRITE. Dữ liệu cứ ghi nối đuôi. Ghi cực nhanh, Đọc có thể chậm.
- Key Insight: Không có "Database nhanh nhất", chỉ có Database phù hợp với workload của bạn.
Lời nói dối về câu lệnh INSERT
Năm 2017, công ty phần mềm "Ép Bê Tông" quyết định dùng MySQL để lưu trữ activity log của ứng dụng SaaS. Hệ thống chạy ngon lành trong 6 tháng đầu với vài nghìn users. Nhưng khi user base tăng lên 100K và mỗi người tạo ra hàng chục events mỗi ngày (click, view, search...), MySQL bắt đầu "nghẹt thở". Write latency tăng từ 5ms lên 500ms. Đội ngũ dev của Ép Bê Tông mất 2 tuần để nhận ra vấn đề không nằm ở code, mà nằm ở chính cấu trúc dữ liệu bên dưới MySQL.
Bạn đã bao giờ gõ dòng này chưa?
INSERT INTO salary_decrease_employees (id, name) VALUES (1, 'Binh');
Database trả về OK. Bạn nghĩ rằng dữ liệu đã được ghi an toàn vào đĩa cứng?
Thực ra, nếu Database ghi trực tiếp vào đĩa ngay lúc đó, hệ thống của bạn sẽ chậm không thể chấp nhận được. Đĩa cứng (kể cả SSD) ghét nhất là việc nhảy cóc (Random I/O) - tức là đầu đọc phải di chuyển lung tung để tìm đúng vị trí cần ghi. Giống như bạn đang đọc sách mà cứ phải lật qua lật lại giữa trang 5, trang 200, rồi trang 37 vậy.
Để ghi dữ liệu bền vững và hiệu quả, các kỹ sư database phải chọn một trong hai triết lý lưu trữ đối lập nhau:
- Dọn dẹp ngăn nắp ngay từ đầu (B-Tree) - như một thủ thư khó tính.
- Cứ ghi nhanh vào sổ, cuối tuần tổng hợp sau (LSM-Tree) - như một phóng viên chiến trường.
Đây là khởi nguồn của cuộc chiến giữa SQL và NoSQL.

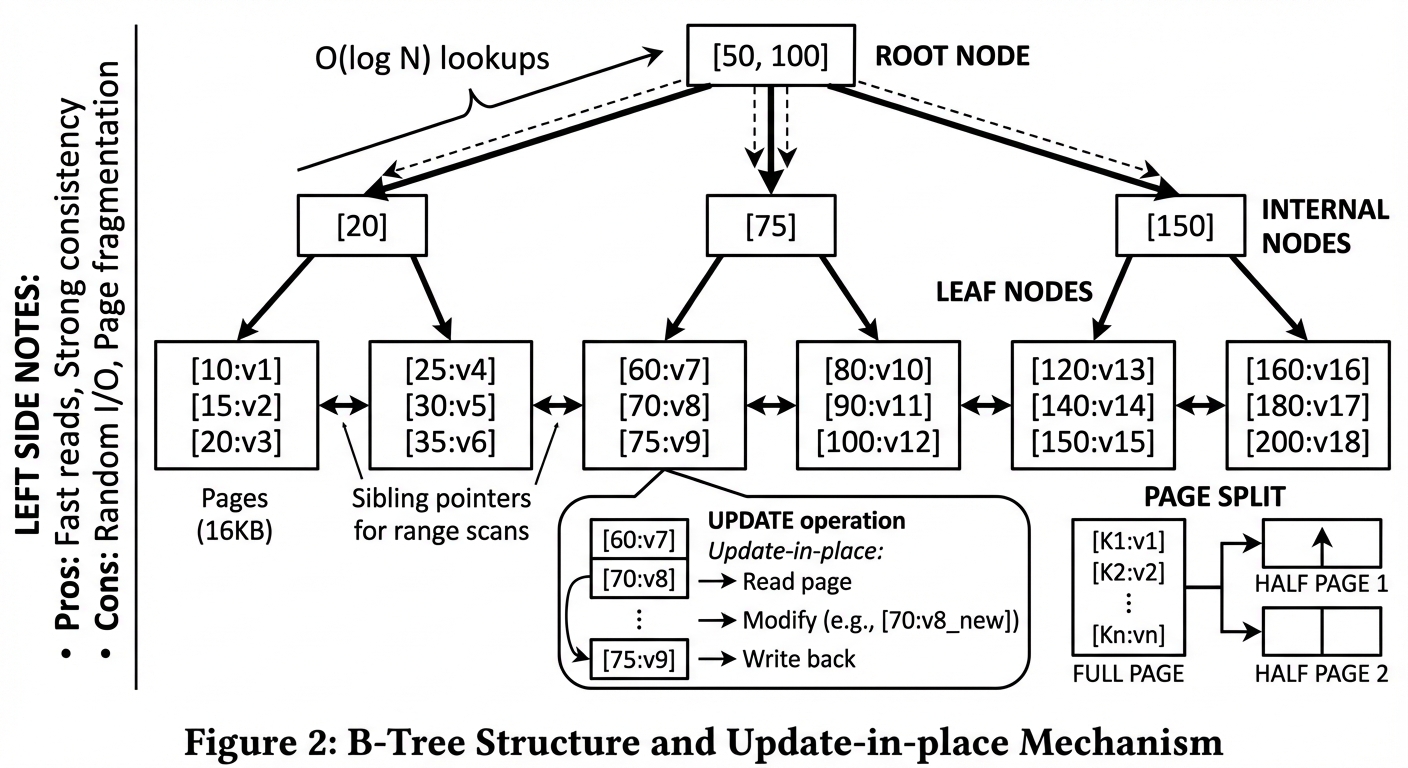
B-Tree: Vị thủ thư khó tính
Đây là cấu trúc mặc định của MySQL (InnoDB), PostgreSQL, Oracle và hầu hết các database ra đời thế kỷ 20. Nó được phát minh từ năm 1970 bởi Rudolf Bayer và Ed McCreight, và vẫn đứng vững sau hơn 50 năm. Già nhưng không lỗi thời.
Hãy tưởng tượng Database là một Thư viện lớn. Dữ liệu được chia thành các Pages (thường là 4KB hoặc 16KB), giống như các ngăn kệ sách. Mỗi cuốn sách (record) có vị trí cố định trên kệ, được đánh số theo thứ tự. Có một hệ thống thẻ mục lục (index) giúp tìm sách nhanh chóng. Muốn tìm cuốn "Harry Potter tập 5"? Tra mục lục, đi thẳng đến kệ số 7, lấy ra. Không cần lục lọi cả thư viện.
Cơ chế Update-in-place
Khi bạn update một dòng dữ liệu, B-Tree sẽ làm gì?
- Tìm đúng cái Page chứa dòng đó trên đĩa (thông qua index).
- Lôi Page đó lên RAM.
- Sửa dữ liệu trong Page.
- Ghi đè (overwrite) Page đó lại vào đúng vị trí cũ trên đĩa.
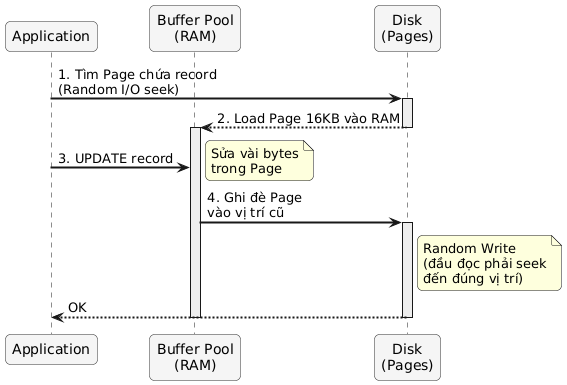
Nhưng khoan đã - nếu server crash giữa chừng khi đang ghi thì sao? Dữ liệu sẽ bị corrupt. Đây là lúc WAL (Write-Ahead Log) xuất hiện.
WAL: Bảo hiểm nhân thọ cho B-Tree
Trước khi sửa bất kỳ Page nào, B-Tree sẽ ghi một bản log vào WAL file trước. WAL này được ghi sequential (nối đuôi) nên rất nhanh. Quy trình đầy đủ là:
- Ghi thay đổi vào WAL (sequential write - nhanh).
- Sửa Page trong RAM.
- Định kỳ flush Page từ RAM xuống đĩa (background).
Nếu crash xảy ra, database có thể replay WAL để khôi phục dữ liệu. Đây là cách MySQL, PostgreSQL đảm bảo durability trong ACID. Giống như việc bạn luôn ghi lại số tiền đã chi trước khi rút ví vậy - có mất ví thì vẫn biết mình đã tiêu bao nhiêu.
Tại sao B-Tree thống trị 40 năm qua?
Vì nó tối ưu cho việc ĐỌC. Muốn tìm user ID=1? B-Tree chỉ cần đi theo các con trỏ (pointers), nhảy vài bước là tới đúng ngay vị trí cuốn sách. Độ phức tạp O(log N). Với 1 tỷ records, bạn chỉ cần khoảng 30 lần so sánh để tìm ra bất kỳ record nào. Ba mươi lần thôi, cho một tỷ records. Không cần lục lọi, không cần đoán mò.
Điểm yếu chết người: Random Write & Page Split
Vấn đề nảy sinh khi bạn muốn GHI nhiều.
Tôi từng xem benchmark của Facebook Engineering khi họ test RocksDB vs InnoDB, và kết quả khá shocking:
| Metric | InnoDB (B-Tree) | RocksDB (LSM-Tree) |
|---|---|---|
| Random Write | 15K ops/sec | 80K ops/sec |
| Sequential Write | 45K ops/sec | 120K ops/sec |
| Point Read | 50K ops/sec | 35K ops/sec |
Tại sao B-Tree write chậm như vậy?
Write Amplification là thủ phạm chính. Để sửa 1 dòng bé tí (vài bytes), B-Tree phải đọc và ghi lại cả một Page 16KB. Nếu bạn update 100 records nằm rải rác ở 100 pages khác nhau, bạn phải ghi 100 x 16KB = 1.6MB dữ liệu. Cho vài trăm bytes data thực tế. Đắt cắt cổ.
Page Split còn tệ hơn. Nếu Page đã đầy mà bạn cố nhét thêm dữ liệu? B-Tree phải chẻ đôi Page đó ra, di chuyển một nửa sang chỗ khác, và cập nhật lại tất cả các pointers liên quan. Giống như việc kệ sách đầy, bạn phải mua thêm kệ mới, chuyển một nửa sách sang, rồi sửa lại hệ thống mục lục. Việc này tốn rất nhiều I/O và có thể gây fragmentation.
Đó là lý do Ép Bê Tông "chết" với MySQL - nó không được thiết kế để hứng hàng triệu write request mỗi giây. Dùng dao mổ trâu để cắt cá, không phải lỗi của dao.
LSM-Tree: Cuốn nhật ký của Phóng viên chiến trường
Khi Big Data bùng nổ (Google, Facebook, LinkedIn), người ta cần thứ gì đó ghi nhanh hơn. Và Log-Structured Merge-Tree (LSM-Tree) lên ngôi. Đại diện tiêu biểu: Cassandra, HBase, LevelDB, RocksDB.
Hãy tưởng tượng Database là một Phóng viên chiến trường:
- Phóng viên không có thời gian để sắp xếp notes ngăn nắp. Có tin gì hot là ghi ngay vào cuốn sổ tay đang mở (MemTable).
- Sổ đầy? Đóng lại, ném vào ba lô, lấy cuốn mới (Flush to SSTable).
- Sai thông tin? Không tẩy xóa - ghi thêm một dòng đính chính ở trang tiếp theo.
- Muốn xóa tin cũ? Ghi một dòng "Tin này đã bị thu hồi" (Tombstone).
- Cuối tuần về văn phòng, phóng viên mới ngồi tổng hợp, loại bỏ tin trùng lặp, sắp xếp lại theo thời gian (Compaction).

Cơ chế Append-only: Triết lý "chỉ viết thêm, không bao giờ sửa"
LSM-Tree không quan tâm dữ liệu cũ nằm đâu. Nó luôn GHI NỐI ĐUÔI (Append). Đây là triết lý hoàn toàn ngược lại với B-Tree.
Bước 1 - MemTable (RAM): Dữ liệu mới luôn được ghi vào một cấu trúc in-memory (thường là Red-Black Tree hoặc Skip List). Cực nhanh vì đây là RAM operation. Không cần tìm kiếm, không cần di chuyển đầu đọc đĩa.
Bước 2 - SSTable (Disk): Khi MemTable đầy (thường khoảng 64MB), nó được "flush" xuống đĩa thành một file gọi là SSTable (Sorted String Table). Điểm đặc biệt: file này là Immutable - ghi xong là chết cứng, không ai được sửa nó nữa. Tại sao? Vì immutable files dễ cache, dễ replicate, và không cần lock khi đọc. Đơn giản mà hiệu quả.
Bước 3 - Compaction (Background): Vì ta cứ tạo file mới liên tục, đĩa sẽ đầy "rác" - nhiều versions của cùng một key, các tombstones chưa được cleanup. Một tiến trình ngầm sẽ chạy định kỳ để gộp các file SSTable nhỏ thành file lớn, giữ lại version mới nhất của mỗi key, và xóa bỏ tombstones đã quá hạn. Giống như việc phóng viên về văn phòng cuối tuần để tổng hợp bài vậy.


Tại sao LSM-Tree là vua tốc độ GHI?
Vì nó sử dụng Sequential I/O (Ghi tuần tự). Đầu đọc ổ cứng không cần nhảy múa - nó chỉ việc chạy một mạch từ đầu đến cuối. Kể cả SSD cũng yêu thích việc này hơn là ghi ngẫu nhiên, vì:
- SSD ghi theo đơn vị pages (4KB-16KB), nhưng xóa theo đơn vị blocks (128KB-512KB).
- Random writes gây ra nhiều erase cycles hơn, giảm tuổi thọ SSD.
- Sequential writes cho phép SSD batch operations hiệu quả hơn.
Nói cách khác, LSM-Tree "chiều" ổ cứng đúng cách mà ổ cứng thích được chiều.
Điểm yếu: ĐỌC phải "lội ngược dòng"
Muốn tìm user ID=1? LSM-Tree phải:
- Check trong MemTable (RAM) - có ghi gần đây không?
- Nếu không, check trong SSTable mới nhất (Level 0).
- Nếu không, check tiếp trong SSTable Level 1...
- Cứ thế lội ngược dòng thời gian qua nhiều files.
Trong worst case, một point query có thể phải đọc hàng chục files. Đây gọi là Read Amplification. Giống như việc phóng viên muốn tìm lại một thông tin cũ, phải lật từng cuốn sổ tay từ mới nhất về cũ nhất vậy.
Bloom Filter: Vị cứu tinh của LSM-Tree
Để giảm bớt nỗi đau đọc, LSM-Tree dùng một cấu trúc dữ liệu probabilistic gọi là Bloom Filter. Tôi cho rằng đây là một trong những phát minh đẹp nhất trong Computer Science.
Bloom Filter trả lời câu hỏi: "File này có chắc chắn KHÔNG chứa key X không?"
- Nếu Bloom Filter nói "KHÔNG" thì 100% chắc chắn không có, skip file này luôn.
- Nếu Bloom Filter nói "CÓ THỂ CÓ" thì phải mở file ra kiểm tra (có thể là false positive).
Cơ chế hoạt động của Bloom Filter khá đơn giản nhưng thiên tài:
- Tạo một bit array với m bits, ban đầu tất cả là 0.
- Dùng k hash functions khác nhau.
- Khi thêm key X: hash X bằng k functions, set k bits tương ứng thành 1.
- Khi query key Y: hash Y bằng k functions, check k bits. Nếu bất kỳ bit nào là 0 thì Y chắc chắn không tồn tại.
Với chỉ 10 bits per key và 7 hash functions, Bloom Filter đạt false positive rate chỉ ~1%. Nghĩa là 99% queries không cần mở file để kiểm tra. Tiết kiệm được 99% công sức lục lọi. Đẹp.
Bảng so sánh: Chọn mặt gửi vàng
| Đặc điểm | B-Tree (MySQL/Postgres) | LSM-Tree (Cassandra/RocksDB) |
|---|---|---|
| Triết lý | Update-in-place (Ghi đè) | Append-only (Ghi nối đuôi) |
| Thế mạnh | Read cực nhanh, Transaction mạnh (ACID) | Write cực nhanh, Nuốt trôi Big Data |
| Điểm yếu | Write chậm (Random I/O), Page Splitting | Read chậm hơn (Check nhiều files), Compaction tốn CPU/IO |
| Write Amplification | Cao (Ghi cả page 16KB cho 1 record nhỏ) | Thấp ban đầu, tăng khi Compaction |
| Read Amplification | Thấp (1 lần seek) | Cao (có thể check nhiều files) |
| Space Amplification | Trung bình (có unused space trong pages) | Thấp (nén tốt, không fragmentation) |
| Use Case | E-commerce, Banking, CMS, Ứng dụng CRUD | Chat Log, IoT Sensor, Activity Tracking, Time-series |
Vậy thi: hãy đo và hiểu workload của mình
Khi thiết kế hệ thống, đừng mù quáng chọn Database vì nó "hot" hay vì ai đó trên Hacker News recommend. Hãy tự hỏi workload của mình là gì.
Chọn B-Tree (MySQL/PostgreSQL) khi:
- Workload của bạn là read-heavy (80%+ reads).
- Cần ACID transactions và complex queries (JOINs, aggregations).
- Data size vừa phải (dưới vài TB).
- Cần strong consistency - đọc luôn thấy dữ liệu mới nhất.
Chọn LSM-Tree (Cassandra/RocksDB/ScyllaDB) khi:
- Workload là write-heavy (IoT sensors, logs, event sourcing).
- Cần scale horizontal lên petabytes.
- Chấp nhận eventual consistency.
- Queries đơn giản (point lookups, range scans by partition key).
Metrics cần monitor:
- Write Latency P99: Nếu > 100ms, B-Tree có thể đang bị page split storm.
- Read Latency P99: Nếu LSM-Tree > 50ms, có thể cần tune compaction hoặc thêm Bloom Filter bits.
- Disk I/O: Check iostat để xem random vs sequential ratio.
- Compaction lag (LSM): Nếu pending compaction bytes tăng liên tục, cần tune compaction throughput.
Và nhớ rằng: Không có bữa trưa nào miễn phí. Muốn Ghi nhanh thì Đọc phải chậm lại một chút. Muốn Đọc nhanh thì Ghi phải tốn sức hơn. Đó là định luật bảo toàn "nỗi đau" trong kỹ thuật phần mềm - hay còn gọi là RUM Conjecture (Read, Update, Memory - chỉ có thể optimize 2 trong 3).
Chương 3 của DDIA còn nhiều thứ hay ho hơn nữa, nhưng tôi nghĩ đây là phần quan trọng nhất. Nếu bạn muốn đào sâu hơn, hãy đọc thêm về Leveled Compaction vs Size-Tiered Compaction, hoặc cách ScyllaDB tối ưu LSM-Tree cho hiệu năng cao hơn.
Hãy giữ cho database của mình khỏe mạnh!