Buffer Overflows Thông Qua Hình Ảnh
Ah, pwn: một trong những thể loại CTF gây nghiện hơn khi bạn đã nắm được cách chơi. Khoảnh khắc khi payload của bạn thực sự hoạt động làm tôi nhớ đến một câu nói tôi từng nghe về toán học: "niềm vui của toán học phần lớn là sự lùi dần của nỗi đau."

Nhưng vì pwn dựa trên rất nhiều lĩnh vực khác - reverse engineering phần mềm, hiểu biết về bộ nhớ máy tính, một số kiến thức lập trình và scripting, kiểu dữ liệu, v.v. - đường cong học tập có thể khá đáng sợ.
"Hello world" của pwn là buffer overflow.
"Hello world" trong lập trình, ít nhất là về lý thuyết, là một ví dụ giúp bạn bắt đầu với một ngôn ngữ mới mà không cần quá nhiều thiết lập hoặc hiểu biết bổ sung.
Như tôi đã ám chỉ, nó phức tạp hơn một chút trong thế giới của pwn. Do đó, hướng dẫn này về buffer overflows.
Tôi không phải là người đầu tiên viết về buffer overflows. Thực tế, nó đã xuất hiện trong Phrack vào những năm 90, và ngay cả điều đó cũng được Aleph One mô tả là một bản ghi chép lại những thứ đã được hiểu ở nơi khác, nếu trí nhớ tôi không nhầm.
Vậy tại sao tôi lại làm lại công việc này?
Bởi vì rất nhiều người (bao gồm cả tôi) học bằng hình ảnh, và tôi đã viết một số phần mềm để giúp người khác hình dung cách tôi nhìn thấy buffer overflows trong đầu. Và tôi hy vọng nó cũng giúp ích cho bạn.
Bài viết này là về việc học buffer overflows theo cách trực quan, bao gồm:
- Một số hoạt ảnh hữu ích tôi đã làm, cộng với một gif tôi đã "mượn"
- Cách tiếp cận kỹ năng pwn để bạn không bị điên (quá nhiều)
- Tại sao reverse engineering giống như ghép hình puzzle ở chế độ khó
- Tại sao stack overflows giống như đối phó với trẻ mới biết đi
- Và phải làm gì khi la hét với máy tính không thực sự giải quyết được thử thách pwn bạn đang làm.
Cộng thêm, tất nhiên, cách buffer overflows hoạt động (có nghĩa là xem xét endianness, ASCII, hex, stack và stack frames, instruction pointers, v.v.). Và nếu bạn hoàn toàn mới, đừng lo, chúng ta cũng sẽ nói về CTFs, pwn, và các công cụ reverse engineering phần mềm.
Pwn và Binary Exploitation
Lưu ý: Tôi sẽ sử dụng pwn và binary exploitation thay thế cho nhau trong bài viết này.
Hướng dẫn này dựa trên một bài nói chuyện mà tôi đã thực hiện, trước COVID, về cách bắt đầu với exploit development. Là một người nghiện CTF, khung tư duy của tôi (và cách tôi trình bày bài nói) chủ yếu xoay quanh các thử thách CTF.
Nhưng pwn không chỉ dành cho CTFs.
Tại sao chúng ta học điều này?
Đúng, giỏi pwn sẽ giúp bạn kiếm được nhiều điểm internet cool (aka CTF flags), nhưng nó còn tốt cho điều gì khác?
Học kỹ năng pwn cũng có thể giúp bạn thực hiện đánh giá bảo mật với tư cách là pentester, lấy chứng chỉ OSCP, hoặc làm nghiên cứu bảo mật, cụ thể là exploit development. Có lý khi bất cứ thứ gì có reverse engineering đều có một chút hiểu biết về "forward" engineering, vì vậy thời gian dành để phân tích các chương trình máy tính cũng có thể giúp bạn trở thành một kỹ sư hoặc developer tốt hơn.
Thêm một vài từ về exploit development:

Những tiêu đề này đều là kết quả thực tế từ kỹ năng pwn (aka exploit development). Exploits, như được thảo luận ở đây, là các công cụ phần mềm được viết để khai thác một số lỗ hổng trong một chương trình cụ thể. Chúng có thể từ proof of concept cho thấy vấn đề tồn tại nhưng vô hại. Nó có thể là thứ được trình bày tại một sự kiện như Pwn2Own, nơi các nhà nghiên cứu chứng minh cách hack các sản phẩm mới thông qua exploits họ đã viết. Hoặc chúng ta có thể nói về exploits được phát triển đầy đủ, dù bởi chính phủ (giữ bí mật) hay bởi hacker chia sẻ chúng với thế giới trên một trang web như ExploitDB.
Exploit development được xây dựng trên rất nhiều lĩnh vực và kỹ năng khác. Một danh sách không đầy đủ:
- Có reverse engineering, trong trường hợp này đề cập đến việc lấy một file binary, là output của source code đã biên dịch, và tái tạo lại chức năng của nó trong đầu để hiểu cách nó hoạt động và có thể có lỗ hổng như thế nào.
- Liên quan đến đó, có binary analysis, là các phương pháp instrumentation xung quanh reverse engineering.
- Có vulnerability discovery hoặc analysis, đề cập đến các cách tìm vấn đề có thể được sử dụng để phát triển exploit. Điều này có thể là xem xét source. Điều này có thể là fuzzing, là ném một loạt input điên rồ vào thứ gì đó để tìm hành vi hoặc code paths không mong muốn.
- Có shellcoding, đề cập đến việc viết các chương trình nhỏ, độc lập để làm điều gì đó như cung cấp quyền truy cập, kết nối ngược lại, v.v. Chúng ta sẽ không đề cập đến điều này trong hướng dẫn này nhưng có thể trong hướng dẫn tương lai.
- Cũng có các kỹ năng nền tảng như lập trình C, assembly, scripting, v.v.
Đó là một tập hợp kỹ năng khá đáng sợ, ngay cả khi bạn đã vượt qua các kỹ năng nền tảng, điều không hề đơn giản.
Chúng ta nên học kỹ năng pwn như thế nào?
Ban đầu tiêu đề là "cách tốt nhất để học pwn là gì?" nhưng tôi không thể trả lời điều đó cho bạn, tôi chỉ có thể chia sẻ những gì hiệu quả với tôi.
Người ta nói rằng với một cái búa, mọi vấn đề đều trông giống như cái đinh, và với tư cách là một người nghiện CTF, tôi nghĩ các thử thách CTF là cách tuyệt vời để giải quyết bộ kỹ năng lớn này.
CTF (capture the flag) là một cuộc thi hacking nơi bạn được cung cấp một loạt thử thách được tạo đặc biệt cho cuộc thi đó (bạn không chỉ hack những thứ ngẫu nhiên), và nếu bạn giải quyết một thử thách, bạn sẽ nhận được điểm. Người hoặc đội có nhiều điểm nhất sẽ thắng.
CTFs có nhiều danh mục khác nhau để phản ánh các khía cạnh khác nhau của infosec. Hai trong số đó là reverse engineering, mà chúng ta đã biết, và "pwn", có thể coi như reverse engineering ứng dụng + shellcode. Mục tiêu là sử dụng lỗ hổng trong chương trình (thường được tìm thấy thông qua reverse engineering hoặc xem xét source) để khiến chương trình làm những điều không mong muốn, như đọc file flag từ máy tính.
Danh mục pwn, còn gọi là binary exploitation, cho phép chúng ta thực hành reverse engineering, khám phá exploit, phát triển exploit, shell coding, mọi thứ trong một.
CTFs tuyệt vời vì chúng có thể lừa bạn dành nhiều thời gian học một khái niệm mới theo cách cảm thấy vui hơn so với học sách truyền thống, bởi vì bạn nhận được điểm ở cuối.
Và, nếu bạn sắp xếp mọi thứ đúng cách, bạn có thể "leo cầu thang" từ binary exploitation rất cơ bản đến các thử thách phức tạp hơn.
Đây là ý tưởng về nơi bạn có thể đến:
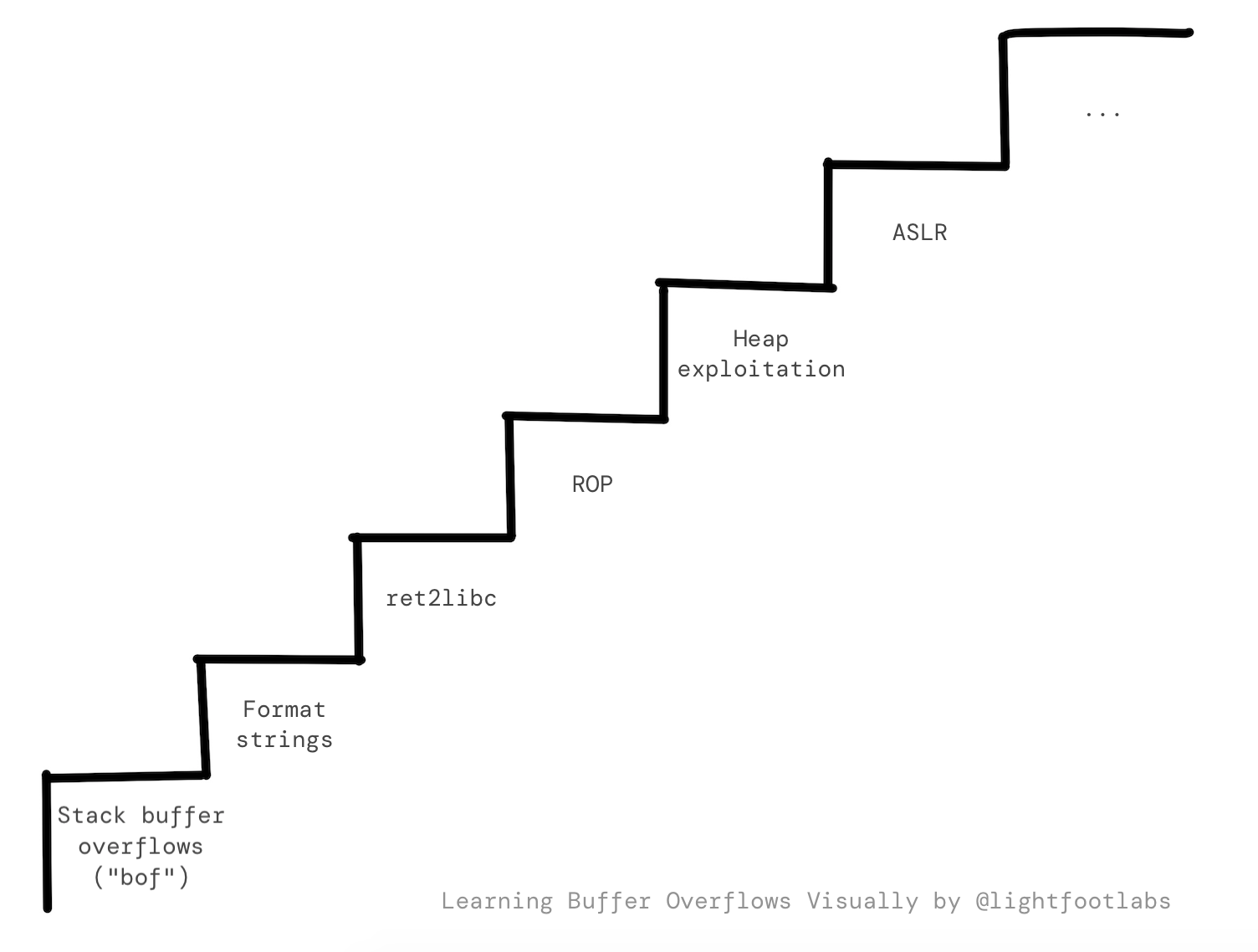
Đồ họa này cũng không đầy đủ, nhưng hy vọng nó cho bạn một ý tưởng. Nó cũng gần như theo con đường lịch sử mà exploit development đã đi qua: hacker phát hiện một lỗ hổng, và nó được vá hoặc giảm thiểu. Vì vậy họ phải phát hiện cái khác, và cái khác nữa, trong một trò chơi mèo vờn chuột không bao giờ kết thúc.
Công Cụ Software Reverse Engineering
Khi tôi cố gắng giải thích software reverse engineering (RE) cho người ngoài lĩnh vực, tôi giải thích như thế này:
Hãy tưởng tượng bạn được cho một hộp mảnh ghép mà không có hình ảnh trên hộp để giúp bạn ghép lại. Bạn có thể tìm ra hình ảnh đó là gì không?
Trong phép so sánh của chúng ta, bạn có thể làm gì để bắt đầu? Một chiến lược ghép hình cổ điển là tìm tất cả các mảnh cạnh, và ghép chúng lại với nhau. Điều này cho bạn một loại khung, cảm giác định hướng, một điểm khởi đầu.
Không khác với câu đố ghép hình của chúng ta, software reverse engineering cũng được hưởng lợi từ việc định hướng. Kiến trúc là gì? Điểm bắt đầu của chương trình ở đâu? Có bất kỳ mẫu hoặc đường dẫn nào chúng ta thấy khi đã đến điểm đó không?
Các công cụ Software RE có thể giúp chúng ta làm điều này, dù đó là công cụ dòng lệnh, script phân tích binary, hay các công cụ RE phổ biến như Ghidra, Binary Ninja, và IDA Pro. Những công cụ này cho phép chúng ta xác định những điều về chương trình chúng ta đang phân tích, dù đó là kiến trúc là gì, chương trình bắt đầu ở đâu, và những đường dẫn nào nó có thể đi từ đó.
Quay lại phép so sánh của chúng ta: khi bạn đã sắp xếp xong đường viền, bạn có thể bắt đầu chọn các mảnh ghép dựa trên màu sắc hoặc hoa văn có vẻ đi cùng nhau. Sau đó bạn ghép lại các mảnh nhỏ của câu đố cho bạn manh mối về bức tranh lớn hơn có thể trông như thế nào.
Điều này không khác với cách các công cụ SW RE cho phép bạn xem các nhóm mã máy liên quan (có khả năng) tương ứng với các hàm hoặc hàm con trong chương trình. Tôi nói "có khả năng" vì trong cả hai trường hợp - sử dụng công cụ RE và ghép lại câu đố - bạn đang làm việc ngược để xấp xỉ điều thực, nhưng không đảm bảo rằng bạn hoặc công cụ của bạn sẽ diễn giải mọi thứ đúng cách.
Cách điều này thực sự hoạt động là một chủ đề hoàn toàn khác, nhưng bây giờ, các phần quan trọng là:
- Disassembler: lấy file binary và hiển thị nó dưới dạng assembly cho một kiến trúc nhất định.
- Decompiler: lấy file binary và xấp xỉ source code gốc.
- Debugger: xem và thay đổi trạng thái đang chạy của chương trình.
Chúng ta đã đề cập đến reverse engineering khá nhiều nhưng chưa thực sự định nghĩa nó, vì vậy hãy làm điều đó ngay bây giờ. Nếu "forward" engineering trông như thế này, về mặt chương trình máy tính:

Thì reverse engineering trông như thế này:
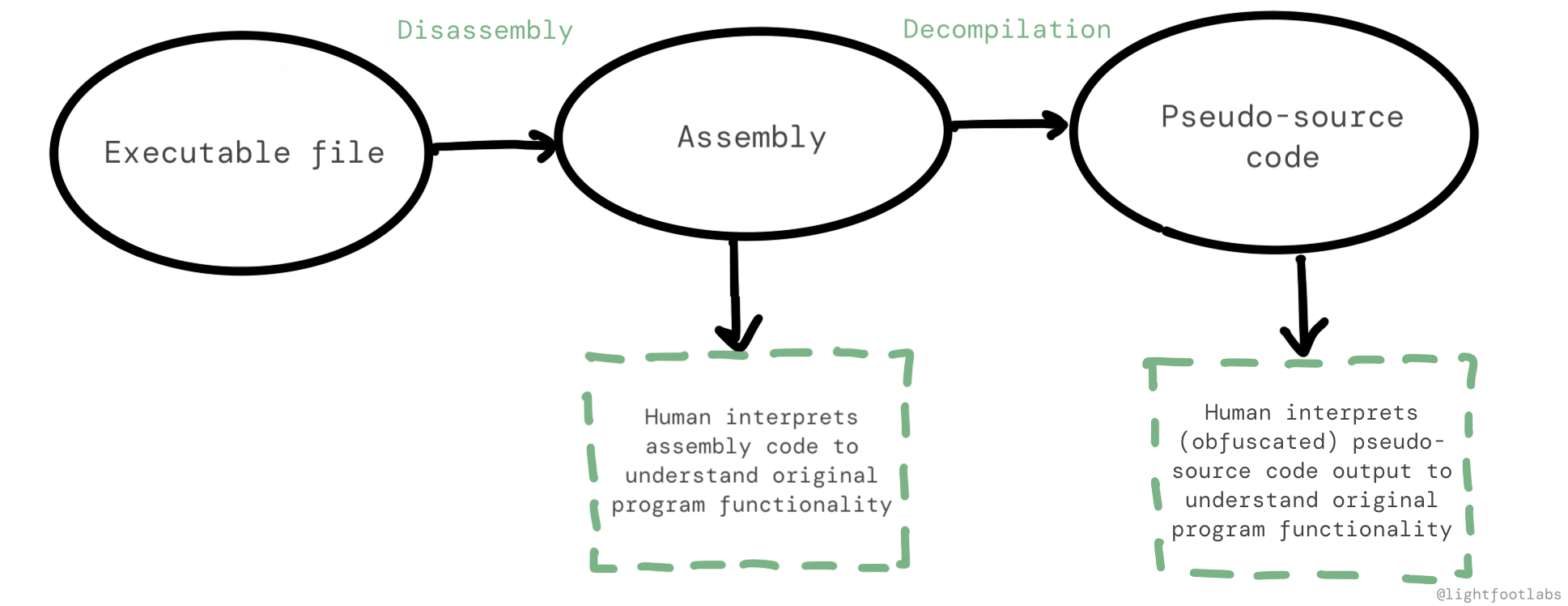
Nói cách khác, reverse engineering lấy output của quy trình bình thường ("forward"), và sử dụng kết hợp các công cụ phần mềm và sự hiểu biết của con người để hiểu chức năng và ý định ban đầu.
Tôi đã nhóm cả disassembly và decompilation lại với nhau trong sơ đồ này. Nếu bạn sử dụng disassembler như gdb, bạn có thể xem các instruction assembly, và sau đó tùy thuộc vào sự hiểu biết của bạn để xây dựng mô hình tinh thần từ đó.
Nếu bạn sử dụng decompiler, đó là thêm một bước nữa trong sơ đồ, nhưng output vẫn đòi hỏi nỗ lực từ phía bạn. Ngôn ngữ cấp cao được tái tạo là một xấp xỉ, và có thể xuất hiện bị obfuscate vì những thứ như tên biến và comment không có ở đó.
Disassemblers, decompilers, và debuggers là các công cụ chúng ta sẽ sử dụng để ghép lại câu đố. May mắn cho chúng ta, các ví dụ sau sẽ chứa hình ảnh câu đố gốc, có thể nói vậy.
Buffer Overflow Cơ Bản, AKA La Hét Với Máy Tính
Đủ tán gẫu rồi, hãy bắt đầu thôi.
Hướng dẫn này sẽ sử dụng các ví dụ từ exploit.education, một trang web với bộ môi trường thực hành pwn tuyệt vời. Cụ thể, đây là level 0 từ Protostar
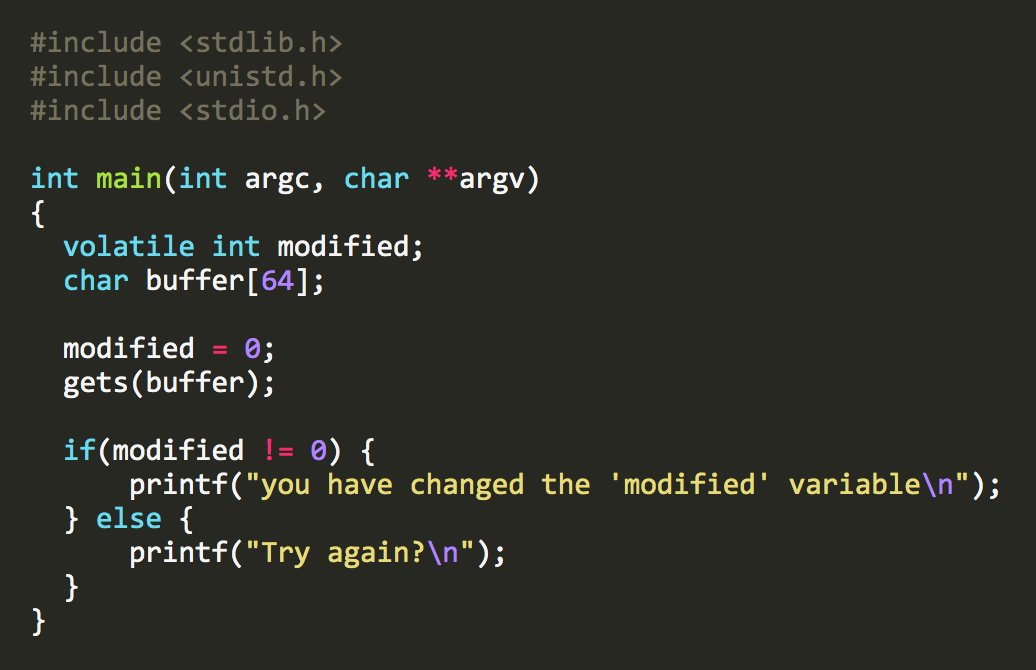
Chúng ta cần biết đủ về C để hiểu điều gì đang xảy ra ở đây. Nếu giải thích sau vẫn chưa đủ, tôi khuyên bạn nên xem tài nguyên trực tuyến này, và/hoặc đọc chương thứ hai của Hacking: The Art of Exploitation.
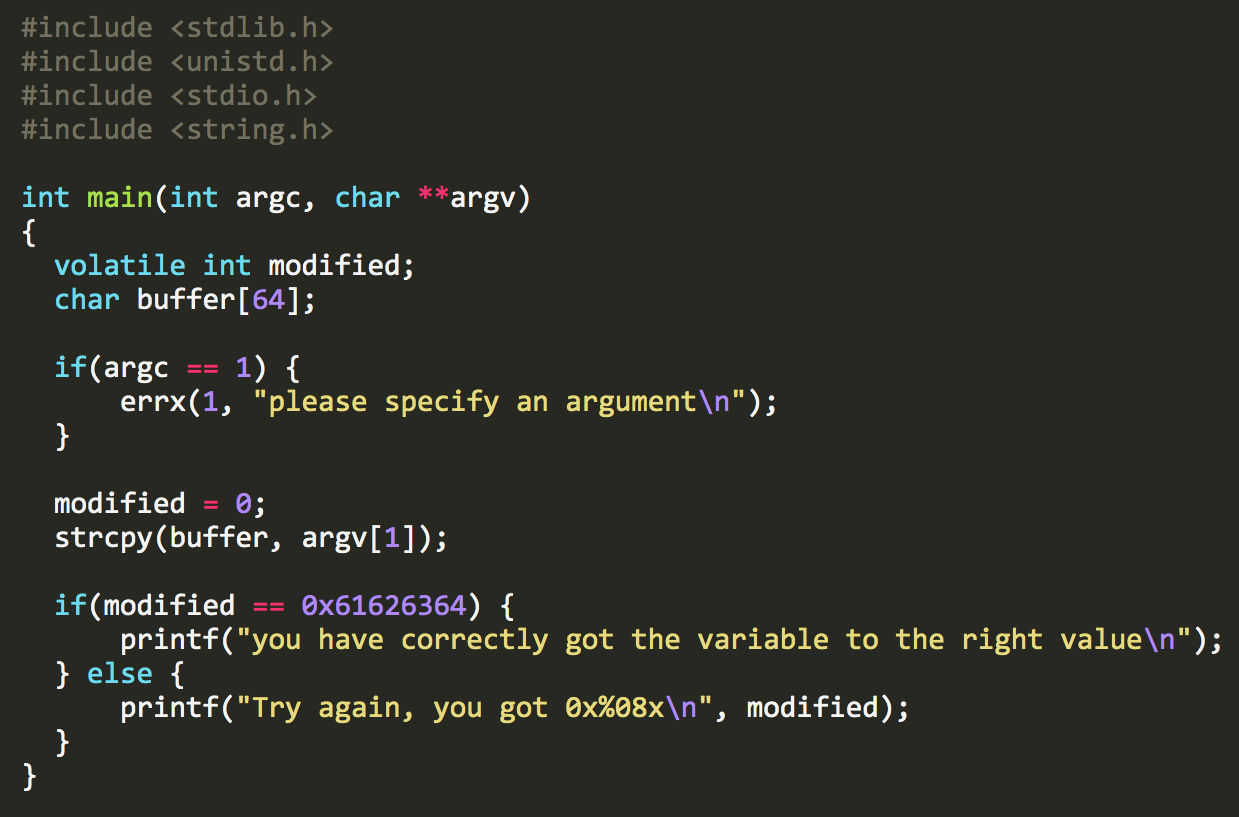
Đây là một bản sao đã được đánh dấu mà tôi sẽ giải thích nhanh. Hãy bỏ qua nếu bạn đã quen thuộc với C.
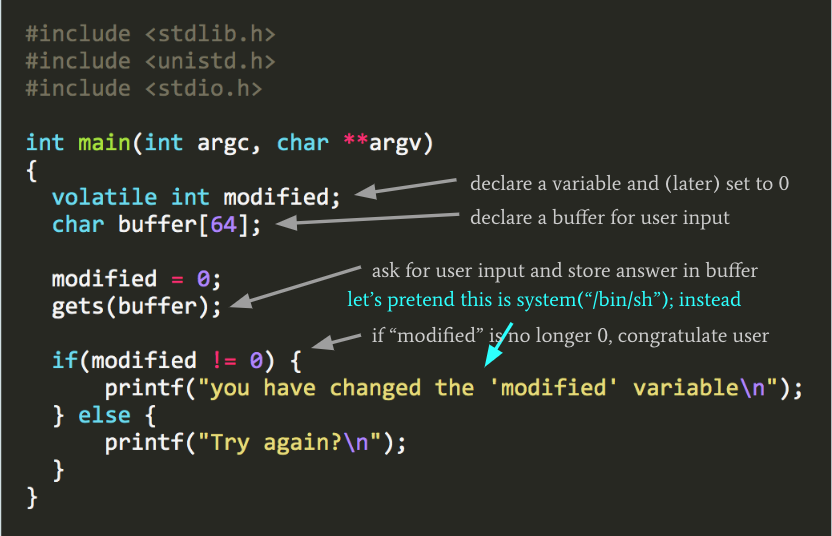
- Trước tiên chúng ta
includemột số thư viện chuẩn định nghĩa các kiểu biến và các hàm I/O chúng ta muốn sử dụng, nhưgets()vàprintf(). - Chúng ta định nghĩa hàm
mainvới dòngint main(...). Phầnargcvàargvcó nghĩa là hàm có thể chấp nhận đối số dòng lệnh (nhưng chương trình của chúng ta không sử dụng chúng, trong trường hợp này). - Chúng ta định nghĩa một biến gọi là
modified. Nó có kiểuinteger(hoặcintđể ngắn gọn), định nghĩa kích thước của nó và giá trị nào chúng ta mong đợi lưu trong biến. Nó được đánh dấuvolatile, có nghĩa là chúng ta muốn compiler biết giá trị của nó có thể thay đổi bất ngờ. Nói cách khác, chúng ta đang yêu cầu compiler đừng tối ưu hóa code có vẻ như là dead end. - Chúng ta khai báo biến buffer dài 64
char. Chúng ta sẽ sử dụng này để lưu input người dùng mà chúng ta sẽ yêu cầu trong một phút. - Chúng ta đặt
modifiedthành 0. - Chúng ta gọi
gets()với đối sốbuffer. Khi chương trình này được chạy từ dòng lệnh, nó sẽ nhắc người dùng nhập input khi đến bước này. Sau đó, chương trình sẽ lưu input được cung cấp trong biếnbuffer. - Sau đó, chúng ta kiểm tra xem
modifiedcó vẫn bằng 0 không. Nếu có, in ra lời chúc mừng. Nếu không, chà, chúc may mắn lần sau.
Tôi biết bạn đang nghĩ gì: điều này khá ngớ ngẩn. Có lý do gì để modified không bằng 0, dựa trên những gì chúng ta vừa thảo luận?
Thật không may, ngôn ngữ lập trình C làm cho việc tự bắn vào chân mình trở nên rất dễ dàng. Bạn phần lớn chịu trách nhiệm cho việc quản lý và an toàn bộ nhớ của riêng mình.
Mặc dù nhìn vào assembly không phải là điểm của level này, đây là assembly, được xem với gdb <stack0 program filename>.
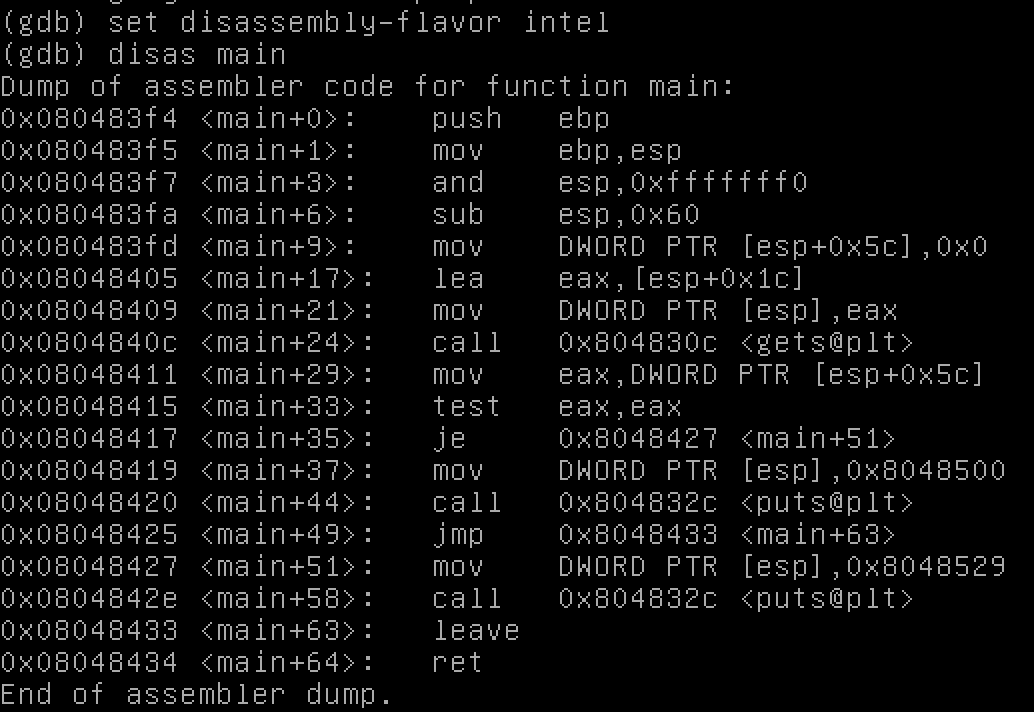
Không có gì quá bất ngờ ở đây. Như trước, chúng ta load giá trị 0 vào một biến, gọi gets, và sau đó có một if/else (xuất hiện ở đây như je hoặc jump-if-equal). Sau đó chúng ta in ra một thông báo, sử dụng puts.
Chúng ta sẽ đi sâu hơn vào assembly trong các level tương lai, tôi chỉ muốn đề cập ngắn gọn ở đây.
Bạn không cần hiểu từng dòng (mặc dù điều đó sẽ tốt), nhưng hiểu đủ để đạt được mục tiêu của chúng ta.
Nhưng mục tiêu của chúng ta là gì?
Về mặt bề ngoài, mục tiêu của chúng ta là nhận được sự xác nhận ngọt ngào khi chương trình in ra "You have changed the 'modified' variable". Có thể trong tương lai điều này sẽ là thứ gì đó ngầu hơn, như thực thi code, nhưng bây giờ chỉ cần chấp nhận rằng ngôn ngữ tình yêu của chương trình là Words of Encouragement.
Nhưng ở cấp độ tổng quát hơn: làm thế nào chúng ta có thể mô tả những gì chúng ta đang cố gắng đạt được, theo cách không gắn với chi tiết cụ thể của một chương trình này?
Tìm (các) điểm kiểm soát sẽ cho phép tôi thay đổi luồng của chương trình.
"Điểm kiểm soát" có nghĩa là gì? Tôi tin rằng tôi đã học thuật ngữ này từ Hacking: The Art of Exploitation. Nó có nghĩa là tìm các phần cụ thể trong chương trình nơi một quyết định logic được đưa ra, dựa trên trạng thái hoặc dữ liệu mà chúng ta có khả năng ảnh hưởng. Sau đó, lật đổ đường dẫn dự định để ủng hộ cái chúng ta muốn thay thế.
Ở đây? Có một khối if/else. Nếu modified không bằng 0, in ra một thông báo. Else, in ra thông báo khác. Điểm kiểm soát của chúng ta là kiểm tra if/else, nhưng không có cách rõ ràng để thay đổi nó, dựa trên code C.
Tôi biết, tôi đã hứa hình ảnh. Chúng ta gần đến rồi, hãy kiên nhẫn thêm vài phút nữa.
Nếu không có gì trong code C cho phép chúng ta thay đổi giá trị của modified một cách logic, và cũng không có gì rõ ràng trong assembly, các lựa chọn của chúng ta là gì? Có lẽ chúng ta đang đưa ra giả định về cách chương trình sẽ hoạt động. Chúng ta nên làm gì?
Hãy thử la hét với máy tính
Khi mọi thứ khác thất bại, bạn đã thử:

Hãy thử điều đơn giản nhất chúng ta có thể nghĩ đến: gõ một loạt chữ A.

Điều đó… đã hoạt động?! "You have changed the modified variable". Tuyệt. Tôi đoán vậy.
Tại sao điều này hoạt động?
Điều duy nhất tệ hơn với tư cách là developer so với code của tôi không hoạt động và tôi không biết tại sao là code của tôi hoạt động và tôi không biết tại sao. Vì vậy hãy đào sâu hơn.
Chúng ta đã xem code C và các instruction assembly cho level này. Điều đó có nghĩa là bất cứ điều gì chúng ta có thể tìm thấy với disassembler (sẽ hiển thị cho chúng ta assembly) hoặc decompiler (sẽ xấp xỉ code C gốc) sẽ không giúp chúng ta nhiều. Chúng ta đã có thông tin đó.
Hãy thử sử dụng debugger và xem có điều gì chúng ta có thể nhận thấy về trạng thái của chương trình không.
Chúng ta biết rằng có hai biến (theo nghĩa đen) đang hoạt động ở đây: buffer, và modified. Buffer là cái chúng ta có quyền kiểm soát trực tiếp qua input gets() của chúng ta, và modified là cái chúng ta muốn, ừm, sửa đổi.
Nếu chúng ta sử dụng gdb lần nữa, chúng ta có thể xem trạng thái của chương trình trước input của chúng ta, bằng cách đặt breakpoint tại 0x08048405 (tương ứng với dòng 11 trong code C), yêu cầu chương trình tạm dừng và cho phép chúng ta nhìn xung quanh. Sau đó trong khi tạm dừng đó, chúng ta sẽ xem nội dung bộ nhớ và xem modified và buffer ở đâu.
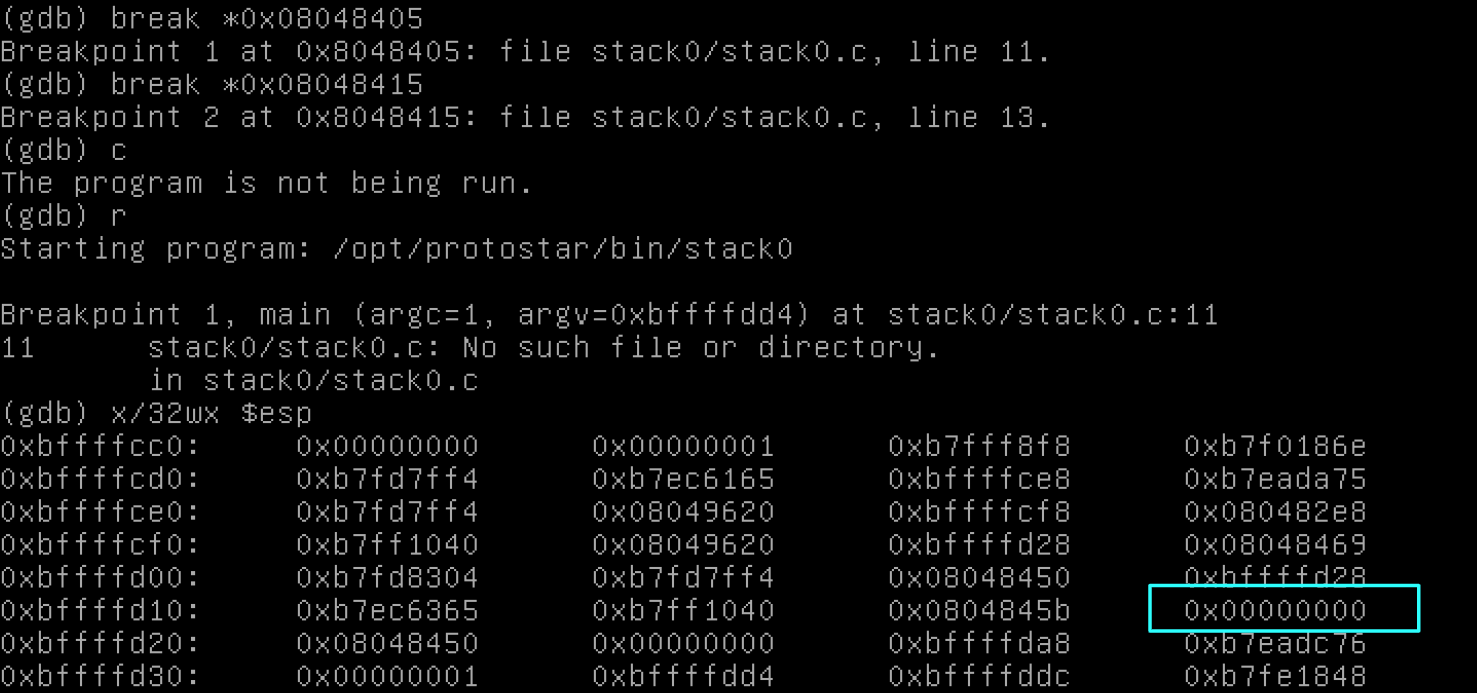
Sau đó chúng ta sẽ gõ c để tiếp tục, gõ (hoặc la hét) tất cả chữ A của chúng ta lần nữa, và dừng tại một breakpoint đã đặt sẵn khác. Khi chúng ta đến đó, bộ nhớ trông như thế này:
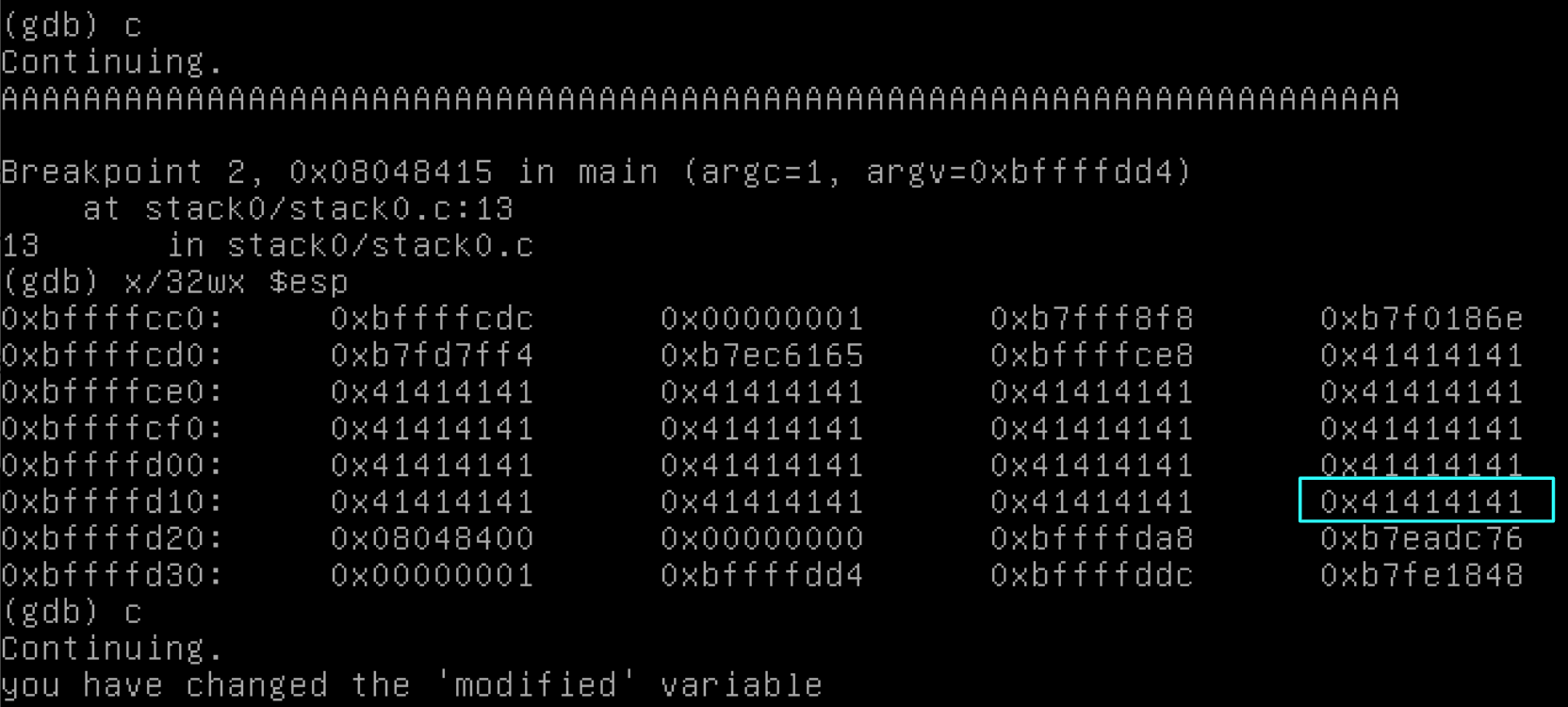
Có vẻ như biến buffer đã đầy với input của chúng ta và sau đó tràn vào bộ nhớ đến sau nó, đó là modified. Điều đó hơi khó hiểu vì chúng ta đã khai báo modified trước, trước buffer.
Cuối cùng: thời gian cho một số hình ảnh stack.
Hình Dung Stack
Không nghi ngờ gì, gdb là một công cụ tốt có thể được làm tốt hơn với các extension như gef hoặc pwngdb.
Nhưng theo ý kiến của tôi, những công cụ này vẫn không cho chúng ta thấy một cái nhìn tuyệt vời về những gì đang xảy ra (đặc biệt nếu bạn đang cố gắng hiểu lần đầu tiên), vì vậy hãy tạo một sơ đồ.
Trước tiên và quan trọng nhất: đây là một chương trình máy tính, và vì vậy mọi biến, hàm, v.v. tồn tại ở đâu đó trong bộ nhớ. Thay vì dạy bạn cấu trúc dữ liệu máy tính từ trên xuống, chúng ta sẽ bắt đầu với những gì chúng ta cần hiểu trước.
Các biến buffer và modified tồn tại trên một cấu trúc dữ liệu gọi là stack. Chúng ta sẽ đi vào chi tiết hơn sau, nhưng bây giờ, chúng ta có thể nghĩ về nó như một tờ giấy nháp cho những gì chương trình đang làm hiện tại.
Vì chúng ta chỉ có một hàm trong level này (hàm main), chúng ta sẽ tập trung vào stack là nơi lưu trữ các biến cục bộ trong một hàm nhất định.
Stack phát triển xuống dưới, có nghĩa là nó bắt đầu ở địa chỉ bộ nhớ cao hơn, và với mỗi biến hoặc phần dữ liệu mới được thêm vào, các địa chỉ bộ nhớ tiếp theo thấp hơn. Đúng, tôi biết, kỳ lạ.
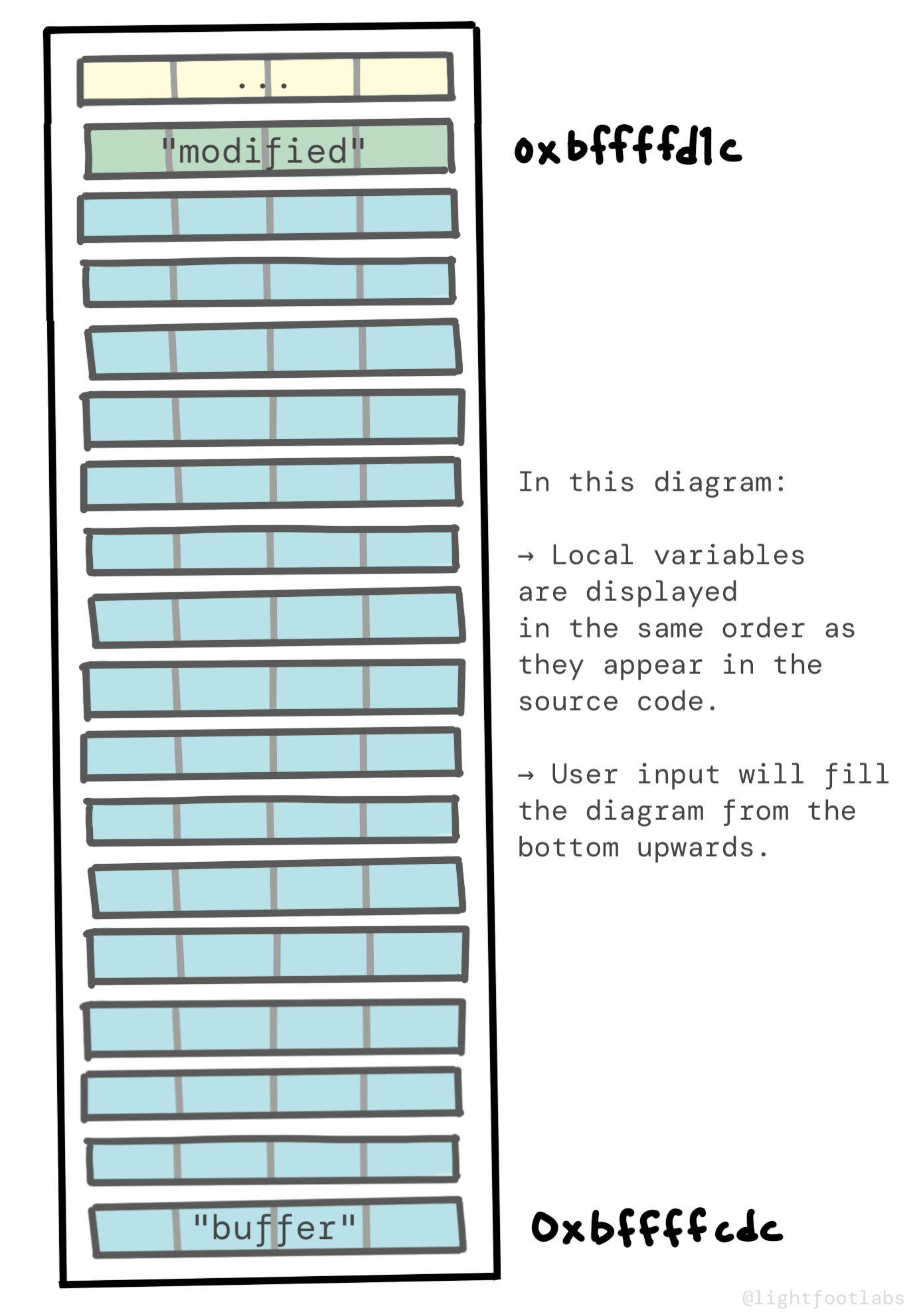
Chúng ta định nghĩa biến modified trước, được đặt tại 0xbffffd1c, và chiếm 4 byte, hoặc 32 bit.
Tiếp theo, chúng ta khai báo biến buffer, chiếm 64 byte. Vì stack đang phát triển về phía địa chỉ bộ nhớ thấp hơn, điều này được đặt 64 byte trước modified, tại 0xbffffcdc. Nhớ rằng mỗi mục mới trên stack sẽ có địa chỉ thấp hơn trong bộ nhớ. 0xbffffd1c - 64 byte = 0xbffffcdc.
Tóm lại: buffer được đặt trước modified về mặt địa chỉ bộ nhớ.
Chúng ta có thể vẽ sơ đồ với địa chỉ cao hơn ở trên cùng, có nghĩa là modified nằm trên buffer về mặt hình ảnh. Trong trường hợp này, khi chúng ta bắt đầu thêm dữ liệu của mình ("AAAA…"), nó sẽ điền từ dưới lên trên. Điều này trực quan theo nghĩa chúng ta đang hiển thị các biến theo thứ tự chúng xuất hiện trong code C, nhưng có thể không trực quan ở chỗ các địa chỉ bộ nhớ đang đếm ngược.
Hoặc, chúng ta có thể vẽ sơ đồ với địa chỉ cao hơn ở phía dưới. Điều này có nghĩa là các biến của chúng ta được hiển thị theo thứ tự 'ngược' so với cách chúng ta định nghĩa chúng trong code. Nhưng khi chúng ta bắt đầu thêm dữ liệu của mình (mà chúng ta sẽ thấy trong một phút), nó điền từ đỉnh của sơ đồ xuống dưới. Điều này trực quan hơn với cách chúng ta viết bình thường.
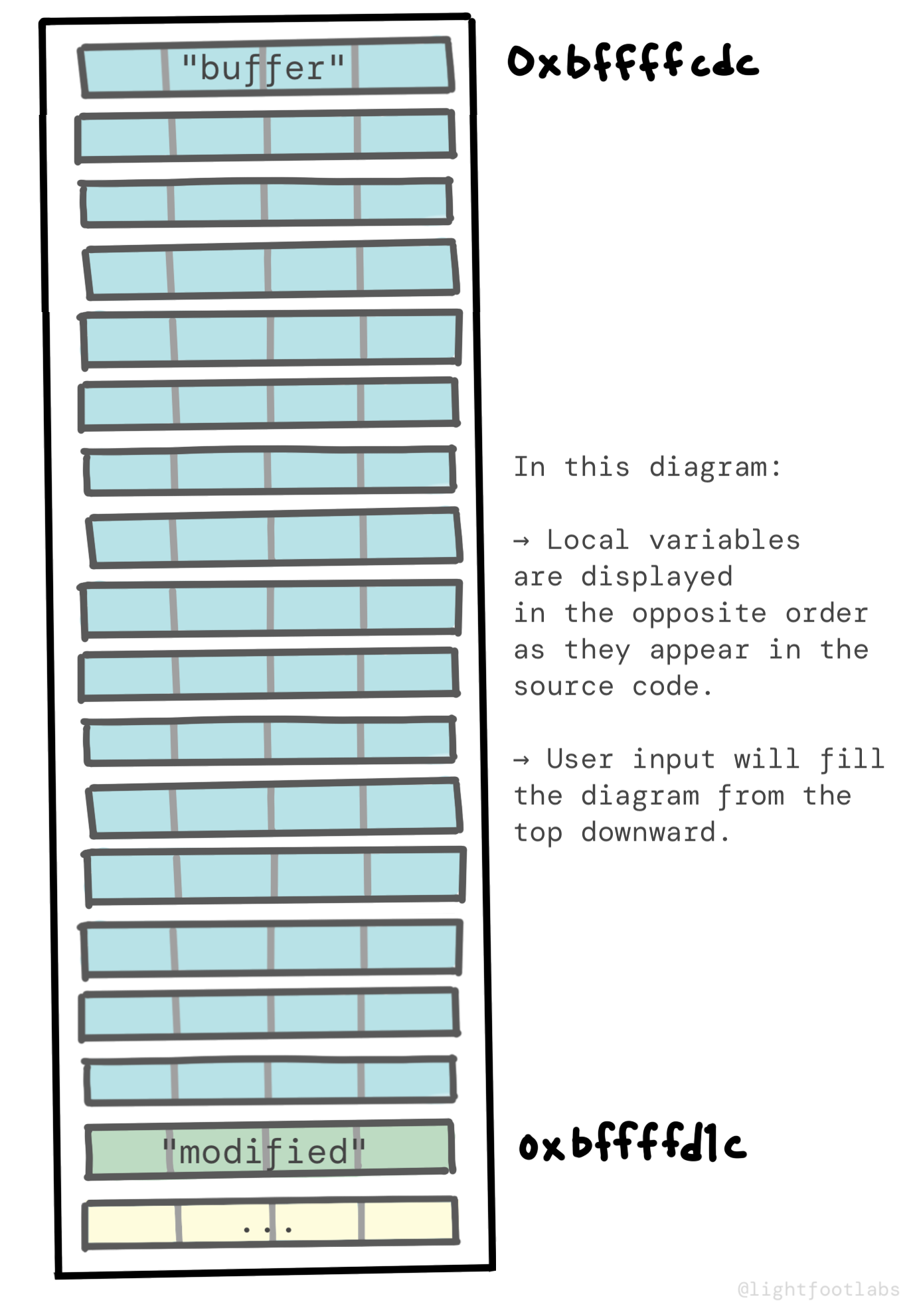
Tôi không nghĩ rằng một cách nhìn tốt hơn cách kia. Mỗi cách đều có điều gì đó trực quan và không trực quan về nó, vì vậy hãy chọn cái có ý nghĩa nhất với bạn và gắn bó với nó trong các phần sau.
Hình Dung User Input
Tôi đã viết một chương trình web đơn giản cho phép bạn nhập một chuỗi, giống như những gì chúng ta đang làm với chương trình dòng lệnh của mình. Sau đó, nó dịch input ("A") thành hex tương đương (41). Sự tương đương này dựa trên tiêu chuẩn ASCII, mà chúng ta sẽ nói trong level tiếp theo. Không có gì đặc biệt về việc sử dụng chữ "A", nó chỉ là chất độn.
Trong đầu tôi, việc bộ nhớ điền lên trên và sau đó tràn ở trên cùng có ý nghĩa hơn, giống như đổ đầy một ly nước:
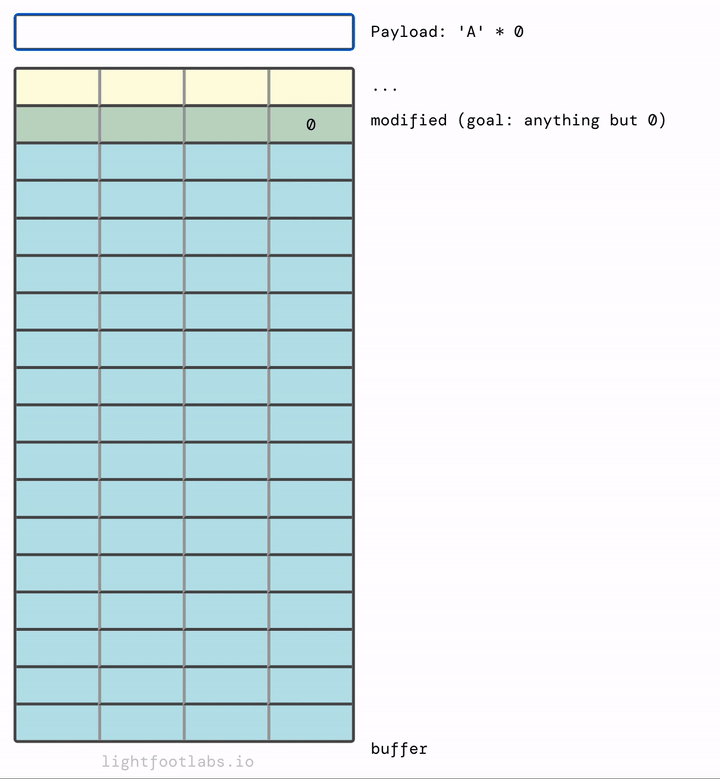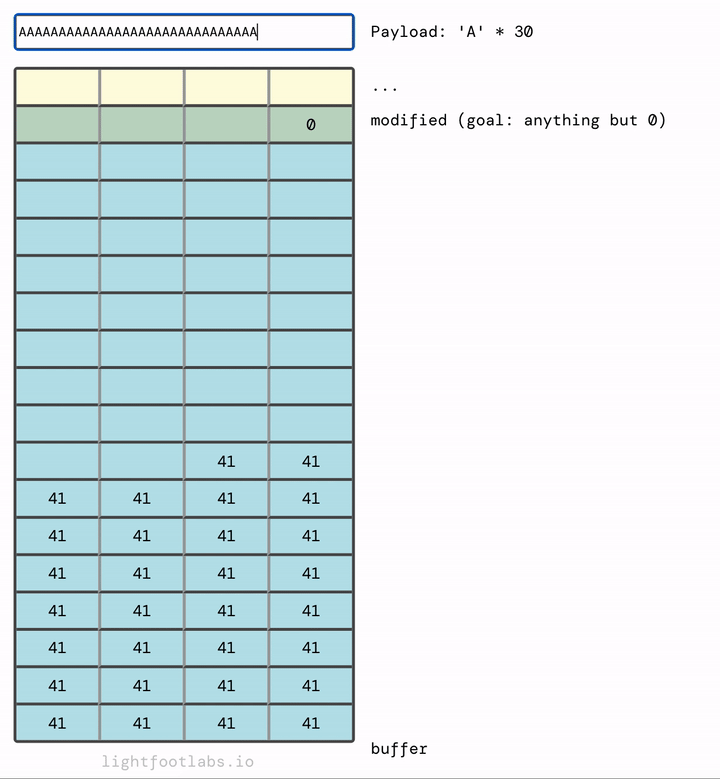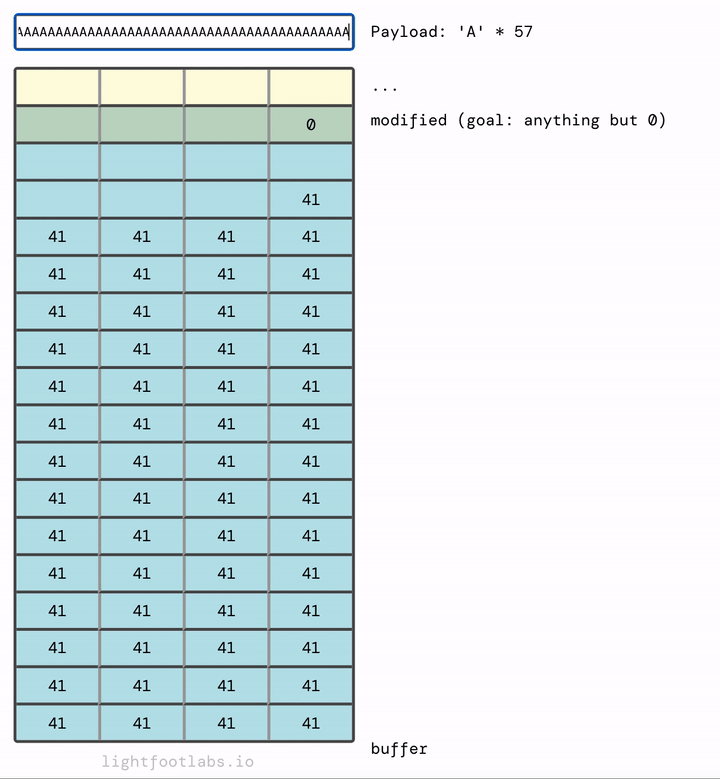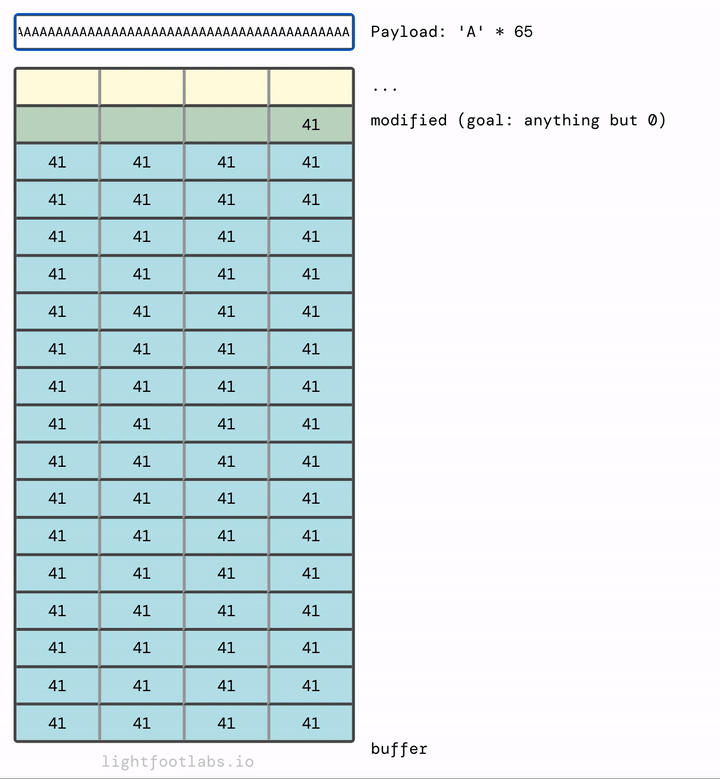
Nếu bạn thấy trực quan hơn khi dữ liệu điền từ trên xuống dưới, như điền vào một tờ giấy, đây là:
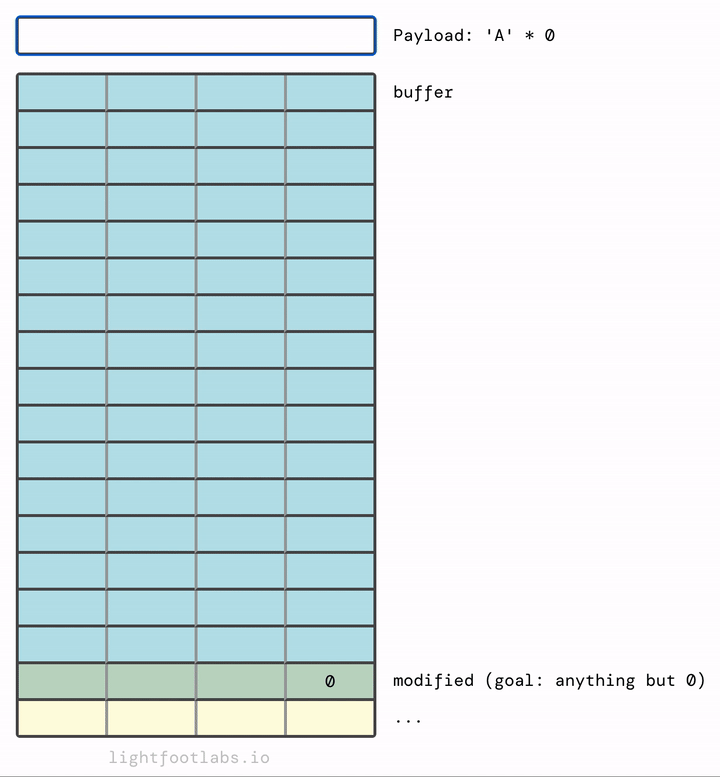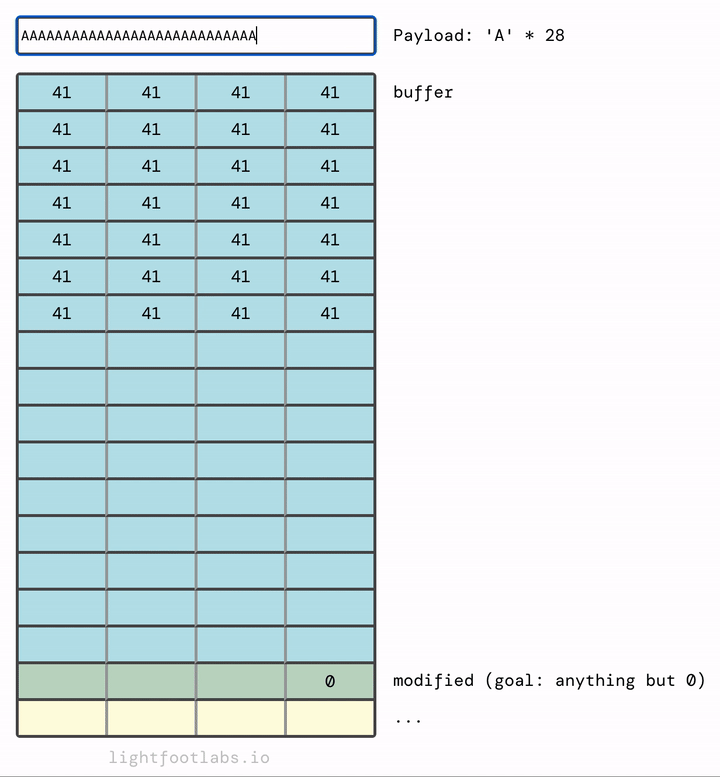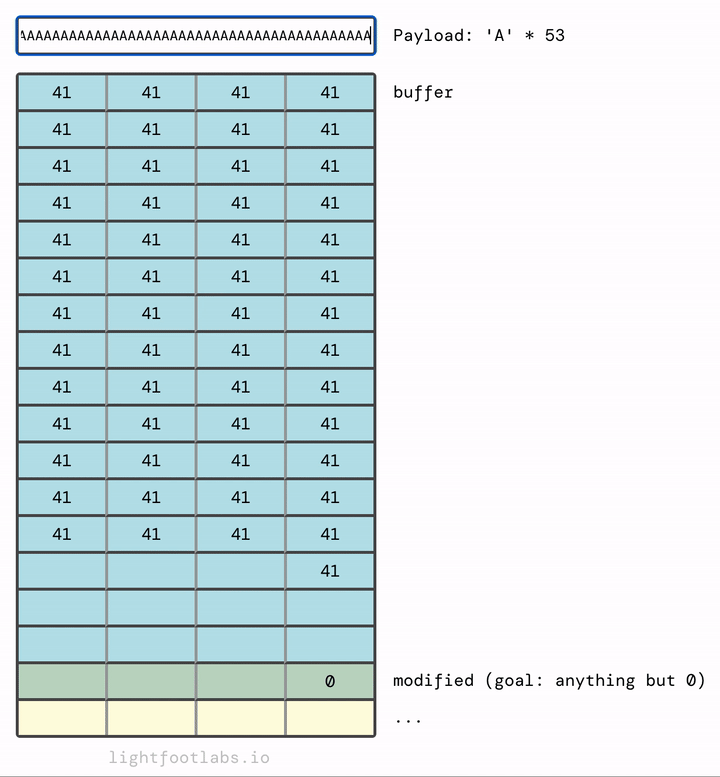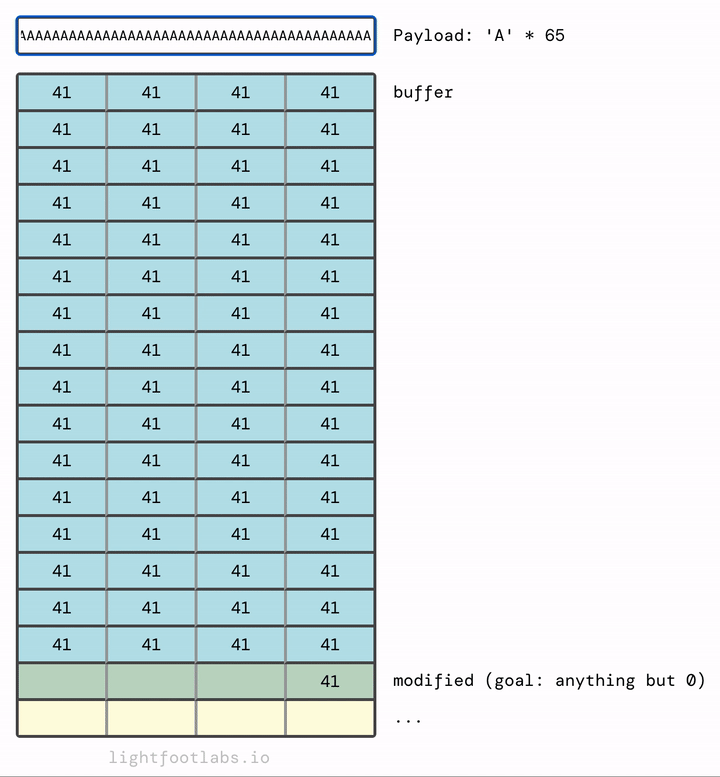
Tại sao nó điền từ trái sang phải? Và cấu trúc "stack" kỳ diệu này ở đâu so với… bạn biết đấy, mọi thứ khác? Hãy ghi nhớ cả hai suy nghĩ đó, chúng ta sẽ đến đó trong một phút.
Nếu chúng ta thêm đủ, chúng sẽ tràn vào thứ tiếp theo trong bộ nhớ, đó là biến modified mà chúng ta đang cố gắng sửa đổi.
Bạn có thể đã đoán rằng chúng ta không cần nhiều chữ A như tôi đã sử dụng. Chúng ta cần 64 chữ A để lấp đầy buffer, cộng với bất kỳ giá trị (đơn lẻ) khác không nào sau đó. 65 chữ A sẽ hoạt động. Cũng như 64 chữ A và sau đó là bất kỳ giá trị nào khác, như "B" (rất sáng tạo!)
Để giải quyết level này, chạy chương trình, và sau đó nhập 64 ký tự độn (như "A") và sau đó một ký tự bổ sung sẽ tràn vào biến modified.
Nếu bạn muốn làm điều này theo chương trình thay vì đếm: $(python -c "print('A'*64 + 'B')") | ./stack0
Những Điều Rút Ra Từ Stack Buffer Overflow
Chúng ta đã học được gì từ bài tập này?
- Các biến được lưu trữ theo thứ tự ngược lại so với mong đợi, về mặt địa chỉ bộ nhớ
- C rõ ràng không biết hoặc không quan tâm đến out-of-bounds.
- Đã thấy một số cách sử dụng gdb
- Chúng ta có thể tràn vào các biến khác**
**nếu không có kiểm tra out-of-bounds và chúng ta sử dụng hàm dễ bị tổn thương như gets()
Stack Overflow 2 Stack 2 Furious
Tiếp tục với bài tập tiếp theo trong series Protostar: stack1.
Code của chúng ta đã thay đổi một chút, và cùng với nó, điểm kiểm soát của chúng ta cũng đã thay đổi.
Bây giờ có một khối if/else nơi chúng ta đang kiểm tra modified bằng 0x61626364.
Hai thay đổi khác trong file này là:
- Bây giờ chúng ta đang sử dụng đối số dòng lệnh.
- Chúng ta đang sử dụng
strcpy()để di chuyển chúng vào buffer, trong khi trước đây, chúng ta đang nhắc nhập input sau bằng cách sử dụnggets().
Vì mục đích của bài tập này, kết quả là như nhau: các hàm không an toàn được sử dụng để di chuyển user input vào buffer có giới hạn kích thước, mà không quan tâm đến độ dài thực tế của buffer. Tôi không chắc tại sao exploit.education quyết định thay đổi mọi thứ ở đây.
Tóm lại: trước đây chúng ta chỉ cần thay đổi modified từ 0 thành… bất cứ thứ gì trừ 0. Ở đây, chúng ta cần tinh tế hơn một chút.
0x61626364 này là gì?
Ký Tự ASCII
Dữ liệu có thể được biểu diễn theo nhiều cách khác nhau: binary, decimal, hexadecimal, ASCII, v.v. Cách chúng ta biểu diễn dữ liệu thường là vì lợi ích của con người. Máy tính có thể lưu trữ mọi thứ dưới dạng 1 và 0, nhưng con người không muốn đọc 01101000 01100101 01101100 01101100 01101111, họ muốn thấy hello được hiển thị. Cùng một dữ liệu, biểu diễn khác nhau. Bạn có thể thử điều này tại ASCII to Hex nếu muốn.
Hexadecimal là một phương pháp khác để hiển thị dữ liệu. Từ hello cũng có thể được hiển thị là 68 65 6c 6c 6f.
Bạn có thể đang nghĩ: binary sang decimal sang hexadecimal… được rồi, đó đều là số và toán. Nhưng làm thế nào chúng ta ánh xạ giá trị sang chữ cái và ký tự?
Đó là lúc tiêu chuẩn ASCII xuất hiện, có từ những năm 1960 với một số cập nhật kể từ đó.
Tôi biết bạn không đến đây để học lịch sử, vậy phần nào chúng ta nên quan tâm ở đây? Với bảng ASCII bên dưới, bạn có thể biết rằng 0x61 tương ứng với chữ a thường, 0x62 với chữ b thường, v.v.
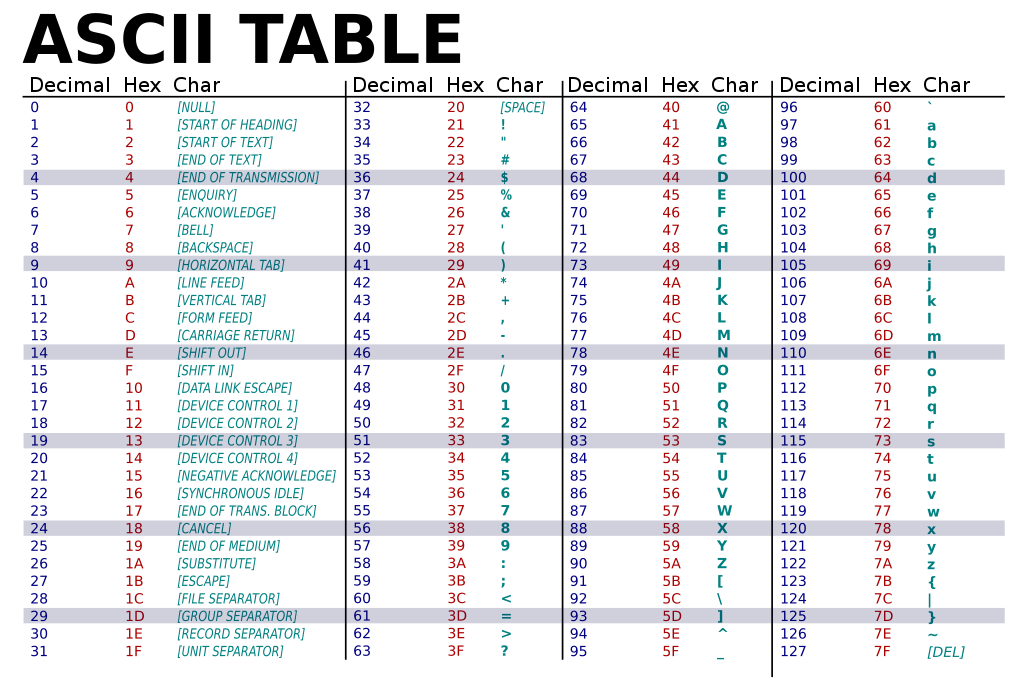
Chúng ta cần làm cho biến modified bằng abcd. Nghe có vẻ đủ dễ, phải không? Đây là payload của chúng ta: 64 "A" để lấp đầy buffer, sau đó "abcd". Nhưng chương trình in ra thông báo rằng chúng ta đã gửi 64-63-62-61, ngược lại với những gì chúng ta dự định.

Tại sao điều đó không hoạt động?
Endianness Là Gì?
Chà các bạn, đã đến lúc nói về endianness. Thuật ngữ này được sử dụng trong công nghệ vào năm 1980 và là tham chiếu đến tiểu thuyết Gulliver's Travels của Jonathan Swift. Trong đó, có một cộng đồng hư cấu gọi là Lilliputians đang chia rẽ gay gắt về việc nên bẻ trứng luộc từ đầu to hay đầu nhỏ.
Câu chuyện Lilliputian là châm biếm (cũng như phần còn lại của tiểu thuyết) và nhằm chế giễu các cuộc chiến thần thánh về những tranh chấp vô nghĩa, điều không bao giờ xảy ra trong công nghệ. :)
Nhưng điều này có liên quan gì đến hacking?
Endianness đề cập đến cách mà một giá trị nhiều byte, như 0x61626364 được lưu trữ trong bộ nhớ. Hoặc 'đầu nhỏ' trước hoặc 'đầu to' trước.Trong trường hợp của chúng ta, vì chúng ta có hệ thống 32-bit, chúng ta có 4 byte trong ví dụ của mình, đại diện cho một số nguyên 32-bit. Trong ví dụ "abcd" của chúng ta, mỗi ký tự bằng một byte về kích thước.
Đối với phần dữ liệu 61-62-63-64 của chúng ta, hệ thống big endian sẽ lưu trữ dữ liệu theo cách con người sẽ đọc nó: 0x61626364. Byte quan trọng nhất (MSB), là 0x61, được lưu trữ trước.
Nhưng little endian có nghĩa là đầu nhỏ được lưu trữ ở địa chỉ cao hơn, vì vậy chúng ta phải lấy 4 byte và hoán đổi thứ tự. 61-62-63-64 trở thành 0x64636261. LSB, hoặc byte ít quan trọng nhất (0x64) được lưu trữ trước.
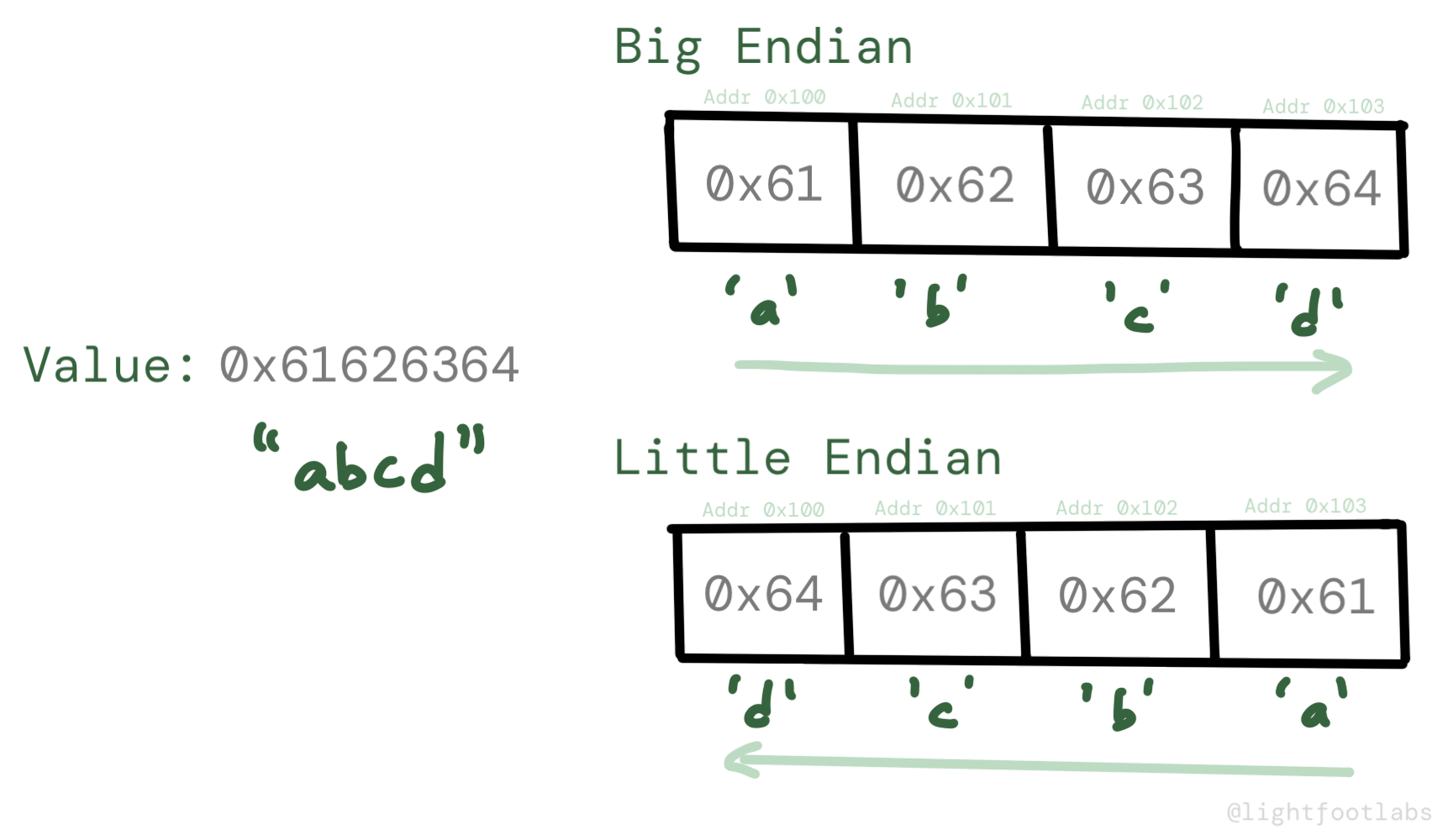
Đó là sự khác biệt từ cách con người biểu diễn dữ liệu đến cách bộ xử lý lưu trữ nó, và tôi nghĩ ban đầu được thực hiện vì lý do hiệu suất. Đó là sự đánh đổi giữa hiệu suất bộ xử lý máy tính và làm phiền các kỹ sư.
Tính Toán Cho Endianness
Nếu chương trình nói chúng ta đã gửi "dbca" khi chúng ta cố gửi "abcd", phải có sự khác biệt về endianness giữa những gì chương trình mong đợi và những gì chúng ta đang gửi.
Bây giờ chúng ta biết vấn đề là gì, hãy thử payload của chúng ta lần nữa. Lần này, chúng ta cần 64 byte hoặc chars của chất độn ("A") và sau đó là giá trị dự định của "abcd", hoán đổi cho endianness: "dcba".
Đây là cách nó lấp đầy buffer:

Đây là ngược lại nếu bạn thích hình dung mọi thứ theo cách ngược lại:

Và đây là chúng ta nhận được một số xác nhận từ chương trình stack1:

Payload của chúng ta là ./stack1 $(python -c "print 'A'*64 + 'dcba'")
Chúng Ta Đã Học Được Gì?
Level này không quá khác so với level trước, nhưng chúng ta đã học thêm một vài ý tưởng:
- Input của chúng ta cần tính đến endianness.
- Tiêu chuẩn ASCII ánh xạ chữ cái, số và các ký hiệu khác thành giá trị số. Có nghĩa là các ký tự ASCII có thể được biểu diễn bằng hexadecimal, như chúng ta đã thấy trong level này.
- Các nhà khoa học máy tính đã thảo luận về các cuộc chiến thần thánh kỹ thuật từ những năm 1980, ít nhất.
Hãy tiếp tục xây dựng trên kiến thức này và tăng khả năng "bof" (buffer overflow) của chúng ta.
Buffer Overflow ("bof") với Return Address Overwrite
Đây là level 4 của Protostar (đúng, chúng ta đã bỏ qua hai level).
Học về endianness thì tuyệt và tất cả, nhưng ai muốn ở trong cùng một hàm mọi lúc?
Level tiếp theo này có một số thay đổi code: trước hết, không còn biến modified để ghi đè. Thứ hai, có một hàm win().
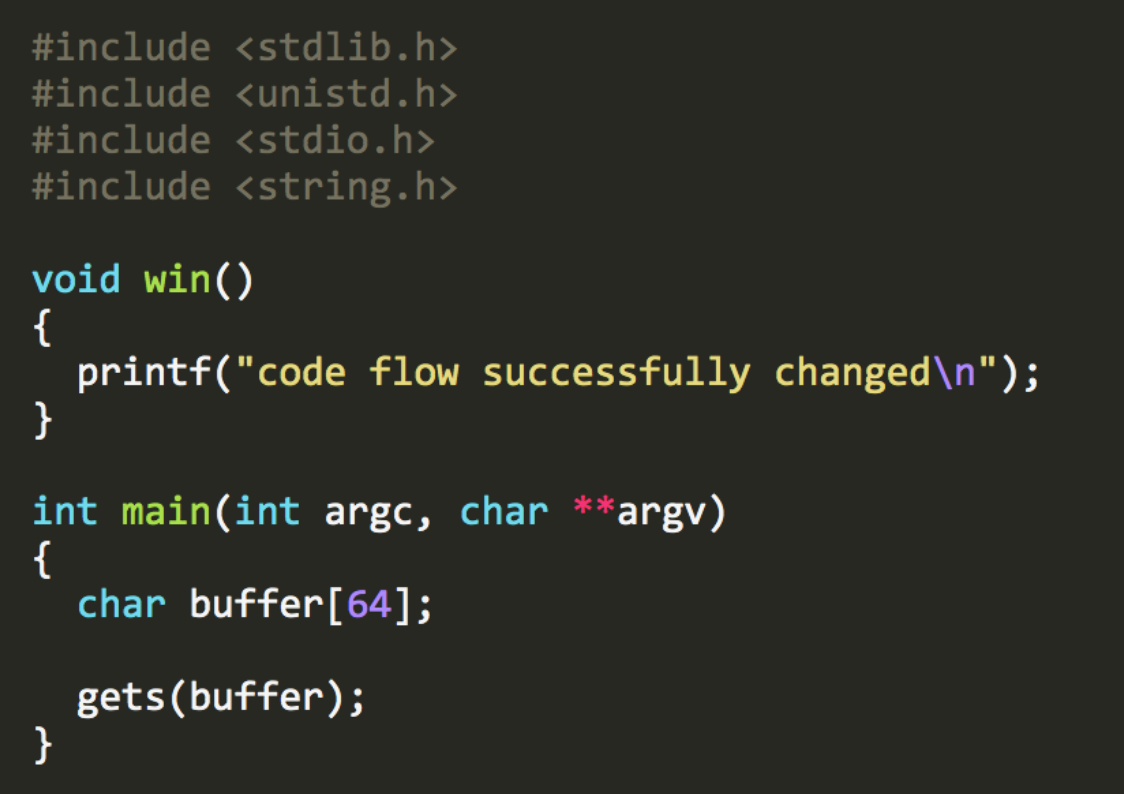
Chúng ta có một mục tiêu luồng điều khiển mới. Chúng ta cần đến hàm win đó… nhưng làm thế nào?
Hãy Thử La Hét Lần Nữa
Hãy thử điều dễ nhất lần nữa, đó là la hét với máy tính với một loạt chữ A. Khi chúng ta thử điều này, chúng ta nhận được segmentation fault và một thông báo hơi kỳ lạ.
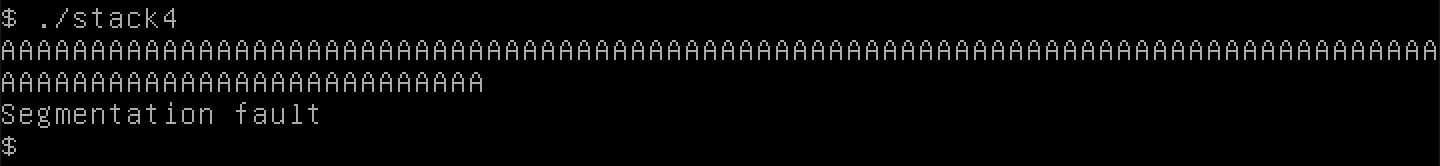
Hãy sử dụng gdb lần nữa. Nếu chúng ta gõ info registers để hiển thị trạng thái của các register tại thời điểm crash, có một số 41 trong đó. Chúng ta biết rằng 0x41 ánh xạ thành chữ "A", đó là việc làm của chúng ta.
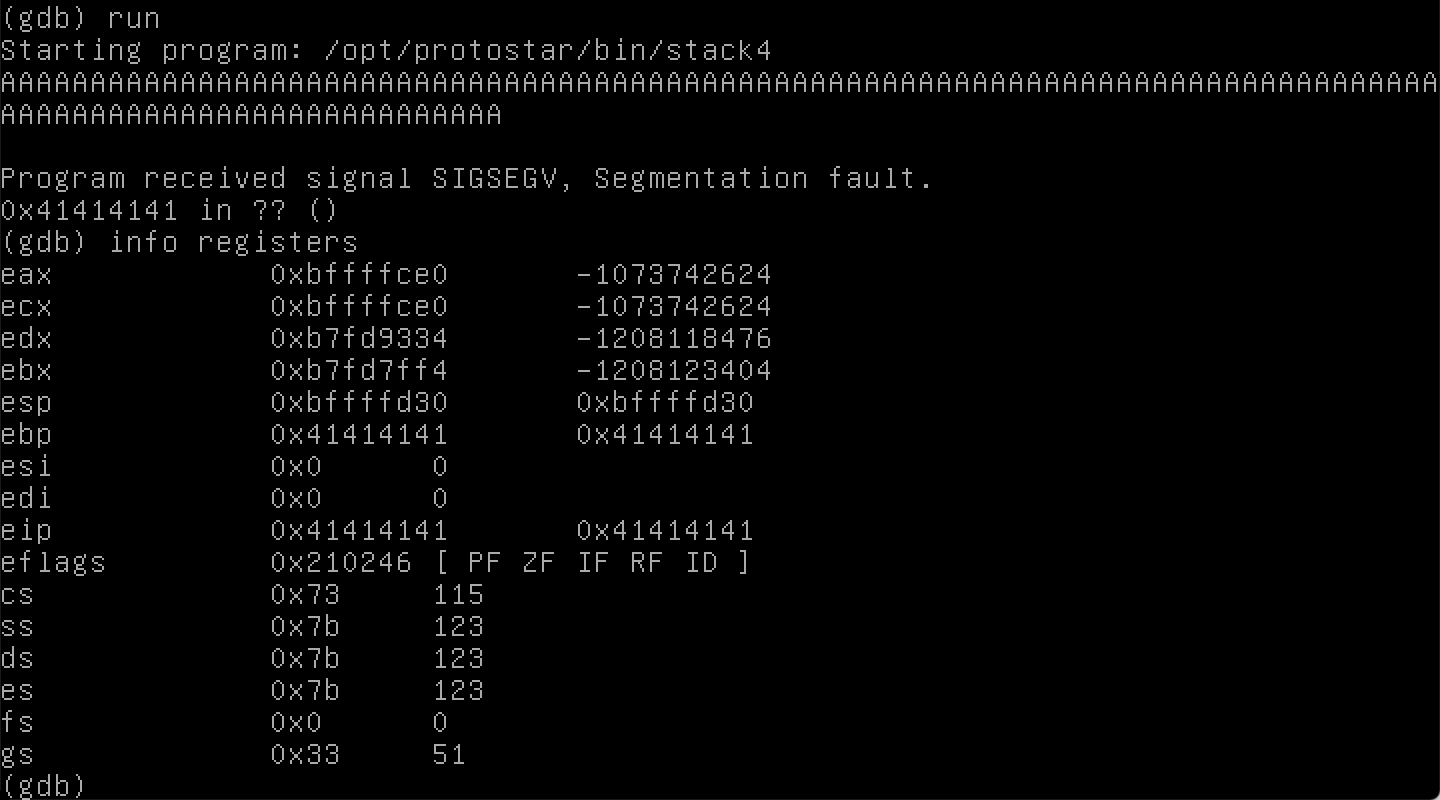
Registers là cách lưu trữ thông tin, ngữ cảnh hiện tại cho trạng thái chương trình, và đánh giá các hoạt động khác nhau. Đó là nhiều hơn những gì tôi muốn đề cập trong bài viết đã-rất-dài này nhưng cuốn sách Hacking: The Art of Exploitation làm rất tốt trong việc giới thiệu một loạt khái niệm, bao gồm registers (ngay cả khi bạn chưa lập trình bằng C trước đây).
Quay lại output gdb của chúng ta: Chúng ta đã ghi đè EIP, là instruction pointer. Instruction pointer theo dõi vị trí của instruction nào sẽ thực thi tiếp theo. Làm điều này bây giờ làm điều này, bây giờ làm điều này, bây giờ làm điều này. Trong level đầu tiên, chúng ta đã thấy code C, và code assembly tương đương của nó. Chúng ta có mov (di chuyển), lea (load effective address), call, v.v.
Nếu chúng ta có thể kiểm soát EIP (và có vẻ như chúng ta có thể!), thì điều đó thực sự tuyệt. Chúng ta có thể nói cho chương trình biết instruction nào sẽ thực thi tiếp theo.
Nhưng chúng ta nên tìm hiểu chính xác cách chúng ta có thể ghi đè instruction pointer từ một biến có vẻ không liên quan (buffer), bởi vì điều đó có vẻ như điều chúng ta không nên làm được.
Điều Gì Xảy Ra Sau main?
Trước khi chúng ta đến hàm main, cái gì đó phải gọi main. Hãy không lo lắng về "cái gì đó" đó là gì bây giờ. Nhưng một khi chúng ta hoàn thành với main, có lẽ chúng ta cần quay lại đó, phải không?
Nhưng làm thế nào chương trình biết nơi nào để đi, và làm thế nào input của chúng ta có bất kỳ quyền kiểm soát nào về điều này?
Để thảo luận thêm về điều này, hãy bắt đầu với một phép ẩn dụ khác:
Bạn đã bao giờ bước vào một căn phòng và sau đó quên lý do tại sao bạn vào đó chưa? Hoặc nhận ra rằng bạn quên mang theo thứ gì đó?
Hoặc có thể bạn nhớ cả hai điều đó, nhưng bạn bị choáng ngợp bởi sự hỗn loạn đang diễn ra trong phòng (nhờ vào trẻ mới biết đi/chó/mèo/sinh vật khác của bạn) đến nỗi nó hoàn toàn ghi đè những gì bạn định làm. Bạn kết thúc làm điều gì đó khác và hoàn toàn lạc hướng.
Điều này có liên quan gì đến chương trình máy tính? Nó giúp chúng ta hiểu cách các lời gọi hàm hoạt động.
Stack Frames
Khi chương trình thực thi từng dòng, nó có một cấu trúc dữ liệu gọi là stack giúp nó duy trì ngữ cảnh, di chuyển thông tin xung quanh và quay lại nơi nó được gọi. Biến buffer được lưu trữ trên stack, cũng như địa chỉ trả về.
Cụ thể, dữ liệu này đang được lưu trữ như một phần của stack frame, là một nhóm cục bộ trong stack ở đây tương ứng với mọi thứ chương trình cần biết để thực thi một hàm nhất định (như main) và sau đó trả về.
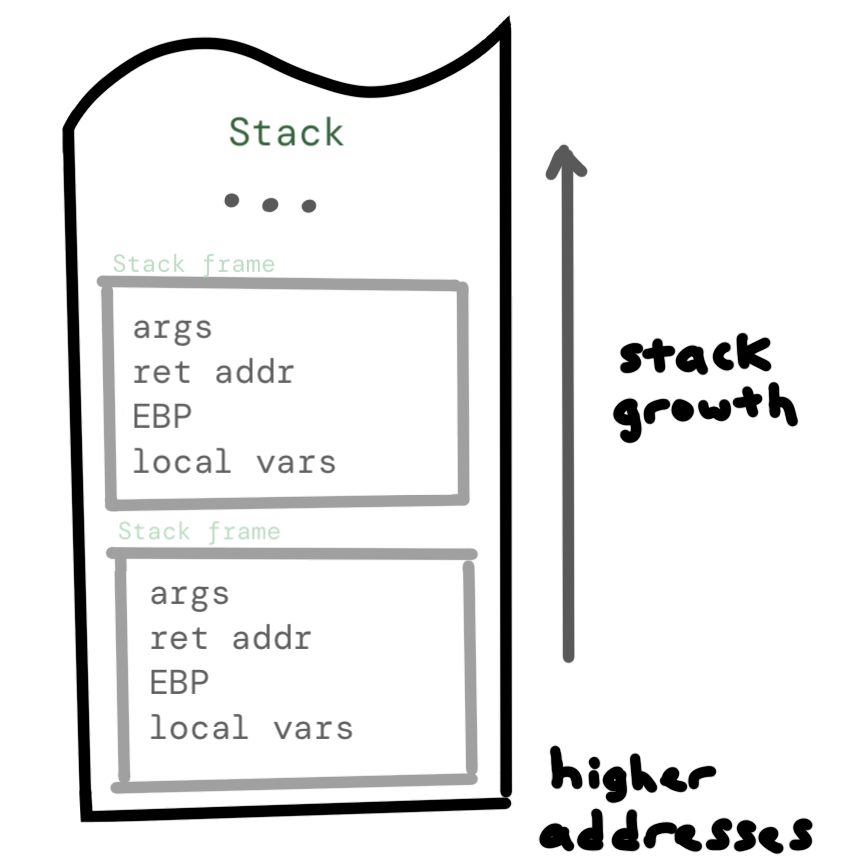
Một stack frame chứa địa chỉ trả về, con trỏ đến frame pointer trước đó, các biến cục bộ và tham số hàm. Mỗi khi chúng ta có một lời gọi hàm khác, chúng ta sẽ có một stack frame khác, lưu trữ ngữ cảnh chúng ta cần cho hàm đó, và phải làm gì khi chúng ta quay lại hàm đã gọi nó. Điều này không khác với não của bạn cố gắng nhớ tại sao bạn vào một căn phòng nhất định, và sau đó nhớ nơi nào để đi sau khi bạn đã đạt được nhiệm vụ của mình ở đó.
Quay lại chương trình của chúng ta: chúng ta sẽ ret (trả về) từ cuối main quay lại phần code nào đã gọi hàm này. Nói cách khác, EIP sẽ trỏ đến instruction ret.
Cùng lúc đó, stack pointer, theo dõi dữ liệu liên quan trên stack (để sử dụng trong các instruction assembly, v.v.), sẽ trỏ đến địa chỉ trả về của 0xb7eadc76.
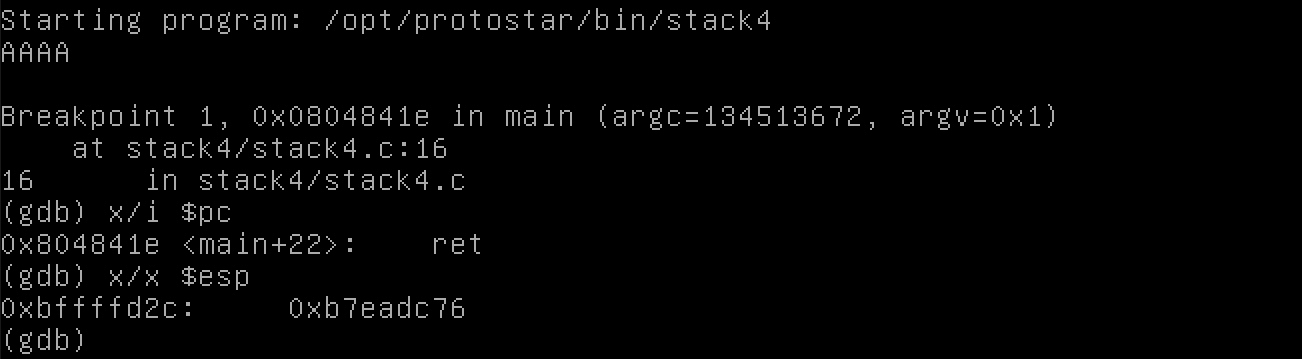
Hoặc ít nhất, đó là những gì được cho là xảy ra.
Chúng ta đã có thể lấp đầy biến buffer, và sau đó tiếp tục viết cho đến khi chúng ta tràn qua frame pointer trước đó (EBP) và cũng ghi đè địa chỉ trả về.
Chúng ta đã ghi đè nó với một loạt chữ A, dẫn đến địa chỉ trả về không hợp lệ là 0x41414141. Bởi vì địa chỉ đó không tồn tại, chương trình không thể hoàn thành việc thực thi, dẫn đến segmentation fault mà chúng ta đã thấy trước đó.
Mở Rộng Hình Ảnh "bof" Của Chúng Ta
Tôi có một lời thú nhận: các sơ đồ mà tôi đã chia sẻ cho đến nay (nơi biến buffer tràn vào modified) không hoàn chỉnh. Một phần của sơ đồ đã bị cắt bỏ, vì mục đích đơn giản hóa.
Bây giờ chúng ta biết về stack frames và nhu cầu về địa chỉ trả về, chúng ta có thể bao gồm điều đó trong sơ đồ của mình:
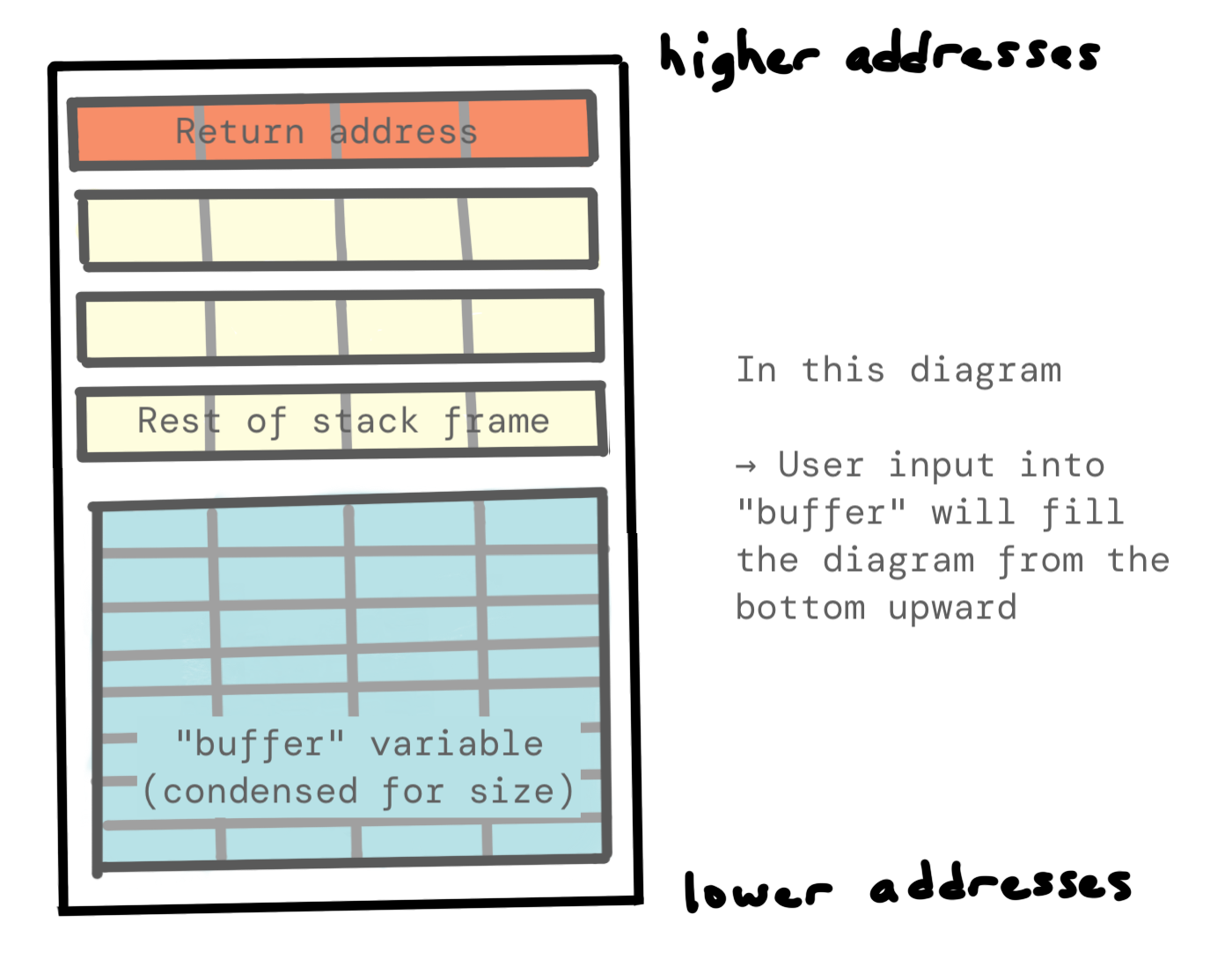
Hoặc nếu bạn thích cách nhìn ngược lại:
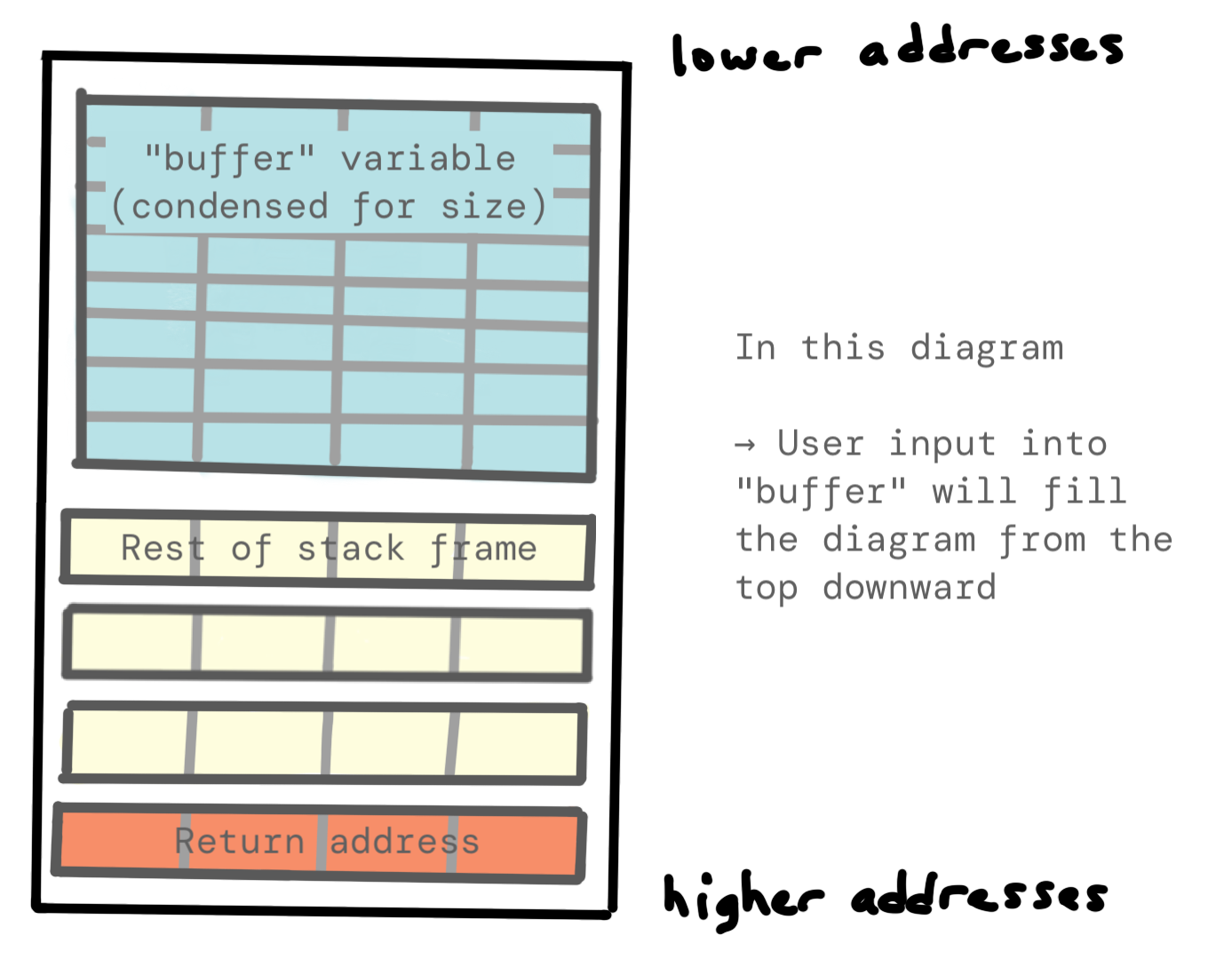
Không gian bổ sung này giữa buffer và địa chỉ trả về lưu trữ các biến khác như frame pointer trước đó. Chúng ta sẽ cần tràn cả điều này, có nghĩa là chúng ta cần biết kích thước của nó. Bạn có thể xác định điều này theo nhiều cách khác nhau. Bạn có thể sử dụng phân tích tĩnh (xem assembly) hoặc phân tích động, có nghĩa là thử mọi thứ và sử dụng info registers trong gdb (hoặc tương tự) để xem payload của bạn đã lấp đầy mỗi register liên quan như thế nào.
Để hướng dẫn này không dài hơn nữa, tôi sẽ nói với bạn rằng chúng ta cần 12 byte chất độn bổ sung, sau khi chúng ta đã lấp đầy buffer.
Trong các level trước đó, chúng ta đang kiểm soát luồng code bằng cách kiểm soát các biến. Bằng cách tràn biến buffer, chúng ta có thể ghi đè các biến cục bộ khác. Điều này giống như bước vào một căn phòng và sự hỗn loạn (hoặc vấn đề bộ nhớ ;)) ghi đè kế hoạch của bạn về những gì bạn định làm trong phòng đó.
Ở đây, chúng ta sẽ nâng cấp khả năng của mình và kiểm soát instruction pointer, EIP, để đi đến một vị trí khác trong code. Điều này giống như bước vào một căn phòng nơi có quá nhiều hỗn loạn từ trẻ em/thú cưng đến nỗi nó ghi đè kế hoạch của não bạn để ret quay lại một căn phòng khác. Thay vào đó, bạn kết thúc chạy đến đồ vệ sinh, hoặc tủ lạnh. Đó không phải là phép ẩn dụ hoàn hảo, nhưng hy vọng nó giúp ích.
Hãy kết thúc level cuối cùng của chúng ta cho hướng dẫn này. Chúng ta có cùng kích thước buffer như trước (64 chars), sau đó 12 byte chất độn bổ sung để lấp đầy phần còn lại của stack frame, và sau đó là địa chỉ trả về mới của chúng ta.
Chúng Ta Muốn Đi Đâu?
Hàm win, rõ ràng. Nhưng nó ở đâu?
Chúng ta có thể sử dụng gdb (hoặc một công cụ software RE khác như Binary Ninja, Ghidra, v.v.) để tìm địa chỉ.
Mở file trong gdb bằng cách gõ gdb stack4. Sau đó xem hàm win bằng cách gõ disas win hoặc disassemble win.
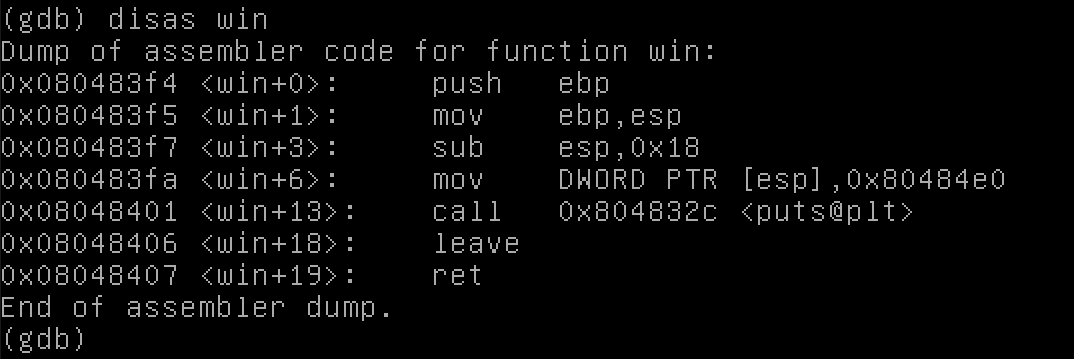
Điều này cho chúng ta thấy các instruction assembly cho hàm win, cũng như địa chỉ trong bộ nhớ cho mỗi cái.
Hàm bắt đầu tại 0x080483f4. Đó là nơi chúng ta muốn đến.
Kết Hợp Tất Cả Lại
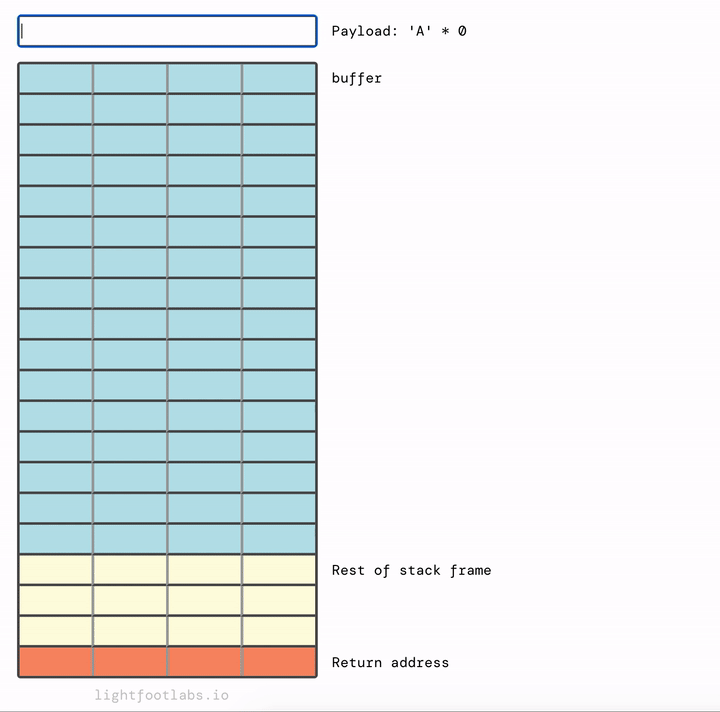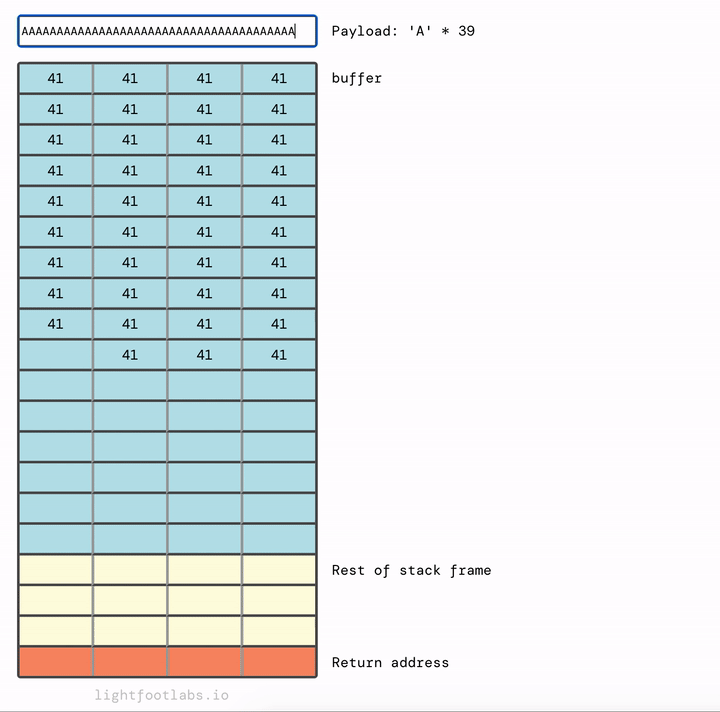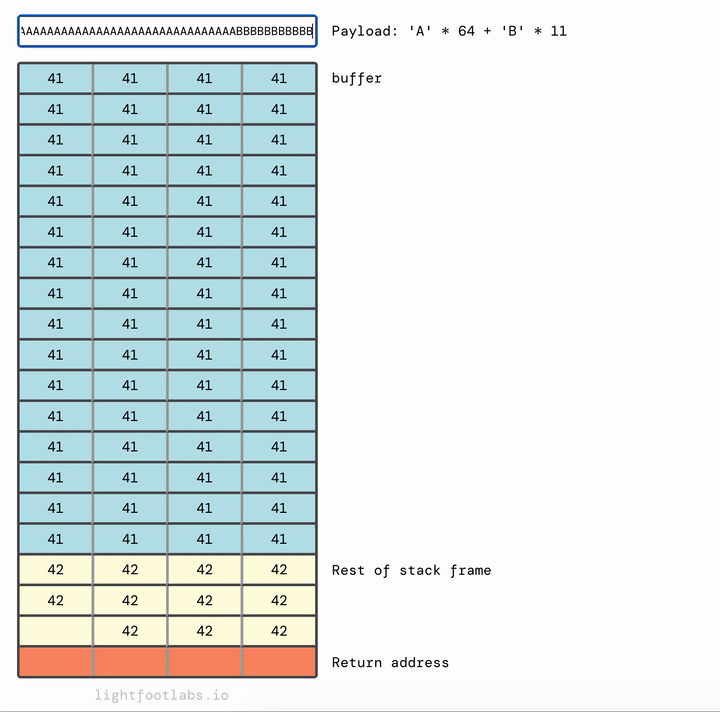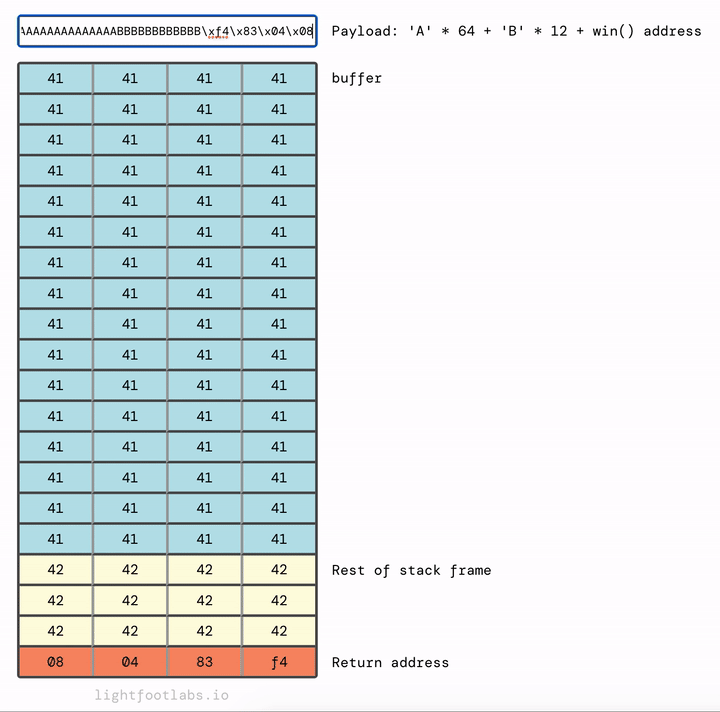
Được rồi. 64 byte chất độn cho buffer, thêm 12 byte chất độn cho stack frame, sau đó là địa chỉ của win.
'A'*64 + 'B'*12 + <win address>
Bạn có quên endianness không? Tôi hy vọng là không.
Địa chỉ win của chúng ta là 0x080483f4 cần được hoán đổi cho endianness thành 0xf4830408.
Nếu bạn đang sử dụng một công cụ như Python để nhập payload, bạn sẽ cần mã hóa các byte địa chỉ win, vì bây giờ chúng ta đang làm việc với các ký tự không thể đọc được ASCII. Để làm như vậy, bạn thêm \x trước mỗi byte:
'A'*64 + 'B'*12 + '\xf4\x83\x04\x08'
Để nhập điều đó vào chương trình, bạn có thể sử dụng dòng sau, in ra payload và pipe nó vào chương trình stack4:
python -c "print('A'*64 + 'B'*12 + '\xf4\x83\x04\x08')" | ./stack4
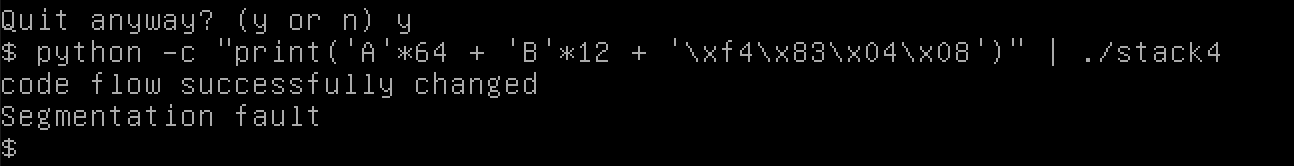
Hoặc bạn có thể sử dụng framework như pwntools để bạn không phải thực hiện thay đổi endianness bằng tay:
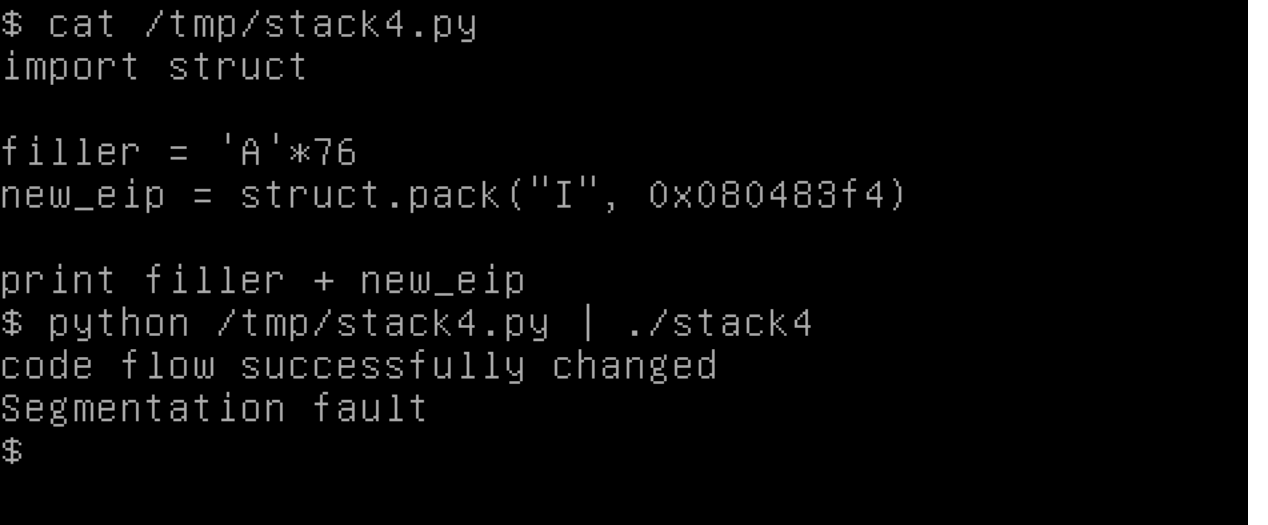
Đây là exploit của chúng ta trông như thế nào, dạng hoạt ảnh:
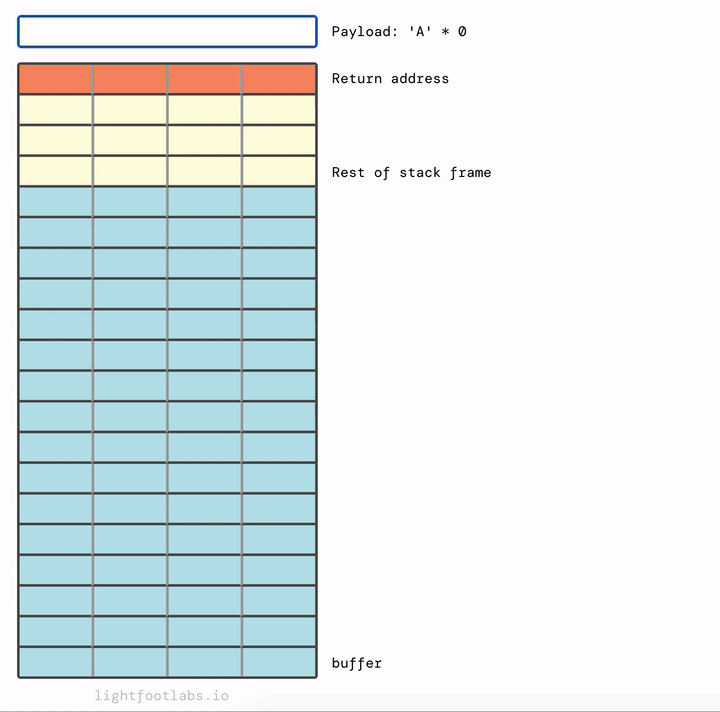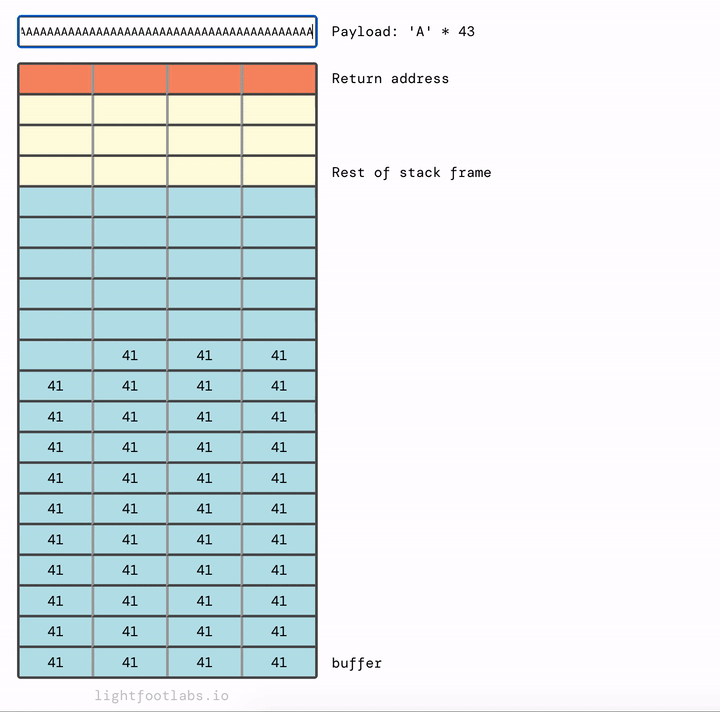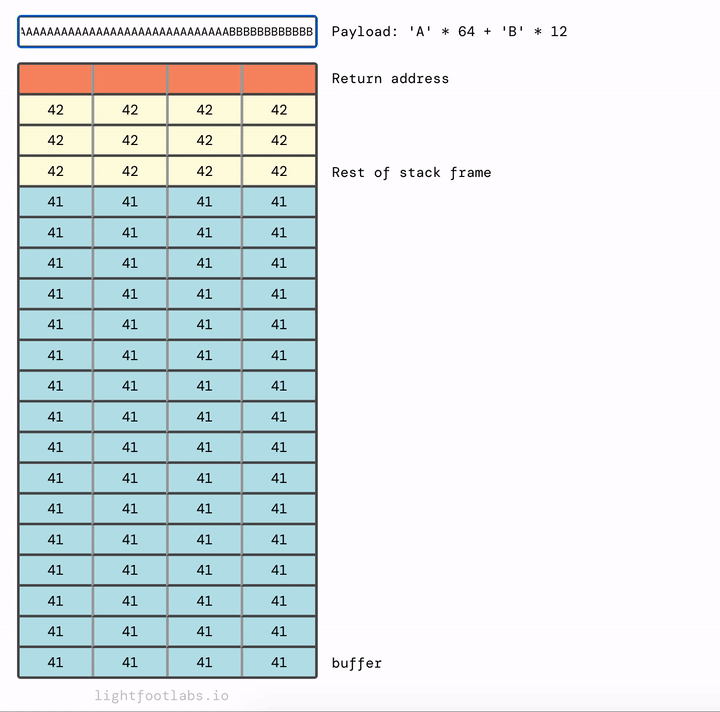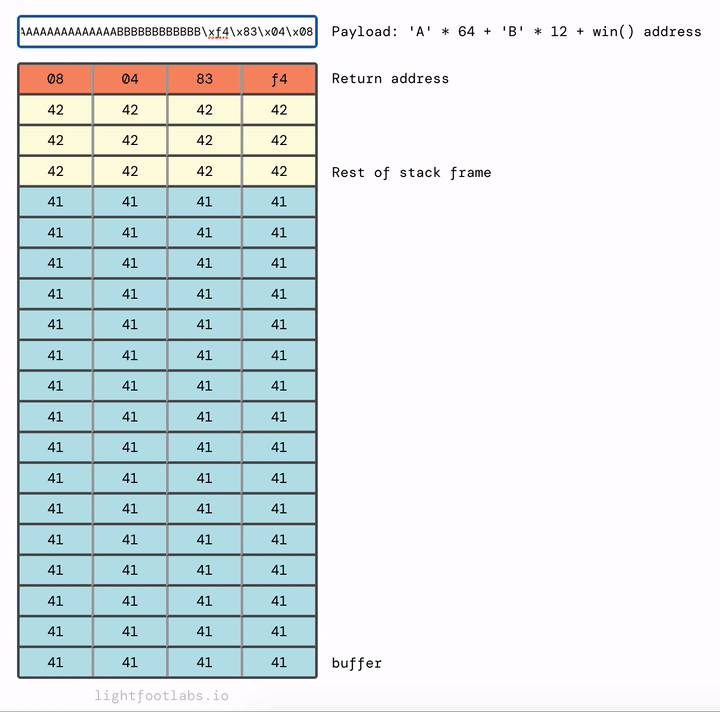
Và như mọi khi, đây là cách nhìn với hướng ngược lại:
Chúng Ta Đã Học Được Gì?
Hãy kết thúc điều này với một số điều rút ra nữa:
- Tất cả code có thể được thực thi đều có vị trí có thể định địa chỉ, và vì chúng ta có thể ghi đè EIP, chúng ta có thể kiểm soát luồng code để đi bất cứ nơi nào chúng ta muốn trong bộ nhớ.
- Các hàm chiếm một vị trí trong bộ nhớ được chỉ định bởi một địa chỉ. Và trong trường hợp của chúng ta, những địa chỉ đó không thay đổi với mỗi lần chạy (không có ASLR).
- Khi chúng ta muốn sử dụng một trong những vị trí có thể định địa chỉ này, chúng ta cần ghi nhớ endianness.
- Chúng ta đã học thêm một chút về stack và stack frames. BaseCS là một series tuyệt vời để tìm hiểu thêm.
- Chúng ta đã thấy cách mã hóa các ký tự không phải ASCII trong lệnh Python của chúng ta, và một chút pwntools để script payload của chúng ta.
Bạn có thể thấy những ý tưởng này xây dựng trên chính chúng. Đầu tiên chúng ta cần học về bit, sau đó hex, sau đó ASCII, sau đó endianness, sau đó stack frames.
Như bạn có thể tưởng tượng, không phải tất cả các thử thách CTFs (và chắc chắn không phải phần mềm 'thế giới thực') đều chứa các vấn đề rõ ràng như vậy hoặc các hàm win() (theo nghĩa đen). Nhưng chúng ta đang đến đó, từng bit một.
Còn Tiếp…
Nếu bạn đã đọc hết, bạn giờ có thể làm một thử thách CTF "bof" (buffer overflow) cơ bản và hiểu điều gì đang xảy ra. Woo!
Trong bài nói chuyện gốc của tôi, tôi cũng đã đề cập đến nhiều level hơn, liên quan đến những thứ như: shellcoding, nop sleds, reverse shells, ret2libc, và những thứ vui khác như pwntools và libc memes.
Tuy nhiên, bài viết này đã rất dài. Vì vậy nếu bạn thích đọc điều này và muốn tôi mở rộng series, vui lòng chia sẻ hướng dẫn này và/hoặc cho tôi biết suy nghĩ của bạn!
Chúc các bạn Buffer tràn bờ đê vui vẻ!
Tham khảo
Bài viết gốc: Buffer Overflows Through Visuals - Lightfoot Labs