RAGAS Tutorial: Tại sao 'Em cảm thấy nó thông minh hơn' không phải là metric?
Sếp hỏi 'Nó có tốt hơn bản cũ không?' - bạn cần số liệu, không phải vibes. Đánh giá RAG với Dynamic Ground Truth và RAGAS framework.
RAGAS Tutorial: Đánh giá RAG System với Dynamic Ground Truth
Bài 6/6 (cuối) trong series "Làm chủ GraphRAG" - Phân tích chuyên sâu dựa trên cuốn Essential GraphRAG của Tomaž Bratanič và Oskar Hane
TL;DR
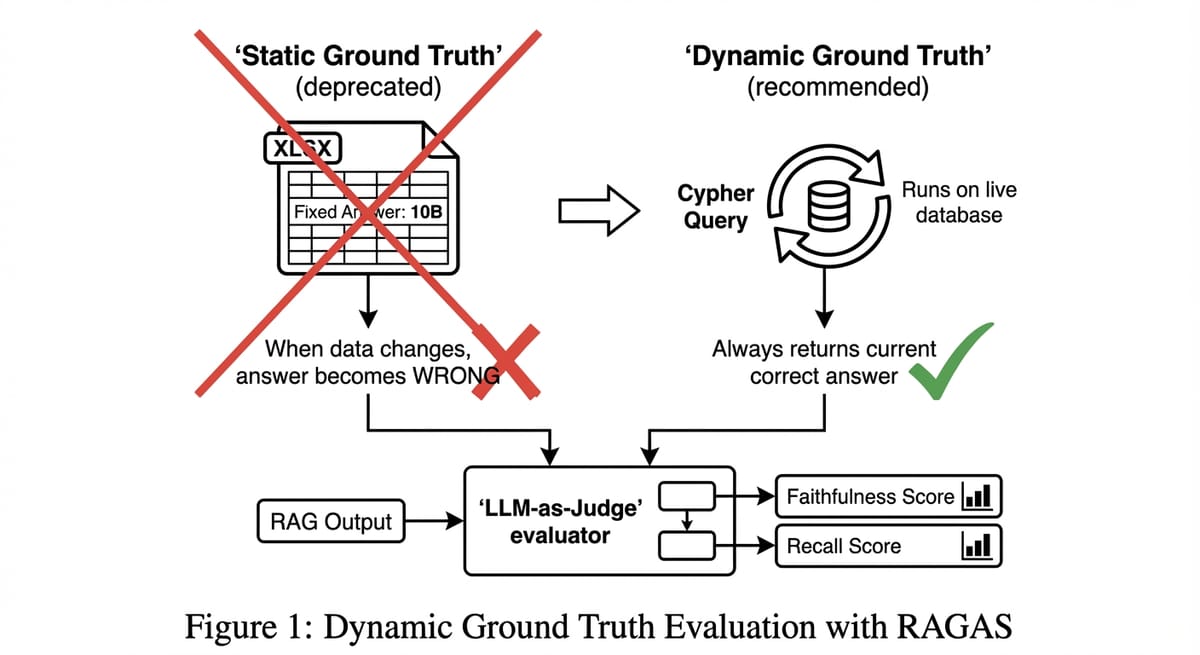
- Vấn đề: Đánh giá bằng cảm tính (Vibes) không đáng tin cậy. Dữ liệu thay đổi liên tục làm hỏng bộ test tĩnh (Static Ground Truth).
- Giải pháp: Dynamic Ground Truth sử dụng câu truy vấn Cypher làm đáp án chuẩn.
- Công cụ: RAGAS (LLM-as-a-Judge) để chấm điểm Faithfulness, Recall.
- Kinh tế: Đầu tư vào CI/CD cho AI giúp phát hiện lỗi sớm, tránh thảm họa PR khi AI nói bậy trên production.
Series roadmap: Bài 1: Tại sao cần Graph → Bài 2: Text2Cypher → Bài 3: Agentic RAG → Bài 4: Microsoft GraphRAG → Bài 5: ETL → Bài 6 (Evaluation)
Chúng ta đã đi đến cuối hành trình. Qua 5 bài trước, bạn đã hiểu tại sao cần Graph, cách biến câu hỏi thành Cypher, kiến trúc Agentic RAG, kỹ thuật Microsoft GraphRAG, và quy trình ETL để xây dựng đồ thị sạch.
Bạn đã xây xong hệ thống GraphRAG. Nó chạy rồi. Nhưng sếp hỏi: "Nó có tốt hơn bản cũ không?". Bạn không thể trả lời "Em cảm thấy nó thông minh hơn". Bạn cần số liệu.
Phần 1: Cái chết của Static Ground Truth (Đáp án tĩnh)
Cách truyền thống: File Excel (Câu hỏi - Đáp án). * Q: "Doanh thu tháng này?" * A: "10 tỷ."
Ngày mai doanh thu lên 10.5 tỷ. AI trả lời "10.5 tỷ" (Đúng). File Excel vẫn là "10 tỷ". -> AI bị chấm sai.
Bạn mất cả đời để đi sửa file Excel.
Phần 2: Sự đột phá - Dynamic Ground Truth với Cypher
Giải pháp thiên tài của cuốn sách: Lưu đáp án là Câu truy vấn (Query).

Nhờ đó, bộ test luôn "tươi" cùng dữ liệu.
Phần 3: RAGAS Metrics
Dựa trên paper "RAGAS: Automated Evaluation of Retrieval Augmented Generation" (Es et al., 2023). Đây là framework được sử dụng rộng rãi nhất hiện nay cho RAG evaluation, với hơn 10,000 stars trên GitHub.
Thay vì dùng String Matching (so khớp chuỗi cứng), RAGAS sử dụng LLM-as-a-Judge để chấm điểm ngữ nghĩa:
- Faithfulness: $P(Answer | Context)$. AI có trung thực với dữ liệu tìm được không? Metric này phát hiện hallucination - khi AI "bịa" thông tin không có trong context.
- Context Recall: $P(GroundTruth | Context)$. Hệ thống retrieval có tìm đủ thông tin không? Nếu ground truth là "Tom Hanks đóng 95 phim" mà context chỉ chứa 50 phim, recall sẽ thấp.
- Answer Correctness: Kết hợp Semantic Similarity (cosine của embeddings) và Factual Overlap (F1 score của facts) giữa AI Answer và Golden Answer.
Ngoài ra, RAGAS còn cung cấp các metrics khác như Context Precision (có bao nhiêu context được sử dụng?) và Answer Relevancy (câu trả lời có đúng trọng tâm câu hỏi không?).
Phần 4: Góc độ Kinh tế (Business Value)
Tại sao phải tốn tiền chạy Evaluation hàng ngày? * Chi phí ẩn của lỗi: Một câu trả lời sai về chính sách giá có thể làm mất khách hàng, hoặc gây kiện tụng. * Regression Testing: Khi bạn update prompt, bạn có chắc là không làm hỏng các tính năng cũ không? Chỉ có Evaluation Pipeline mới trả lời được.
Lời kết cho cả Series
Chúng ta đã đi qua 6 bài viết, từ việc hiểu tại sao Vector Search không đủ, đến các kỹ thuật cụ thể như Text2Cypher, Agentic RAG, Microsoft GraphRAG, ETL, và cuối cùng là Evaluation.
GraphRAG là sự kết hợp giữa tư duy cấu trúc (Graph) và tư duy xác suất (Vector). Nó phức tạp, tốn kém, nhưng mạnh mẽ. Key takeaways:
- Không có Silver Bullet: Vector, Graph, Agentic - mỗi cách tiếp cận có trade-off riêng. Hiểu rõ use case để chọn đúng tool.
- Data Quality là King: Dù dùng thuật toán nào, đồ thị rác sẽ cho kết quả rác. Đầu tư vào ETL.
- Measure Everything: Đừng tin vào cảm tính. Xây dựng evaluation pipeline từ ngày đầu.
Hy vọng series này đã cung cấp cho bạn đủ vũ khí (kiến thức và tư duy) để chinh phục đỉnh cao này. Chúc các bạn thành công!
Tài liệu tham khảo & Đọc thêm (Further Reading)
Để đi sâu hơn vào các chủ đề đã thảo luận, tôi khuyên bạn nên đọc các tài liệu nghiên cứu gốc và sách chuyên khảo sau đây:
1. Nghiên cứu mới nhất (State-of-the-Art Papers)
- LightRAG: Simple and Fast Retrieval-Augmented Generation (2024)
- Tại sao nên đọc: Đây là một hướng tiếp cận mới (từ HKUDS) giúp tối ưu hóa GraphRAG, làm cho nó nhẹ hơn và nhanh hơn so với phiên bản của Microsoft. Nó giải quyết bài toán chi phí indexing khổng lồ mà chúng ta đã bàn ở Bài 4.
- Link: arXiv:2410.05779
- Github: HKUDS/LightRAG
- From Local to Global: A Graph RAG Approach to Query-Focused Summarization (Microsoft, 2024)
- Tại sao nên đọc: Paper gốc mô tả thuật toán Map-Reduce trên đồ thị cộng đồng. Nền tảng của Bài 4.
- Link: arXiv:2404.16130
- RAGAS: Automated Evaluation of Retrieval Augmented Generation (2023)
- Tại sao nên đọc: Hiểu sâu về toán học đằng sau các chỉ số Faithfulness và Context Recall. Nền tảng của Bài 6.
- Link: arXiv:2309.15217
2. Sách chuyên khảo (Books)
- Mastering Retrieval-Augmented Generation Workflows with GraphRAG (2025)
- Tác giả: Tyrell Owen
- Nội dung: Cuốn sách thực chiến mới nhất tập trung vào việc xây dựng pipeline GraphRAG end-to-end.
- The LLM Engineering Handbook (2025)
- Tác giả: Paul Iusztin & Maxime Labonne
- Nội dung: Không chỉ nói về RAG, cuốn sách này bao phủ toàn bộ vòng đời phát triển LLM (Engineering Lifecycle), từ Finetuning đến Evaluation và Deployment.
3. Cộng đồng & Mã nguồn
- LangChain & LlamaIndex: Hai thư viện này cập nhật tính năng GraphRAG rất nhanh. Hãy theo dõi blog kỹ thuật của họ.
- Neo4j Developer Blog: Nơi tốt nhất để học các kỹ thuật Cypher nâng cao và tối ưu hóa hiệu năng Database.