Knowledge Graph ETL: Tại sao 'Garbage In, Garbage Out' giết chết GraphRAG?
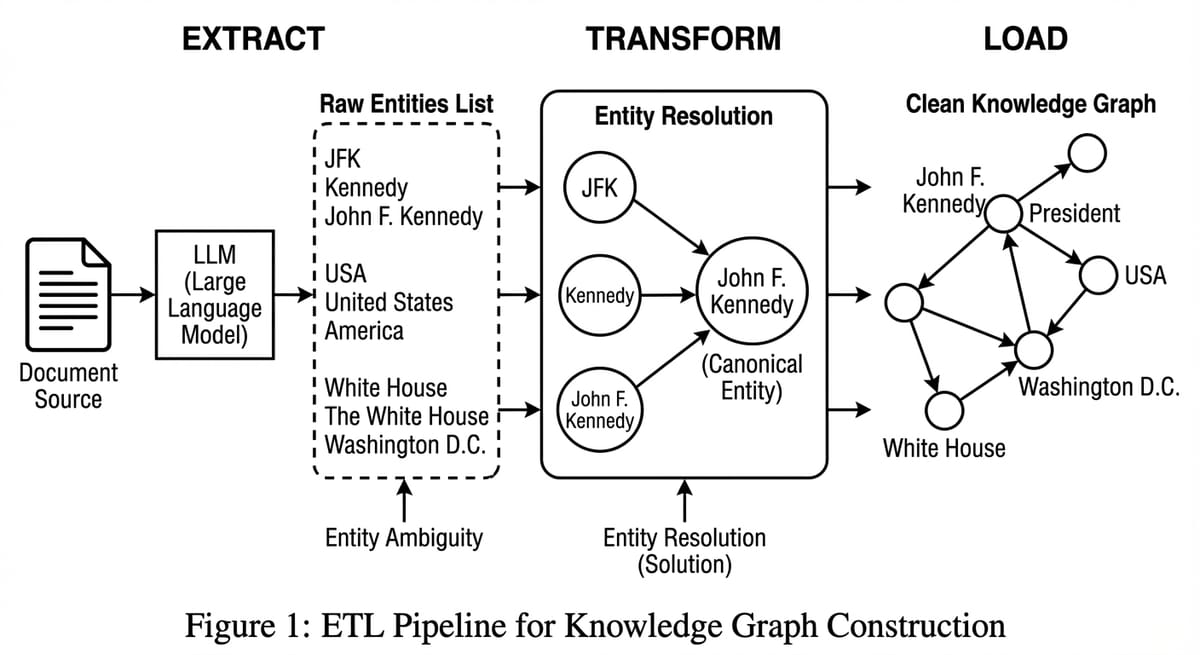
JFK, Kennedy, John F. Kennedy - tại sao máy tính thấy 3 người khác nhau? Xây dựng Đồ thị Tri thức sạch từ dữ liệu thô với Entity Resolution.
Knowledge Graph ETL: Xây dựng Đồ thị Tri thức sạch từ dữ liệu thô
Bài 5/6 trong series "Làm chủ GraphRAG" - Phân tích chuyên sâu dựa trên cuốn Essential GraphRAG của Tomaž Bratanič và Oskar Hane
TL;DR
- Vấn đề: Dữ liệu thô (PDF, Text) hỗn độn, chứa nhiều thực thể trùng lặp (JFK, Kennedy, John F. Kennedy).
- Giải pháp: Quy trình ETL với trọng tâm là Entity Resolution.
- Kỹ thuật: Sử dụng Closed Schema (định nghĩa trước) và Structured Outputs (JSON mode) của LLM.
- Kinh tế: Đầu tư vào ETL giúp giảm chi phí token khi truy vấn (do đồ thị sạch, ít nhiễu) và tăng độ chính xác dài hạn.
Series roadmap: Bài 1: Tại sao cần Graph → Bài 2: Text2Cypher → Bài 3: Agentic RAG → Bài 4: Microsoft GraphRAG → Bài 5 (ETL) → Bài 6: Evaluation
Ở bài trước, tôi đã nhấn mạnh rằng dù bạn chọn Microsoft GraphRAG hay bất kỳ phương pháp nào khác, chất lượng của Knowledge Graph đầu vào là yếu tố quyết định. Thuật toán chỉ là ngọn, dữ liệu là gốc. "Garbage In, Garbage Out". Nếu bạn ném rác vào Neo4j, bạn sẽ nhận lại rác từ GraphRAG.
Chương 6 của cuốn sách đưa chúng ta trở lại mặt đất với bài toán ETL (Extract, Transform, Load) - công việc "công nhân vệ sinh" mà không ai muốn làm nhưng ai cũng cần.
Phần 1: Thách thức Entity Resolution - Con người hay Máy móc?
Vấn đề lớn nhất là Sự nhập nhằng (Ambiguity).
Máy tính thấy "J.F. Kennedy" và "JFK" là 2 chuỗi khác nhau -> tạo 2 node khác nhau.
Hậu quả: Đồ thị bị phân mảnh (Fragmented). Thông tin về ông Kennedy bị xé lẻ.
Entity Resolution Algorithms
Đây là bài toán cổ điển trong Data Management, được nghiên cứu từ những năm 1950 với các tên gọi khác nhau: Record Linkage, Deduplication, Entity Matching. Survey toàn diện nhất về chủ đề này là "An Overview of End-to-End Entity Resolution" (Christophides et al., 2020).
Các phương pháp truyền thống dùng Blocking & Matching:
- Blocking: Nhóm các entity có khả năng trùng lặp vào cùng "block" để giảm số phép so sánh (ví dụ: nhóm theo chữ cái đầu của tên).
- Matching: So khớp chuỗi bằng các thuật toán như Jaro-Winkler, Levenshtein, hoặc TF-IDF cosine similarity.
Trong kỷ nguyên GenAI, chúng ta có thể dùng LLM để làm cả hai bước này thông minh hơn - đặc biệt khi cần reasoning về context (ví dụ: "JFK" trong bài về lịch sử là tổng thống, nhưng trong bài về du lịch là sân bay).

Phần 2: OpenIE vs. Closed Schema - Sự lựa chọn chiến lược
Khi trích xuất entities và relationships từ text, bạn có hai cách tiếp cận:
OpenIE (Open Information Extraction): "Thấy gì lấy nấy"
Với OpenIE, bạn để LLM tự do trích xuất bất kỳ entity và relationship nào nó "thấy" trong text. Nghe có vẻ linh hoạt, nhưng hệ quả là đồ thị rác. Quan hệ lung tung (:YEU_THICH, :THICH, :LOVE, :LIKE - tất cả đều có nghĩa giống nhau nhưng được lưu thành 4 loại khác nhau). Khi truy vấn "Ai thích gì?", bạn phải nhớ tất cả các biến thể này.
Các hệ thống OpenIE nổi tiếng như OpenIE 5.0 hay ReVerb đã chứng minh điều này qua hàng chục năm nghiên cứu.
Closed Schema (Schema Đóng): "Kỷ luật là sức mạnh"
Với Closed Schema, bạn định nghĩa trước danh sách cố định:
- Entity types: Person, Organization, Location, Product
- Relationship types: WORKS_FOR, LOCATED_IN, MANUFACTURES
LLM được yêu cầu chỉ trích xuất những gì thuộc schema này. Hệ quả: Đồ thị sạch, nhất quán, dễ truy vấn.
Lời khuyên: Luôn dùng Closed Schema cho Production. OpenIE chỉ phù hợp cho giai đoạn exploration ban đầu.
Phần 3: Góc độ Kinh tế (Business Value) - Build vs. Buy
Bạn có nên tự xây pipeline ETL này không? Hãy cân nhắc các yếu tố sau:
Chi phí LLM cho Entity Extraction
Dùng GPT-4 để trích xuất entities từ 1000 tài liệu (mỗi tài liệu ~2000 tokens):
- Input: 2M tokens x $10/1M = $20
- Output: ~500K tokens x $30/1M = $15
- Tổng: ~$35 cho extraction cơ bản
Nghe có vẻ rẻ, nhưng nếu bạn cần chạy Entity Resolution (so sánh từng cặp entity), chi phí sẽ tăng theo cấp số nhân.
Chiến lược tối ưu chi phí
- Hybrid Extraction: Dùng các model nhỏ chuyên biệt như GLiNER hoặc SpaCy NER để trích xuất Entity (miễn phí, chạy local). Chỉ dùng GPT-4 cho bước Reasoning (xác định quan hệ phức tạp hoặc disambiguate entities).
- Document Processing Services: Dùng Unstructured.io hoặc LlamaParse để xử lý PDF/DOCX thành text sạch trước khi đưa vào LLM.
- Batch Processing: Nhóm nhiều đoạn text vào cùng một prompt để giảm overhead.
Quy tắc vàng
Đầu tư vào ETL chất lượng sẽ giúp:
- Giảm chi phí truy vấn dài hạn: Đồ thị sạch = ít node/edge hơn = query nhanh hơn = ít token hơn khi serialize context cho LLM.
- Tăng độ chính xác: Entity Resolution tốt = không bị miss information do fragmentation.
Kết luận
ETL là công việc "công nhân vệ sinh", vất vả nhưng quan trọng nhất. Một đồ thị sạch sẽ là tài sản tích lũy giá trị theo thời gian. Đừng cố chạy tắt bước này - bạn sẽ phải trả giá gấp nhiều lần khi debug các câu trả lời sai của GraphRAG.
Nhưng làm sao để biết hệ thống GraphRAG của bạn có hoạt động tốt không? Bạn không thể chỉ dựa vào cảm tính "thấy có vẻ đúng". Bạn cần Evaluation.
Tiếp theo trong series: Bài 6: Evaluation - Đánh giá khoa học hệ thống RAG với RAGAS và Dynamic Ground Truth.