Microsoft GraphRAG Deep Dive: Tại sao RAG thường thất bại với Global Questions?
RAG truyền thống không trả lời được 'Chủ đề chính của dataset là gì?'. Microsoft GraphRAG giải quyết bằng Community Detection và Map-Reduce.
Microsoft GraphRAG Deep Dive: Tại sao RAG thường thất bại với Global Questions?
Bài 4/6 trong series "Làm chủ GraphRAG" - Phân tích chuyên sâu dựa trên cuốn Essential GraphRAG của Tomaž Bratanič và Oskar Hane
TL;DR
- Vấn đề: RAG truyền thống thất bại với "Global Questions" (Câu hỏi toàn cục, ví dụ: "Chủ đề chính của tập dữ liệu này là gì?").
- Giải pháp: Microsoft GraphRAG sử dụng thuật toán phát hiện cộng đồng (Community Detection) để tóm tắt dữ liệu theo tầng.
- Cơ chế: Map-Reduce trên đồ thị. Gom nhóm node -> Tóm tắt nhóm -> Tổng hợp tóm tắt.
- Kinh tế: Chi phí Indexing cực cao (gọi LLM hàng nghìn lần), nhưng mang lại khả năng "Sense-making" (Tạo nghĩa) mà không phương pháp nào khác làm được.
Series roadmap: Bài 1: Tại sao cần Graph → Bài 2: Text2Cypher → Bài 3: Agentic RAG → Bài 4 (Microsoft GraphRAG) → Bài 5: ETL → Bài 6: Evaluation
Ở bài trước, tôi đã đề cập rằng Agentic RAG vẫn có điểm yếu với câu hỏi toàn cục. Nếu bạn theo dõi tin tức về AI, chắc hẳn bạn đã nghe đến cái tên Microsoft GraphRAG - giải pháp của Microsoft cho vấn đề này. Khi Microsoft công bố paper và mã nguồn này, nó đã tạo ra một cơn sốt thực sự.
Nhưng cụ thể nó làm gì? Nó có gì khác biệt với GraphRAG thông thường (Text2Cypher) mà chúng ta đã bàn ở Bài 2?
Chương 7 của cuốn sách "Essential GraphRAG" là tài liệu hướng dẫn chi tiết nhất mà tôi từng đọc về kỹ thuật này. Hãy cùng tôi "mổ xẻ" nó.
Phần 1: "Global Question" - Tử huyệt của RAG truyền thống
Trước hết, hãy định nghĩa vấn đề. Microsoft GraphRAG sinh ra để trả lời Global Question (Câu hỏi toàn cục).
Ví dụ:
"Những xu hướng chiến lược chính nào đang nổi lên trong ngành công nghệ 5 năm qua?"
RAG truyền thống (Vector Search) sẽ tìm 10 đoạn văn ngẫu nhiên có từ "chiến lược", "công nghệ". Kết quả là một câu trả lời phiến diện, manh mún. Nó giống như thầy bói xem voi, sờ được cái chân, cái tai nhưng không thấy con voi.
Phần 2: Kiến trúc Map-Reduce trên Đồ thị Cộng đồng
Microsoft giải quyết bài toán này bằng chiến thuật "Chia để trị" (Map-Reduce) trên cấu trúc đồ thị.
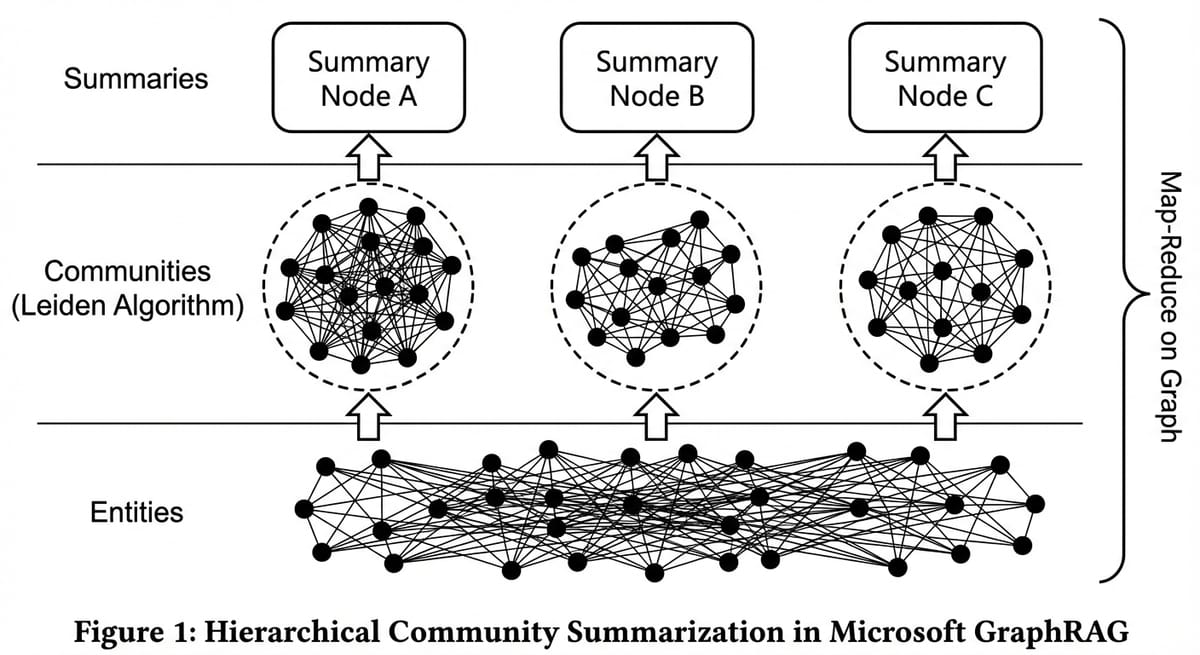
Hierarchical Summarization
Dựa trên paper "From Local to Global: A Graph RAG Approach to Query-Focused Summarization" (Edge et al., Microsoft Research, 2024).
Họ sử dụng thuật toán Leiden (cải tiến của Louvain, xem paper gốc) để tối ưu hóa chỉ số Modularity - một thước đo mật độ kết nối bên trong cộng đồng so với giữa các cộng đồng. Thuật toán này có độ phức tạp O(n log n), cho phép xử lý đồ thị hàng triệu node trong vài phút.

Quy trình:
- Indexing:
- Trích xuất Graph.
- Chạy thuật toán Louvain để phân rã Graph thành các cộng đồng phân cấp (Hierarchical Communities).
- Dùng LLM tóm tắt từng cộng đồng này (Community Reports).
- Retrieval:
- Khi người dùng hỏi, hệ thống không tìm node.
- Nó tìm các bản tóm tắt cộng đồng liên quan.
- Nó tổng hợp (Reduce) các bản tóm tắt đó thành câu trả lời cuối cùng.
Phần 3: Góc độ Kinh tế (Business Value) - Tiền nào của nấy
Sức mạnh của Microsoft GraphRAG đi kèm với một cái giá rất chát: Chi phí Indexing.
Hãy làm một phép tính nhanh:
- Bạn có 1000 tài liệu. * Trích xuất ra 100.000 entities.
- Tạo thành 5.000 cộng đồng (các cấp).
- Bạn phải gọi LLM 5.000 lần để tóm tắt các cộng đồng này.
- Mỗi lần tóm tắt tốn khoảng 2.000 tokens.
- Tổng: 10 triệu tokens đầu vào chỉ để Indexing. (~$30-$50 với GPT-4o-mini).
So sánh:
- Vector Indexing: Tốn vài xu (embedding model rẻ bèo).
- MS GraphRAG Indexing: Tốn vài chục đô.
Khi nào nên dùng?
- Đừng dùng cho chatbot FAQ đơn giản.
- Hãy dùng cho các ứng dụng Intelligence & Discovery (Tình báo, Nghiên cứu y khoa, Phân tích pháp lý) - nơi việc phát hiện ra một xu hướng ngầm (Hidden Pattern) trị giá hàng triệu đô la, xứng đáng với chi phí bỏ ra.
Alternative: LightRAG
Nếu chi phí indexing của Microsoft GraphRAG quá cao, bạn có thể xem xét LightRAG (HKUDS, 2024) - một biến thể nhẹ hơn với ý tưởng tương tự nhưng tối ưu hóa số lần gọi LLM. LightRAG sử dụng dual-level retrieval (entity-level và relation-level) thay vì community summarization, giảm chi phí indexing xuống còn 1/10 trong khi vẫn giữ được phần lớn khả năng trả lời global questions.
Kết luận
Microsoft GraphRAG là một bước đột phá về Sense-making (Tạo nghĩa). Nó cho phép AI nhìn thấy "rừng" chứ không chỉ thấy "cây". Tuy nhiên, sức mạnh này đi kèm với chi phí indexing đáng kể - đây là trade-off cần cân nhắc kỹ.
Dù bạn chọn Microsoft GraphRAG hay LightRAG, cả hai đều có một yêu cầu chung: Chất lượng của Knowledge Graph đầu vào. Nếu đồ thị bị nhiễu, bị trùng lặp entity, thì mọi thuật toán đều vô nghĩa.
Tiếp theo trong series: Bài 5: ETL cho GenAI - Quy trình xây dựng Knowledge Graph sạch từ dữ liệu thô, với trọng tâm là Entity Resolution.