Agentic RAG: Tại sao AI cần biết tự suy nghĩ và điều phối?
RAG truyền thống quá cứng nhắc. Tại sao bạn cần Agentic RAG với ReAct loop, Router pattern, và Tools để xử lý câu hỏi phức tạp?
Agentic RAG: Tại sao AI cần biết tự suy nghĩ và điều phối?
Bài 3/6 trong series "Làm chủ GraphRAG" - Phân tích chuyên sâu dựa trên cuốn Essential GraphRAG của Tomaž Bratanič và Oskar Hane

Khi RAG thông thường gặp câu hỏi kiểu "So sánh doanh thu Avatar 2 với Nhà Bà Nữ và tóm tắt phản ứng khán giả về diễn xuất", nó sẽ đứng hình. Giống như bạn đưa cho một đầu bếp chỉ biết nấu mì gói một công thức lobster thermidor vậy - anh ta sẽ nhìn bạn với ánh mắt vô hồn rồi cho ra một tô mì có rắc... tôm hùm?
Vấn đề không phải thiếu nguyên liệu. Vector Search có thể tìm reviews, Text2Cypher có thể query doanh thu. Vấn đề là không ai điều phối, không ai biết khi nào dùng cái gì, và quan trọng nhất - không ai kiểm tra xem câu trả lời đã đủ chưa trước khi serve cho khách.
Đây là lúc chúng ta cần biến AI từ một "công cụ tìm kiếm" thành một "agent" biết tự suy nghĩ.
TL;DR
- Vấn đề: RAG truyền thống (Linear Chain) quá cứng nhắc, không xử lý được câu hỏi phức tạp đa bước hoặc câu hỏi mơ hồ.
- Giải pháp: Agentic RAG với kiến trúc vòng lặp (Loop).
- Thành phần: Router (Phân loại) + Tools (Vector/Graph) + Critic (Kiểm tra).
- Mô hình: Sử dụng ReAct (Reason + Act) để AI tự suy luận và sửa sai.
- Kinh tế: Chi phí cao hơn gấp 4-5 lần RAG thường, nhưng cần thiết cho các tác vụ nghiệp vụ phức tạp (Complex Reasoning).
Series roadmap: Bài 1: Tại sao cần Graph → Bài 2: Text2Cypher → Bài 3 (Agentic RAG) → Bài 4: Microsoft GraphRAG → Bài 5: ETL → Bài 6: Evaluation
Ở hai bài trước, chúng ta đã mài giũa từng công cụ đơn lẻ. Chúng ta đã biết cách dùng Vector Search để tìm kiếm ngữ nghĩa (Bài 1), và Text2Cypher để truy vấn dữ liệu cấu trúc (Bài 2).
Bây giờ, hãy tưởng tượng bạn là một người thợ mộc. Bạn có cái búa (Vector) và cái cưa (Graph). Nhưng để đóng được một cái bàn, bạn cần nhiều hơn thế. Bạn cần biết khi nào dùng búa, khi nào dùng cưa, và quan trọng nhất, bạn cần một bộ não để lên kế hoạch và kiểm tra thành phẩm.
Đó chính là bước chuyển mình từ RAG Tĩnh (Static RAG) sang Agentic RAG (RAG Đại lý/Tự chủ). Chương 5 của cuốn sách đã mở ra cho tôi một chân trời mới về kiến trúc hệ thống, nơi AI không còn là một cái máy trả lời thụ động, mà trở thành một nhân viên chủ động giải quyết vấn đề.
Phần 1: Tại sao quy trình RAG Tuyến tính (Linear Chain) lại "ngu ngốc"?
Hầu hết các hướng dẫn RAG trên mạng (kể cả LangChain cơ bản) đều dạy quy trình tuyến tính:User Input -> Retrieve (mặc định là Vector) -> LLM Generate -> Output.
Quy trình này hoạt động tốt với các câu hỏi đơn giản kiểu FAQ: "Chính sách đổi trả là gì?", "Giờ làm việc của cửa hàng?".
Nhưng thế giới thực phức tạp hơn nhiều. Người dùng doanh nghiệp thường hỏi những câu "khoai" như:
"Hãy so sánh doanh thu phòng vé của Avatar 2 và Nhà Bà Nữ, và tóm tắt phản ứng của khán giả về diễn xuất của hai phim này?"
Một pipeline tuyến tính sẽ chết đứng với câu này. Tại sao?
1. Một công cụ không đủ: "Doanh thu" cần Database chính xác (Text2Cypher). "Phản ứng khán giả" cần tìm kiếm ngữ nghĩa (Vector Search). RAG thường chỉ chọn 1 trong 2.
2. Một bước không đủ: Để so sánh, trước hết phải lấy dữ liệu của Avatar 2, sau đó lấy dữ liệu của Nhà Bà Nữ. RAG thường cố làm tất cả trong một lần retrieve duy nhất.
Phần 2: Kiến trúc Agentic RAG - Đa nhân cách
Agentic RAG giải quyết vấn đề này bằng cách phân tách hệ thống thành các module chuyên biệt (Modules), hoạt động phối hợp như một team.
1. The Router (Bộ định tuyến) - Người điều phối
Tư duy "One size fits all" đã chết. Module đầu tiên là Router. Nó là một LLM nhỏ được huấn luyện (hoặc prompt) để phân loại câu hỏi.
Khi nhận câu hỏi phức tạp trên, Router sẽ phân tích: * "Vế 1: Doanh thu Avatar 2 & Nhà Bà Nữ" -> Yêu cầu số liệu chính xác -> Route: Text2Cypher Tool. * "Vế 2: Phản ứng khán giả về diễn xuất" -> Yêu cầu cảm nhận, text -> Route: Vector Search Tool.
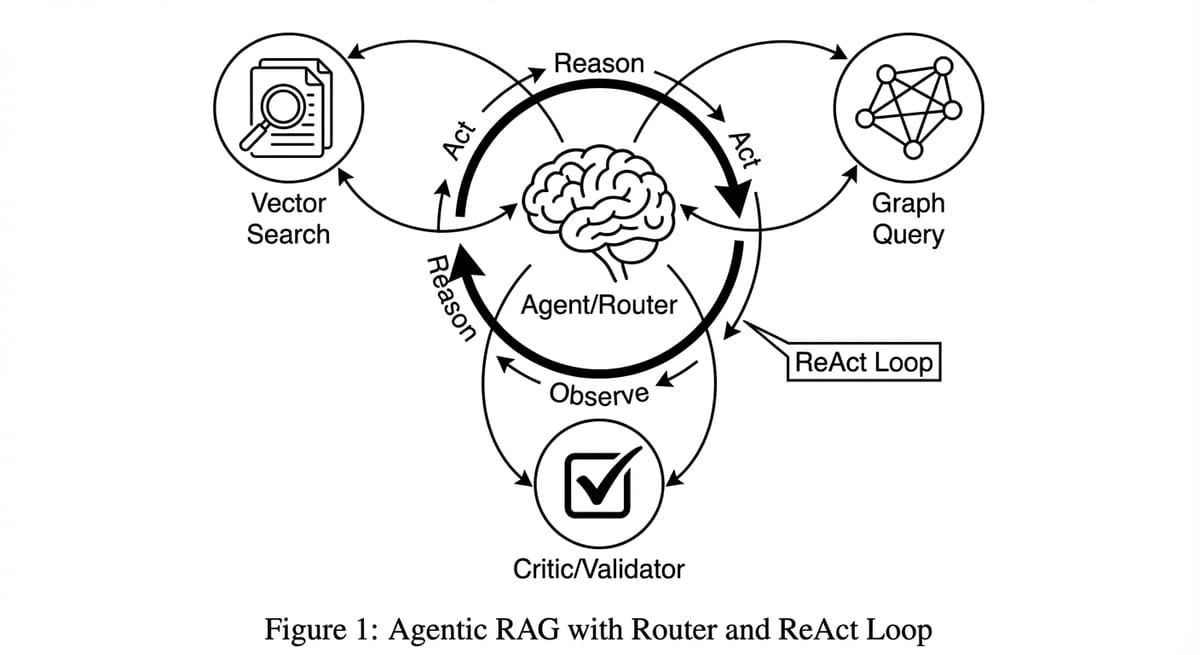
2. ReAct Loop và The Critic - Vòng lặp tự suy nghĩ
Đây là phần tinh túy nhất của Agentic RAG. Trong RAG thường, AI trả lời xong là xong - giống như nhân viên giao hàng ném đồ trước cửa rồi chạy mất. Trong Agentic RAG, chúng ta cài đặt một cơ chế Self-Reflection khiến AI phải tự kiểm tra công việc của mình trước khi "giao hàng".
Kiến trúc này dựa trên paper nổi tiếng "ReAct: Synergizing Reasoning and Acting in Language Models" (Yao et al., 2023 - Google Research & Princeton). Ý tưởng cốt lõi là xen kẽ giữa suy luận (Reasoning) và hành động (Acting), thay vì nghĩ một mạch rồi làm. Paper này chỉ ra rằng ReAct vượt trội hơn cả Chain-of-Thought thuần túy (chỉ reasoning, không action) lẫn Act-only (chỉ action, không reasoning) trên các benchmark như HotpotQA và FEVER.
Điểm khác biệt quan trọng nhất là khả năng self-correction: khi tool trả về kết quả không như mong đợi, agent có thể nhận ra và thử cách khác - thay vì cứ thế hallucinate một câu trả lời.
Vòng lặp ReAct hoạt động như sau:
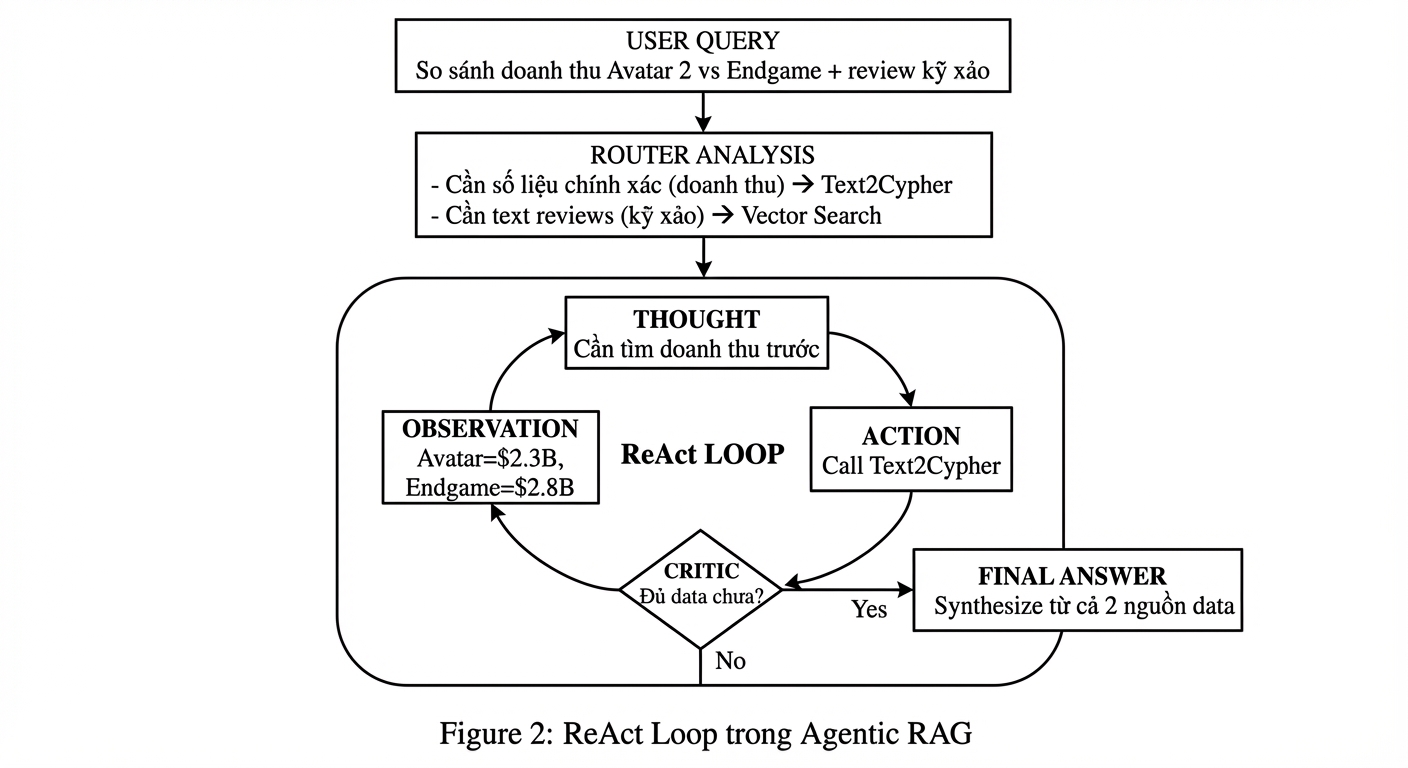
Vai trò của Critic ở đây cực kỳ quan trọng - nó là "người giám sát" quyết định khi nào agent đã thu thập đủ thông tin để trả lời. Không có Critic, agent có thể dừng quá sớm (thiếu data) hoặc loop vô hạn (không biết khi nào dừng).
3. Implementation với LangGraph
Để hiểu rõ hơn, đây là skeleton code triển khai Agentic RAG với LangGraph - framework được thiết kế đặc biệt cho agentic workflows:
from langgraph.graph import StateGraph, END
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
from typing import TypedDict, Annotated, List
import operator
# Define state schema
class AgentState(TypedDict):
query: str
plan: List[str] # Router's plan
collected_data: Annotated[List[str], operator.add] # Accumulate data
current_step: int
final_answer: str
# Define tools
@tool
def text2cypher_search(query: str) -> str:
"""Query structured data từ Neo4j graph database."""
# Implementation: Convert query -> Cypher -> Execute -> Return
pass
@tool
def vector_search(query: str) -> str:
"""Semantic search trong document embeddings."""
# Implementation: Embed query -> Search vector store -> Return chunks
pass
tools = [text2cypher_search, vector_search]
# Node functions
def router_node(state: AgentState) -> AgentState:
"""Phân tích query và lên kế hoạch."""
llm = ChatOpenAI(model="gpt-4o")
prompt = f"""Analyze this query and create an execution plan.
Query: {state['query']}
For each information need, specify which tool to use:
- text2cypher_search: for factual/numerical data
- vector_search: for opinions, reviews, unstructured text
Return a list of steps."""
plan = llm.invoke(prompt)
return {"plan": parse_plan(plan), "current_step": 0}
def execute_node(state: AgentState) -> AgentState:
"""Thực thi tool theo plan."""
current_tool = state["plan"][state["current_step"]]
if "text2cypher" in current_tool:
result = text2cypher_search.invoke(state["query"])
else:
result = vector_search.invoke(state["query"])
return {
"collected_data": [result],
"current_step": state["current_step"] + 1
}
def critic_node(state: AgentState) -> str:
"""Đánh giá: đã đủ data chưa?"""
llm = ChatOpenAI(model="gpt-4o")
prompt = f"""Original query: {state['query']}
Collected data so far: {state['collected_data']}
Remaining plan: {state['plan'][state['current_step']:]}
Is all required information collected? Answer: CONTINUE or COMPLETE"""
decision = llm.invoke(prompt)
return "complete" if "COMPLETE" in decision.content else "continue"
def synthesize_node(state: AgentState) -> AgentState:
"""Tổng hợp câu trả lời cuối cùng."""
llm = ChatOpenAI(model="gpt-4o")
prompt = f"""Query: {state['query']}
Data: {state['collected_data']}
Synthesize a comprehensive answer."""
answer = llm.invoke(prompt)
return {"final_answer": answer.content}
# Build the graph
workflow = StateGraph(AgentState)
workflow.add_node("router", router_node)
workflow.add_node("execute", execute_node)
workflow.add_node("critic", critic_node)
workflow.add_node("synthesize", synthesize_node)
workflow.set_entry_point("router")
workflow.add_edge("router", "execute")
workflow.add_conditional_edges(
"execute",
critic_node,
{
"continue": "execute", # Loop back
"complete": "synthesize" # Exit loop
}
)
workflow.add_edge("synthesize", END)
# Compile and run
app = workflow.compile()
result = app.invoke({
"query": "So sánh doanh thu Avatar 2 và Nhà Bà Nữ, tóm tắt review diễn xuất"
})
Code trên minh họa ba điểm quan trọng: (1) State accumulation - data được tích lũy qua mỗi vòng lặp thay vì bị ghi đè, (2) Conditional edges - Critic quyết định flow tiếp theo, và (3) Separation of concerns - mỗi node làm một việc rõ ràng.
Phần 3: Góc độ Kinh tế (Business Value) - Cái giá phải trả
Nghe thì rất hay, nhưng tại sao không phải ai cũng dùng Agentic RAG?
Vì cái giá phải trả là Độ trễ (Latency) và Chi phí (Cost).
Cost Multiplier (Hệ số nhân chi phí)
Hãy làm một phép tính cụ thể với GPT-4o (giá tháng 1/2025: $2.5/1M input, $10/1M output):
- RAG thường: 1 lần gọi LLM (~2000 tokens). Chi phí: ~$0.005. Latency: 2 giây.
- Agentic RAG: Router (500 tokens) + Tool calls (1000 tokens x 2) + Critic (500 tokens) + Final Generator (2000 tokens). Tổng: ~5000 tokens.
- Latency: Tăng gấp 3-5 lần (8-15 giây do sequential calls).
- Cost: ~$0.02/query - gấp 4 lần.
Với 10,000 queries/ngày: RAG thường tốn $50/ngày, Agentic RAG tốn $200/ngày. Chênh lệch $150/ngày có đáng không? Câu trả lời phụ thuộc vào giá trị của độ chính xác trong domain của bạn.
Chiến lược triển khai: * Tier 1 (Câu hỏi dễ): Dùng RAG thường. Nhanh, rẻ. * Tier 2 (Câu hỏi khó): Dùng Agent. Chấp nhận chậm để đúng. * Hãy dùng Router để phân loại Tier này ngay từ đầu cửa vào.
Kết luận
Agentic RAG là bước tiến hóa tất yếu để AI trở nên hữu dụng trong các tác vụ phức tạp. Nó biến AI từ một "công cụ tìm kiếm" thành một "cộng sự" biết tư duy. Điều quan trọng là hiểu rõ trade-off giữa chi phí và độ chính xác để chọn đúng kiến trúc cho từng use case.
Tuy nhiên, Agentic RAG vẫn có một điểm yếu: Nó giỏi trả lời câu hỏi cục bộ (local questions) về các entities cụ thể, nhưng lại bó tay với câu hỏi toàn cục (global questions) như "Xu hướng chung của dữ liệu này là gì?". Đây là lúc chúng ta cần một vũ khí khác.
Tiếp theo trong series: Bài 4: Microsoft GraphRAG - Kỹ thuật Community Detection và Map-Reduce để trả lời các câu hỏi mang tính toàn cục.