Text2Cypher Tutorial: Biến câu hỏi thành truy vấn Database với LLM
Làm sao để LLM hiểu schema database của bạn? Hướng dẫn Text2Cypher với Schema Injection, Few-shot Prompting, và Error Correction.
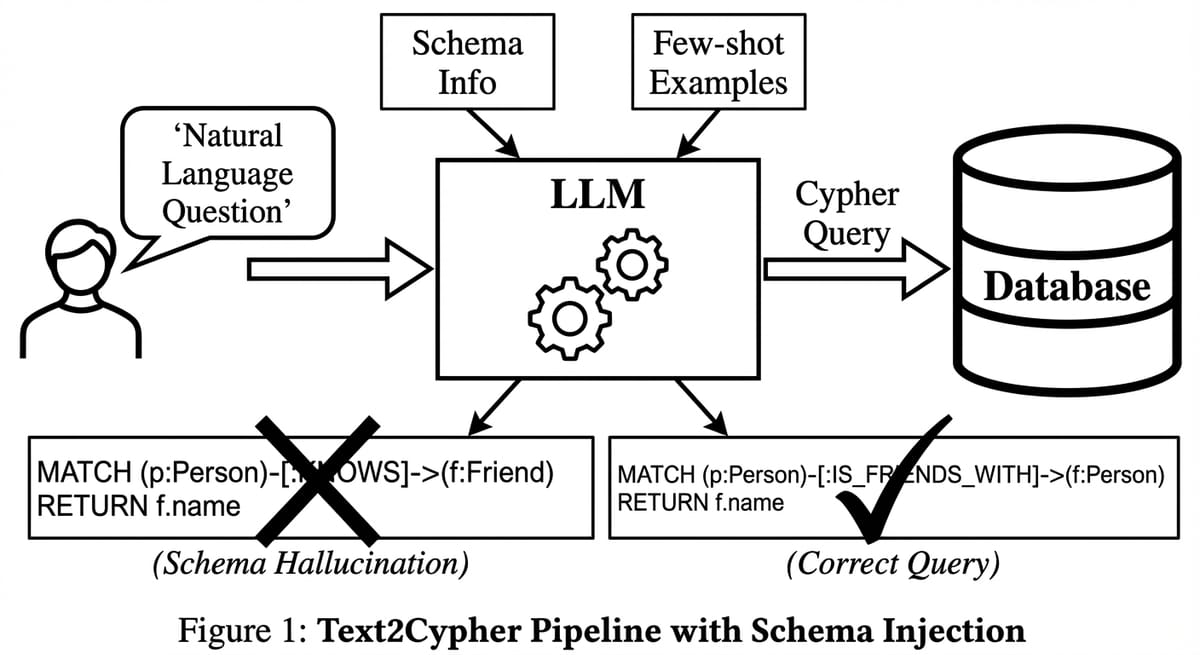
Text2Cypher Tutorial: Biến câu hỏi thành truy vấn Database với LLM
Bài 2/6 trong series "Làm chủ GraphRAG" - Phân tích chuyên sâu dựa trên cuốn Essential GraphRAG của Tomaž Bratanič và Oskar Hane
TL;DR
- Vấn đề: LLM không biết cấu trúc Database của bạn, dẫn đến việc sinh ra câu truy vấn (Cypher/SQL) bịa đặt (Schema Hallucination).
- Giải pháp 1 (Schema Injection): Trích xuất Metadata gọn nhẹ và "tiêm" vào System Prompt.
- Giải pháp 2 (Few-Shot): Cung cấp 3-5 ví dụ mẫu (Question -> Cypher) để LLM học "phong cách" truy vấn.
- Kinh tế: Việc đầu tư token cho Schema và Few-shot giúp giảm 90% lỗi runtime, tiết kiệm chi phí sửa lỗi (retry cost).
Series roadmap: Bài 1: Tại sao cần Graph → Bài 2 (Text2Cypher) → Bài 3: Agentic RAG → Bài 4: Microsoft GraphRAG → Bài 5: ETL → Bài 6: Evaluation
Ở bài trước, chúng ta đã thống nhất rằng Knowledge Graph là mảnh ghép còn thiếu để nâng tầm hệ thống RAG. Nhưng có một rào cản kỹ thuật sừng sững ngay trước mắt: Ngôn ngữ truy vấn.
Người dùng cuối (End-user) của chúng ta - các vị giám đốc, nhân viên kinh doanh, hay khách hàng - họ nói tiếng Việt, tiếng Anh. Họ không nói tiếng Cypher (ngôn ngữ truy vấn của Neo4j) hay SQL.
Để nối hai thế giới này lại, chúng ta cần một "người phiên dịch". Và trong kỷ nguyên GenAI, người phiên dịch đó chính là LLM thông qua kỹ thuật Text2Cypher (hoặc Text2SQL).
Thoạt nghe, việc này có vẻ dễ: "Cứ ném schema và câu hỏi vào ChatGPT là xong, nó biết code mà!".
Tôi cũng từng ngây thơ nghĩ vậy. Và tôi đã phải trả giá bằng hàng tá lỗi runtime, những câu truy vấn sai logic, và thậm chí là những lỗ hổng bảo mật.
Chương 4 của cuốn sách "Essential GraphRAG" đã khai sáng cho tôi. Nó chỉ ra rằng Text2Cypher không phải là một tác vụ "gọi API là xong", mà là một quy trình kỹ thuật tinh xảo đòi hỏi Prompt Engineering, Schema Management, và Error Handling.
Phần 1: Cái bẫy của Zero-shot và Ảo giác Schema (Schema Hallucination)

Hãy bắt đầu bằng một thất bại điển hình.
Giả sử tôi có một Database về phim ảnh. Tôi gửi prompt sau cho GPT-4:
Prompt: "Viết câu lệnh Cypher để tìm tất cả các diễn viên đóng trong phim Matrix?"
GPT-4, với sự tự tin của một thực tập sinh nhiệt huyết, trả lời ngay:
MATCH (a:Actor)-[:PLAYED_IN]->(m:Movie {title: 'Matrix'})
RETURN a.name
Nhìn qua thì rất chuẩn. Cú pháp Cypher đúng. Logic đúng.
Nhưng khi chạy vào Database của tôi, nó báo lỗi hoặc trả về rỗng. Tại sao?
- Sai nhãn (Label mismatch): Trong DB của tôi, diễn viên được gán nhãn là
:Person, không phải:Actor. (LLM đoán mò dựa trên kiến thức chung). - Sai quan hệ (Relationship mismatch): Mối quan hệ là
:ACTED_IN, không phải:PLAYED_IN. - Sai dữ liệu (Data mismatch): Phim tên là "The Matrix", không phải "Matrix".
Đây gọi là Schema Hallucination (Ảo giác về cấu trúc). LLM đang tưởng tượng ra một cấu trúc dữ liệu "chuẩn sách giáo khoa" thay vì nhìn vào dữ liệu thực tế của bạn.
Phần 2: Schema Injection - Đưa bản đồ cho người mù
Để khắc phục điều này, nguyên tắc số 1 là: Đừng bao giờ để LLM đoán. Hãy đưa cho nó "tấm bản đồ". Kỹ thuật này gọi là Schema Injection.
Nhưng đưa thế nào? Bạn không thể copy toàn bộ dữ liệu (hàng triệu dòng) vào prompt. Bạn chỉ cần đưa Metadata.
Cách trích xuất Schema thông minh
Sách gợi ý sử dụng thư viện APOC của Neo4j để lấy schema một cách tự động và gọn nhẹ.
Câu lệnh CALL apoc.meta.schema() sẽ trả về cấu trúc của đồ thị.

Sau khi xử lý, tôi tạo ra một đoạn text mô tả schema để nhúng vào System Prompt:
# Graph Schema
Nodes:
- Person {name: STRING, born: INTEGER}
- Movie {title: STRING, released: INTEGER, tagline: STRING}
Relationships:
- (:Person)-[:ACTED_IN {roles: LIST}]->(:Movie)
- (:Person)-[:DIRECTED]->(:Movie)
Khi đưa đoạn này vào prompt, LLM như người mù vớ được gậy. Nó biết chính xác: "À, mình phải dùng :Person, không được dùng :Actor".
Semantic Parsing
Text-to-SQL/Cypher thực chất là bài toán Semantic Parsing kinh điển trong NLP: chuyển đổi câu tự nhiên thành biểu diễn logic (Logical Form). Benchmark nổi tiếng nhất cho bài toán này là Spider (Text-to-SQL) với hơn 10,000 câu hỏi trên 200 databases.
Các nghiên cứu gần đây như DIN-SQL và DAIL-SQL chỉ ra rằng việc cung cấp Schema ngữ nghĩa và Few-shot examples giúp tăng độ chính xác lên 30-40% so với mô hình sinh tự do. Đặc biệt, kỹ thuật Schema Linking (liên kết từ khóa trong câu hỏi với column/table name) là yếu tố quyết định.
Phần 3: Few-Shot Prompting - Dạy bằng ví dụ (In-Context Learning)
Schema giúp LLM viết đúng cú pháp, nhưng chưa chắc đã viết đúng logic tối ưu.
Ví dụ, câu hỏi: "Ai là người đóng nhiều phim nhất?"
Zero-shot LLM có thể viết:
MATCH (p:Person)-[:ACTED_IN]->(m:Movie)
RETURN p.name, count(m)
ORDER BY count(m) DESC LIMIT 1
(Câu này đúng).
Nhưng với câu hỏi khó hơn: "Tìm các bạn diễn chung của Tom Hanks?"
LLM có thể lúng túng không biết đi theo chiều nào của mũi tên.
Giải pháp là Few-Shot Prompting. Chúng ta cung cấp các cặp (Câu hỏi -> Cypher mẫu) ngay trong prompt.
Ví dụ mẫu:
Q: Tìm phim của Tom Hanks.
A:MATCH (p:Person {name: 'Tom Hanks'})-[:ACTED_IN]->(m:Movie) RETURN m.title
Góc độ Kinh tế (Business Value): ROI của Prompt Tokens
Bạn có thể lo ngại: "Thêm ví dụ vào Prompt làm tốn thêm token (tiền)".
Hãy làm một phép tính ROI: * Chi phí: Thêm 200 token (~$0.002 với GPT-4) cho vài ví dụ. * Lợi ích: Tăng tỷ lệ thành công từ 50% lên 90%.
Nếu không có ví dụ, bạn mất 50% số lần gọi API mà không ra kết quả (lãng phí tiền), cộng thêm trải nghiệm người dùng tồi tệ. Đầu tư vào Few-shot là khoản đầu tư sinh lời cao nhất trong Prompt Engineering.
Phần 4: Error Correction Loop - Cơ chế tự sửa sai
Dù bạn chuẩn bị kỹ đến đâu, LLM vẫn có lúc sai. Nó có thể viết thiếu dấu ngoặc, sai tên biến.
Thay vì crash chương trình và báo lỗi cho người dùng, hãy dùng chính LLM để sửa lỗi.
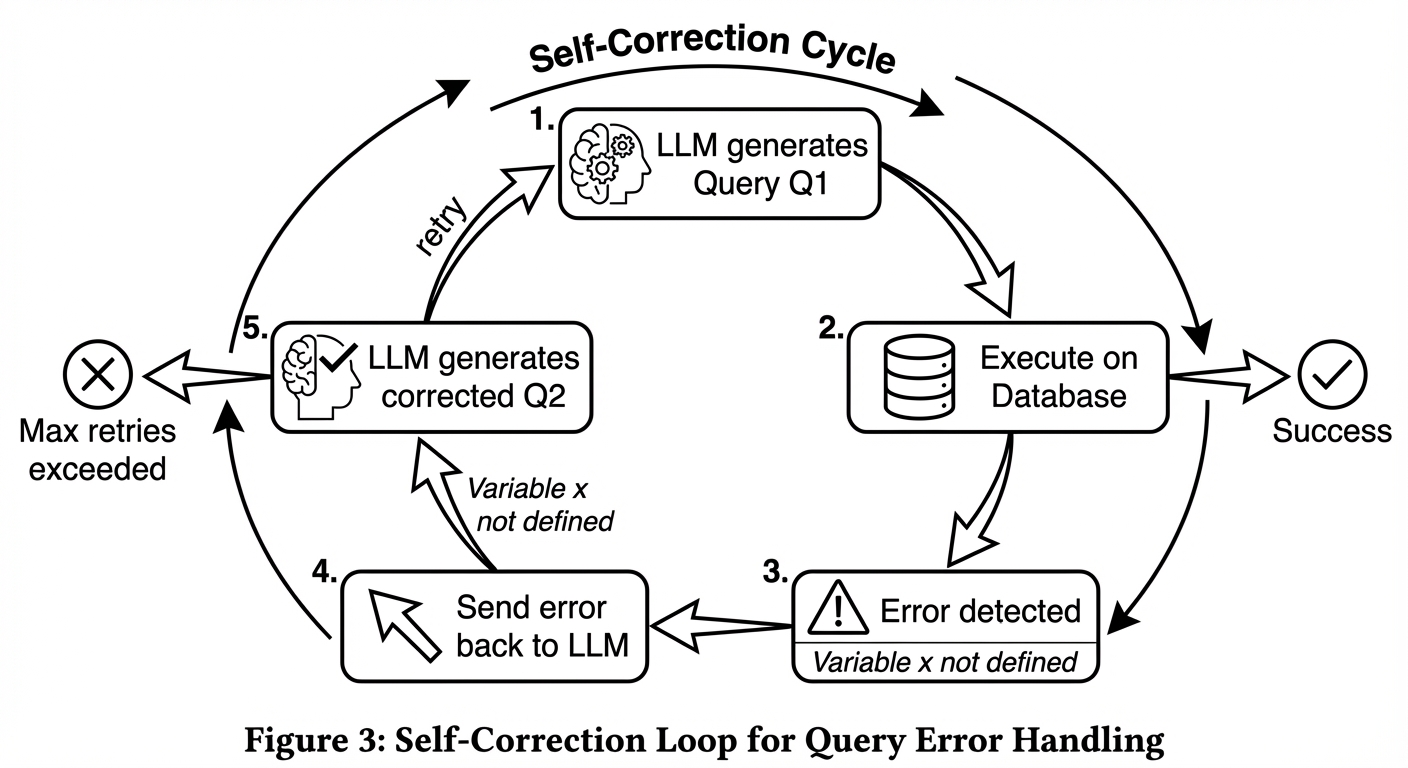
Quy trình Self-Correction:
1. LLM sinh ra Cypher $Q_1$.
2. Hệ thống chạy $Q_1$ vào DB.
3. DB báo lỗi: Error: Variable 'x' not defined.
4. Hệ thống bắt lỗi này, gửi lại cho LLM một prompt mới:
> "Bạn vừa viết câu lệnh này: $Q_1$. Database báo lỗi: .... Hãy sửa lại."
5. LLM sinh ra $Q_2$. (Thường là sẽ đúng ở lần 2).
Kết luận
Text2Cypher không phải là phép màu. Nó là một quy trình kỹ thuật có hệ thống:
- Schema Injection là nền móng - giúp LLM "nhìn thấy" cấu trúc dữ liệu thực.
- Few-Shot Prompting là khung sườn - dạy LLM "phong cách" truy vấn của hệ thống bạn.
- Correction Loop là hệ miễn dịch - tự động phát hiện và sửa lỗi.
Khi kết hợp tất cả lại, bạn trao cho người dùng một quyền năng to lớn: Khả năng khai thác dữ liệu phức tạp chỉ bằng lời nói. Nhưng Text2Cypher mới chỉ là một công cụ đơn lẻ. Trong thực tế, câu hỏi của người dùng thường cần kết hợp nhiều nguồn dữ liệu khác nhau.
Tiếp theo trong series: Bài 3: Agentic RAG - Xây dựng kiến trúc AI tự chủ với Router và Critic, biết khi nào dùng Vector, khi nào dùng Graph.