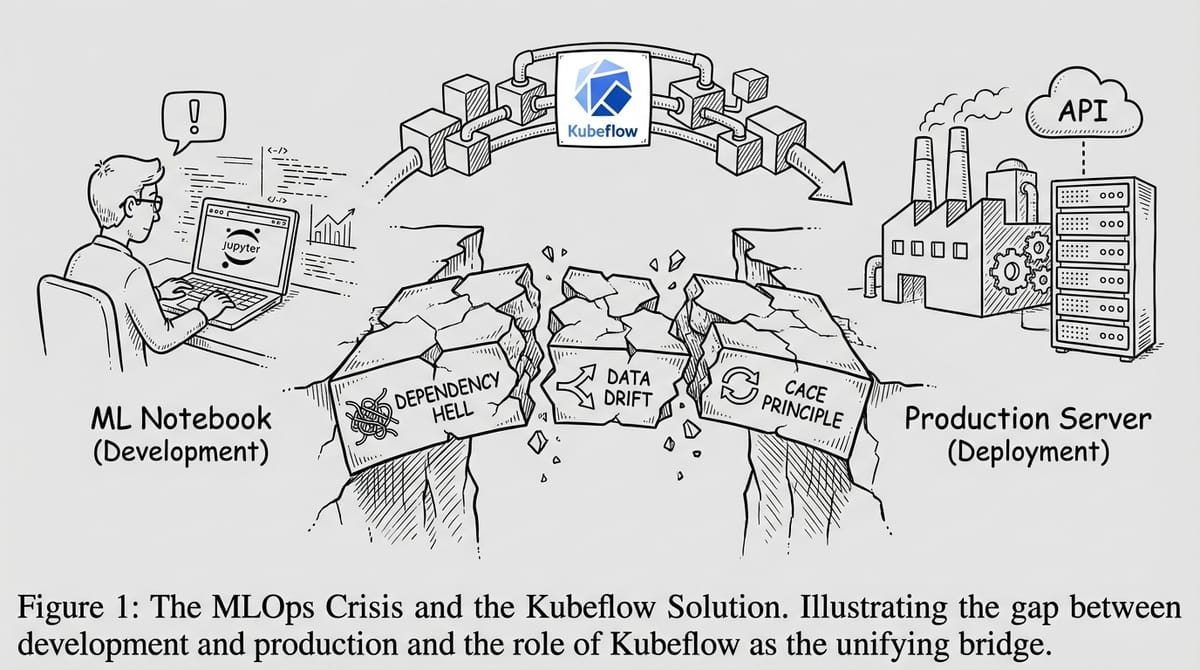
MLOps Crisis: Tại sao Model 99% Accuracy Vẫn Chết Ở Production?
Tại sao 80% AI projects thất bại (trust me bro)? Cách Kubeflow giúp bạn làm MLOps
TL;DR
- Vấn đề: Hơn 80% AI/ML projects thất bại RAND Corporation (2024) - gấp đôi tỷ lệ thất bại của IT projects thông thường. Không ít trong số đó chắc là vì infrastructure (nguồn - trust me bro).
- Nguyên nhân: Dependency Hell, Data Versioning, nguyên tắc CACE ("Changing Anything Changes Everything"), và sự phức tạp của Kubernetes.
- Giải pháp: Kubeflow - Nền tảng Cloud-Native ML (đã được CNCF chấp nhận) giúp mang sức mạnh của K8s đến tay Data Scientist mà không cần họ phải viết hàng trăm dòng YAML.
- Series này: Hướng dẫn từ Zero-to-Kirito về xây dựng hệ thống MLOps hiện đại với Kubeflow 1.9+.
Hãy cùng ghé thăm Công ty Công nghệ Ép Bê Tông (EpBeTong Corp) - một startup kỳ nhông trong mảng AI Outsourcing.
Nhân vật chính của chúng ta là Bình, một Senior AI Intern với 8 năm kinh nghiệm "git pull && fit model".
Bình vừa dành 2 tuần thức trắng đêm để fine-tune một con model BERT xịn xò để nhận diện sắc thái "văn văn vở vở" trong báo cáo công việc của nhân viên. Accuracy đạt 99.5% trên tập test. Sếp tổng gật gù, đồng nghiệp tán thưởng. Bình hăm hở gửi file Final_Model_v3_REAL_FINAL.ipynb cho anh Độ SysAdmin (người đang nắm giữ chìa khóa Server Room) để deploy.
3 ngày sau ...
Anh Độ quay lại với cuộc gọi:
"Alo! Bình phải không em? Bình ơi, anh nói chú bao lần rồi. Cái thư viện torch-geometric bản chú dùng nó xung đột với cái base image Ubuntu của công ty. Với lại, chú load cái file CSV từ đường dẫn C:/Users/Binh/Downloads/data.csv, server anh chạy Linux thì lấy đâu ra ổ C hả em?"
The MLOps Crisis - đây là bức tường giữa Development (Lab) và Operations (Production).
Bình và anh Độ không đơn độc.
Câu hỏi đặt ra là: Tại sao việc đưa một ML model lên Production lại khó hơn gấp 10 lần so với đưa một Web App thông thường, và Kubeflow sinh ra để giải quyết cục nợ này như thế nào?
The "It dự đoán đúng on My Machine"
Trong Software Engineering truyền thống, chúng ta đã giải quyết bài toán "works on my machine" bằng Docker. Code + Dependencies được đóng gói vào một Container. Chạy ở đâu cũng như nhau.
Nhưng với Machine Learning, mọi thứ phức tạp hơn nhiều. Một ML System không chỉ có Code. Nó là tổ hợp của 3 thứ biến thiên liên tục:
1. Code: Thuật toán, model architecture.
2. Data: Training data thay đổi hàng ngày. Schema thay đổi. Distribution thay đổi (Drift).
3. Configuration: Hyperparameters, Environment variables, GPU drivers, CUDA versions.
"Hidden Technical Debt"
Năm 2015, một nhóm kỹ sư tại Google đã công bố một paper: "Hidden Technical Debt in Machine Learning Systems" (Sculley et al., NeurIPS 2015). Với hơn 7000 citations tính đến nay, paper này đã giúp khóc thuê cho giới MLOps. Họ đưa ra một nhận định cay đắng: Machine Learning là "tấm thẻ tín dụng" có lãi suất cực cao của nợ kỹ thuật (Technical Debt).
Paper đưa ra nguyên tắc quan trọng nhất mà mọi ML Engineer cần thuộc lòng: "CACE - Changing Anything Changes Everything" (Thay đổi bất kỳ thứ gì cũng ảnh hưởng đến mọi thứ khác).
Trong ML systems, điều này có nghĩa là:
- Thay đổi training data → Model behavior thay đổi hoàn toàn
- Thay đổi một feature → Downstream features bị ảnh hưởng dây chuyền
- Thay đổi hyperparameter → Toàn bộ experiment cần re-run và re-validate
Đây chính là lý do tại sao chúng ta cần Pipeline + Versioning + Reproducibility - và Kubeflow Pipelines được thiết kế để giải quyết chính xác điều này.

Figure 1: Phần ML Code (màu đen ở giữa) chỉ là một mảnh nhỏ trong toàn bộ hệ sinh thái cần thiết để vận hành model.
Nhìn vào sơ đồ trên, bạn sẽ thấy phần ML Code chỉ là một ô vuông bé tí xíu nằm giữa một biển trời các hệ thống hỗ trợ:
- Configuration: Cấu hình tham số, môi trường.
- Data Collection & Verification: Thu thập và kiểm tra dữ liệu sạch.
- Feature Extraction: Trích xuất đặc trưng.
- Monitoring: Giám sát model sau khi deploy.
- Serving Infrastructure: Hạ tầng để chạy model cho user dùng.
Nếu bạn chỉ tập trung vào cái ô vuông bé tí đó (viết code trong Notebook), bạn đang bỏ qua 95% công việc còn lại để tạo ra giá trị thực tế. Và đó chính là lý do tại sao model của bạn "chết yểu".
Tại sao Kubernetes là câu trả lời (nhưng cũng là của nợ)?
Để quản lý cái đống hỗn độn kia ở quy mô lớn (Scale), cả thế giới đang dịch chuyển về Kubernetes (K8s).
- Bạn cần train trên 10 GPUs? K8s lo được.
- Bạn cần serve model cho 1 triệu request/giây? K8s scale pods lên.
- Một node bị chết? K8s tự heal.
Nghe ổn đấy - LGTM. Nhưng có một vấn đề nhỏ: Kubernetes cực kỳ khó học. Và phần lớn nhân loại (trong đó có tôi) là ngu ngốc.
Một Data Scientist muốn train model trên K8s phải hiểu:
- PersistentVolumeClaim - để mount training data vào container
- Resource Requests/Limits - để xin GPU và RAM
- Tolerations/Node Affinity - để schedule job lên đúng GPU nodes
- ConfigMaps/Secrets - để inject environment variables
- RBAC (Role-Based Access Control) - để có quyền tạo pods
Đó là khoảng 300-500 dòng YAML chỉ để chạy một training job đơn giản. Bắt một Data Scientist - người dành 5 năm học tiến sĩ bên một quốc gia xa lạ, bị giáo sư bully 18 tiếng/ngày và chỉ cắm mặt vào làm việc với Pandas, Scikit-learn và những dòng code Python không quá 1 gang tay - phải ngồi viết đống YAML đó là một tội ác. Họ không muốn quan tâm đến Pods hay Nodes. Họ chỉ biết: "Input là Data, Output là Model, chấm hết. Muốn tranh cãi thì đặt lịch nói chuyện với cái PhD của tao đi.*
Đây chính là khoảng trống (The gap) mà Kubeflow lấp đầy.

Figure 2: Kubeflow hoạt động như một hệ điều hành ML, che giấu sự phức tạp của hạ tầng Kubernetes bên dưới.
Triết lý "Smithy to Factory": Từ Lò Rèn đến Nhà Máy
Trước khi đi vào Kubeflow, hãy nói về triết lý đằng sau việc xây dựng sản phẩm AI. Tại EpBeTong Corp, mọi dự án đều đi qua 4 giai đoạn:
Phase 1: Idea to Smithy (Ý tưởng vào Lò Rèn)
Đây là giai đoạn brainstorm, mô tả use cases, xác định business requirements. Câu hỏi cần trả lời: "AI sẽ giải quyết vấn đề gì cho end user?"
Output: Requirements document, user stories, success metrics đã được establish.
Phase 2: Data to Smithy (Dữ liệu vào Lò Rèn)
Tìm các nguồn data khả dụng, đo đếm, thử nghiệm với nhiều models khác nhau, đánh giá độ chính xác. Đây là giai đoạn "rèn" - nơi Data Scientists dập đống data của anh ấy tới tấp để để tìm ra công thức tốt nhất.
Output: Data sources đã validate, model architecture đã chọn, baseline metrics đã establish.
Phase 3: Smithy to Factory (Từ Lò Rèn đến Nhà Máy)
Đây là bước chuyển đổi quan trọng nhất - và cũng là nơi phần lớn projects thất bại. Mang những gì đã được "rèn" trong notebook đến "nhà máy" để sản xuất hàng loạt.
Giai đoạn này, nếu đen thì bạn có thể nhận được 1 file Notebook dài ngàn dòng, không chạy được và được tuyên bố độ chính xác là 99%.
Nhiệm vụ của bạn là biến nó thành một hệ thống production-ready, có thể scale, reliable, và maintainable:
- Pipeline tự động hóa toàn bộ flow
- Data crawling/ingestion tự động
- Model tự tuning hyperparameters (AutoML)
- Monitoring system theo dõi 24/7
Output: Production-ready pipeline, automated training, serving infrastructure.
Phase 4: Lifecycle (Vận hành)
Sản phẩm đã ra mắt. Giai đoạn này là về: monitoring, thu thập feedback từ users, detect data drift, retrain khi cần, fix bugs.
Output: Stable, continuously improving AI product.

Figure 3: Vòng đời sản phẩm AI tại EpBeTong Corp - 4 phases từ Idea đến Production.
Vấn đề cốt lõi: Phase 1-2 là về craftsmanship (thủ công) - bạn cần sự sáng tạo, thử nghiệm, trực giác của Data Scientists. Nhưng Phase 3-4 là về engineering (Kỹ nghệ) - bạn cần automation, reliability, scalability.
Đây chính là "The Gap" - khoảng trống giữa Lò Rèn và Nhà Máy. Và Kubeflow được sinh ra để lấp đầy khoảng trống này.
Kubeflow: Cây cầu nối Lò Rèn và Nhà Máy
Kubeflow không phải là một "tool". Nó là một ML Platform chạy trên Kubernetes, được thiết kế để smooth transition từ Phase 2 sang Phase 3-4.
| Phase | Kubeflow Component | Mục đích |
|---|---|---|
| Phase 2 | Notebooks | Môi trường thử nghiệm trên cluster (không phải laptop) |
| Phase 2-3 | Katib | AutoML - tự động tìm hyperparameters tốt nhất |
| Phase 3 | Pipelines (KFP) | Biến notebook code thành production pipeline |
| Phase 3-4 | KServe | Deploy model với auto-scaling, canary rollout |
| Phase 4 | Monitoring | Theo dõi drift, performance, trigger retrain |
Hãy tưởng tượng Kubeflow giống như một hệ điều hành dành riêng cho ML:
- Bạn vẫn viết code trên Jupyter Notebook (thân thuộc!) trong Phase 2
- Khi chuyển sang Phase 3, Kubeflow giúp đóng gói code đó thành Pipeline
- Phase 4? KServe + Monitoring lo hết
Workflow: Ai làm gì trong từng Phase?
"Okay, có platform rồi, ai đóng vai trò gì, swimming lanes thế nào?"
Hãy xem workflow bịa ra tại EpBeTong Corp:
Data Scientist (Phase 1-2: Lò Rèn)
Công việc hàng ngày:
- Tham gia brainstorm requirements cùng Product/Sale team (Phase 1)
- Làm việc trong Kubeflow Notebooks - môi trường Jupyter chạy trực tiếp trên cluster
- Explore data, thử nghiệm algorithms, train prototype models (Phase 2)
- Validate model với business metrics, không chỉ technical metrics
Output cung cấp:
- Validated prototype - notebook code đã chứng minh được value
- Model artifacts - trained model files (.pkl, .pt, .onnx)
- Experiment results - metrics, hyperparameters đã thử nghiệm qua Katib
Data/AI Engineer (Phase 2-3: Lò Rèn → Nhà Máy)
Công việc hàng ngày:
- Nhận prototype code từ Data Scientist, chuyển thành production-ready pipeline
- Viết Pipeline definition (file
.pysử dụng KFP SDK) - Đóng gói components thành container images
- Tối ưu pipeline cho performance và scalability
- Setup data ingestion tự động, feature store integration
Output cung cấp:
- Pipeline code (
.py) - định nghĩa luồng xử lý hoàn chỉnh - Component images - Docker images cho từng step
- Automated training pipeline - có thể trigger bằng 1 click hoặc schedule

Figure 4: Luồng công việc từ Data Scientist đến AI Ops - mỗi role có trách nhiệm riêng trong từng phase.
AI Ops / Platform Team (Phase 3-4: Nhà Máy)
Công việc chính:
- Quản lý Kubeflow cluster - install, upgrade, maintain components
- Setup CI/CD cho ML - tự động trigger pipeline khi có code mới hoặc data mới
- Configure KServe - deploy models với auto-scaling, canary rollouts
- Monitoring & Alerting - theo dõi model performance, data drift, resource usage (Phase 4)
- Resource Management - phân bổ GPU quotas, manage namespaces cho các teams
Không cần làm:
- Viết ML code (đó là việc của Data Scientists - Phase 2)
- Viết pipeline code (đó là việc của Data/AI Engineers - Phase 3)
- Tune hyperparameters (Katib tự động làm)
Đá qua Security Team tí nhỉ ?
Về cơ bản Kubeflow tích hợp sẵn nhiều layers bảo mật rồi nên Secs team chỉ cần config phần K8s chuẩn là được.
Authentication & Authorization:
- Istio Service Mesh - mọi traffic giữa components đều được mã hóa (mTLS)
- Dex - Single Sign-On (SSO) integration với LDAP, OIDC, GitHub, Google
- RBAC per Namespace - mỗi team có namespace riêng, không truy cập được data của team khác
Multi-tenancy:

Figure 5: Mỗi team có namespace riêng với resources hoàn toàn cách ly.
Data Security:
- Secrets Management - credentials không hardcode, lưu trong K8s Secrets
- Network Policies - giới hạn pods nào có thể communicate với nhau
- Audit Logging - mọi action đều được log để compliance
Security Team cần làm:
- Review và approve network policies
- Configure SSO/LDAP integration
- Setup audit logging và compliance reports
- Định kỳ review RBAC permissions
- Scan container images cho vulnerabilities
Tổng kết: Mapping Phases với Kubeflow

Figure 6: Mapping hoàn chỉnh giữa triết lý "Smithy to Factory" và các components của Kubeflow.
Mapping chi tiết:
| Phase | Kubeflow Tool | Ai làm | Output |
|---|---|---|---|
| Phase 2 | Notebooks + Katib | Data Scientist | Validated prototype |
| Phase 2→3 | KFP SDK | Data/AI Engineer | Pipeline code (.py) |
| Phase 3 | KFP + KServe | AI Ops | Automated deployment |
| Phase 4 | Monitoring | AI Ops | Stable, improving product |
Điểm mấu chốt: Kubeflow không chỉ là tool - nó là cầu nối giúp chuyển giao smooth giữa các phases. Không có Kubeflow (hoặc platform tương tự), bạn sẽ mắc kẹt ở Phase 2 mãi mãi - giống như Bình và anh Độ SysAdmin đầu bài.
Các thành phần cốt lõi của Kubeflow (Modern Stack 2025)
Kubeflow đã được CNCF (Cloud Native Computing Foundation) chấp nhận vào năm 2024 và đang trong quá trình chuẩn bị cho CNCF Graduation - một dấu mốc quan trọng chứng minh độ mature của project. Trong series này, chúng ta sẽ tập trung vào Kubeflow 1.9+ với các components:
- Kubeflow Notebooks 2.0: Môi trường dev cô lập, chạy trực tiếp trên Cluster. Không còn cảnh setup CUDA driver trên máy cá nhân nữa. Version 2.0 mang đến UI mới và tích hợp sâu hơn với các components khác.
- Kubeflow Pipelines (KFP v2): Biến quy trình "Clean Data -> Train -> Evaluate" thành một dây chuyền tự động, có thể tái sử dụng và versioning. KFP v2 sử dụng IR (Intermediate Representation) mới, tương thích với Vertex AI Pipelines của Google Cloud.
- Katib: Bạn không cần ngồi sửa
learning_ratebằng tay nữa. Katib sẽ tự động chạy 100 experiments song song để tìm ra bộ hyperparams tốt nhất (AutoML). Hỗ trợ cả hyperparameter tuning cho LLMs. - KServe (formerly KFServing): Deploy model với các tính năng "thần thánh" như Scale-to-Zero (tiết kiệm tiền khi không có request) hay Canary Rollout (thử nghiệm model mới trên 10% user).
- Trainer 2.0: Component mới cho distributed training với MPI, Horovod, và đặc biệt là LLM Fine-Tuning với DeepSpeed trên Kubernetes. Đây là game-changer cho teams làm việc với Large Language Models.
- Model Registry: Quản lý lifecycle của models - versioning, lineage tracking, stage transitions (Staging → Production), và tích hợp trực tiếp với KServe cho seamless deployment.
Kubeflow vs. The Rest
Tại sao không dùng Airflow?
Airflow rất tuyệt, tôi yêu Airflow. Tôi in logo của Airflow treo lên tường trong phòng làm việc.
Airflow rất phù hợp cho Data Pipelines (ETL), nhưng nó thiếu những thứ ML cần:
- Native GPU scheduling: Airflow không hiểu resource quotas cho GPU
- ML-specific visualizations: Không có UI để visualize Confusion Matrix, Learning Curves, ROC curves
- Distributed training orchestration: Không hỗ trợ MPI, Horovod, DeepSpeed out-of-the-box
- Model serving infrastructure: Bạn vẫn phải tự build serving layer
Nói ngắn gọn: Airflow là General Purpose Orchestrator, Kubeflow là ML-Native Platform.
Tại sao không dùng MLflow?
MLflow cực mạnh về Experiment Tracking (quản lý logs, metrics). MLflow 3 (2025) còn có native support cho LLM operations - prompt engineering, agent tracing, GenAI evaluation. Nhưng MLflow yếu về Infrastructure Orchestration - nó không biết cách schedule jobs lên K8s, phân bổ GPU, hay auto-scale serving endpoints.
Production Pattern phổ biến nhất:
- Kubeflow Pipelines → Orchestrate heavy training jobs trên K8s
- MLflow → Track experiments, log metrics, manage model versions
- KServe → Serve models với auto-scaling và canary deployments
Chúng ta sẽ implement pattern này trong các bài sau của series.
Còn các managed platforms như Vertex AI, SageMaker?
Ngắn gọn, OK. Nếu bạn đã all-in với một cloud provider (GCP hoặc AWS), các managed platforms như Vertex AI Pipelines hay SageMaker Pipelines là lựa chọn tốt - ít ops overhead hơn. Tuy nhiên, Kubeflow cho bạn portability - bạn có thể chạy cùng một pipeline trên GCP, AWS, on-premise, hay thậm chí laptop. Không bị vendor lock-in.
Kế hoạch viết của tôi trong chuỗi "AI Ops with Kubeflow"
từ Zero đến Kirito:
- Bài này: Why Kubeflow? (Done)
- Part 2: Cài đặt Modern Kubeflow (v1.9+) trên Local Cluster - Quên cái
kfctlcũ rích đi, chào đón manifests mới. - Part 3: Building Pipelines - Từ Hello World đến xử lý dữ liệu thực tế với KFP v2.
- Part 4: AutoML với Katib - Train thông minh hơn, không phải trâu bò hơn.
- Part 5: Production Ready - Serving với KServe + Monitoring & Drift Detection.
Code repository đi kèm series: github.com/maycuatroi1/kubeflow-tutorial
Tóm lại thì
Kubeflow không đơn giản. Nó phức tạp vì bài toán MLOps phức tạp. Nhưng một khi bạn đã làm nó ngon lành, bạn sẽ có trong tay một kỹ nghệ sản xuất AI Model tự động, scalable và chuẩn chỉnh. Lương cao, of course!
Nếu bạn thấy bài này hay và muốn tôi tiếp tục viết các phần sau, đừng ngại mà drop DM để dục tôi nhé!