GraphRAG là gì? Tại sao Vector Search không đủ cho Enterprise AI
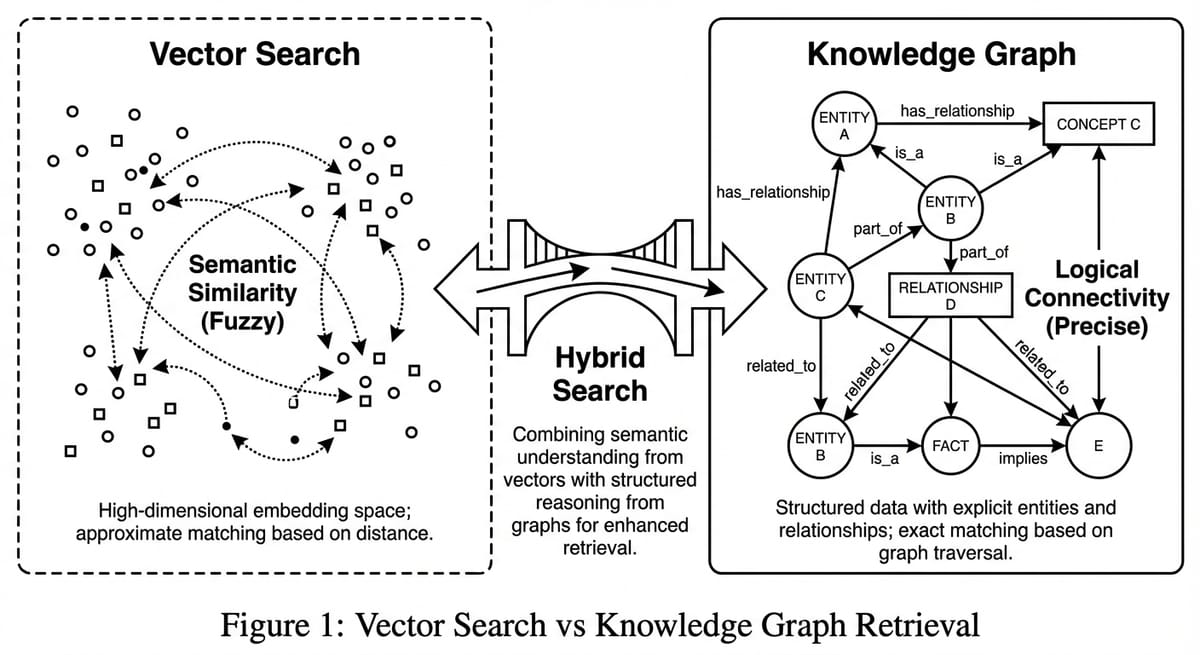
Vector Search bị 'mù' về cấu trúc dữ liệu. Tại sao bạn cần GraphRAG - kết hợp Vector + Knowledge Graph để tăng độ chính xác cho AI doanh nghiệp?
GraphRAG là gì? Tại sao Vector Search không đủ cho Enterprise AI
Bài 1/6 trong series "Làm chủ GraphRAG" - Phân tích chuyên sâu dựa trên cuốn Essential GraphRAG của Tomaž Bratanič và Oskar Hane
TL;DR
- Vấn đề: Vector Search bị "mù" về cấu trúc và logic (Semantic Flattening). Nó không thể trả lời các câu hỏi cần đếm, lọc, hoặc sắp xếp chính xác.
- Giải pháp: GraphRAG bổ sung "bản đồ tư duy" (Knowledge Graph) để thực hiện các truy vấn tất định (deterministic).
- Kiến trúc: Không loại bỏ Vector. Tương lai là Hybrid Search: Vector (Tìm kiếm mờ) + Graph (Truy vấn chính xác).
- Giá trị: Tăng độ chính xác (Factuality) cho các ứng dụng doanh nghiệp, giảm thiểu ảo giác (Hallucination).
Series roadmap: Bài 1 (Tại sao cần Graph) → Bài 2: Text2Cypher → Bài 3: Agentic RAG → Bài 4: Microsoft GraphRAG → Bài 5: ETL → Bài 6: Evaluation

Bạn đã bao giờ demo một chatbot RAG cho sếp, và nó trả lời sai ngay câu hỏi đầu tiên chưa?
Tôi đã ở đó. Nhiều lần. Nếu bạn đang làm việc trong lĩnh vực Generative AI, chắc hẳn bạn đã trải qua "chu kỳ cường điệu" (Hype Cycle) của RAG (Retrieval-Augmented Generation). Giai đoạn đầu là sự kinh ngạc: "Wow, tôi có thể chat với tài liệu PDF của mình!". Giai đoạn hai là sự thất vọng: "Tại sao nó lại trả lời sai những câu đơn giản thế này? Tại sao nó lại bịa ra thông tin không có trong tài liệu?".
Tôi cũng đã ở đó. Tôi đã xây dựng hàng tá ứng dụng RAG sử dụng Vector Database. Tôi đã tinh chỉnh Chunk size, thử nghiệm các mô hình Embedding khác nhau, áp dụng Hybrid Search (kết hợp BM25), và thậm chí dùng Re-ranking. Nhưng vẫn có một "bức tường vô hình" về độ chính xác mà tôi không thể vượt qua được.
Sau khi đọc và nghiền ngẫm cuốn "Essential GraphRAG" của Tomaž Bratanič và Oskar Hane, tôi nhận ra bức tường đó là gì. Đó không phải là vấn đề về mô hình, mà là vấn đề về cấu trúc dữ liệu. Chúng ta đang cố gắng giải quyết các vấn đề logic phức tạp bằng một công cụ thống kê xác suất (Vector Search), và đó là một cuộc chiến không cân sức.
Trong bài viết dài này, tôi sẽ đi sâu vào bản chất kỹ thuật của vấn đề, phân tích tại sao Vector Search thất bại trong việc "tư duy", và Graph (Đồ thị) lấp đầy khoảng trống đó như thế nào.
Phần 1: Sự "Làm phẳng" Ngữ nghĩa (Semantic Flattening) - Tử huyệt của Vector Search
Để hiểu tại sao chúng ta cần Graph, trước hết phải hiểu Vector Search thực sự làm gì.
Khi bạn đưa một đoạn văn bản vào mô hình Embedding (như OpenAI text-embedding-3-small hay BGE), mô hình sẽ nén ý nghĩa của đoạn văn đó thành một vector (một dãy số) trong không gian nhiều chiều (ví dụ 1536 chiều).
Cơ chế "Gần gũi" (Proximity) và giới hạn của nó
Vector Search hoạt động dựa trên nguyên lý: Những thứ có ý nghĩa giống nhau sẽ nằm gần nhau trong không gian vector.
Khoảng cách (thường dùng Cosine Similarity) đại diện cho độ tương đồng.
Ví dụ: * Vector("Apple iPhone") sẽ nằm rất gần Vector("MacBook Pro"). * Vector("Con chó") sẽ nằm xa Vector("Cái bàn").
Điều này tuyệt vời cho việc tìm kiếm từ khóa mờ (fuzzy search) hoặc tìm kiếm theo ngữ cảnh rộng. Nhưng nó có một nhược điểm chí mạng mà tôi gọi là Sự làm phẳng ngữ nghĩa (Semantic Flattening).
Curse of Dimensionality
Trong không gian nhiều chiều, khái niệm "gần" trở nên vô nghĩa khi số chiều tăng lên quá cao. Đây là hiện tượng Curse of Dimensionality được mô tả lần đầu bởi Richard Bellman. Cụ thể, khi số chiều tăng, khoảng cách giữa điểm gần nhất và xa nhất trở nên gần như bằng nhau - khiến việc phân biệt "tương tự" và "không tương tự" mất ý nghĩa.
Hơn nữa, Cosine Similarity chỉ đo góc giữa hai vector, nó bỏ qua độ lớn và cấu trúc nội tại. Các nghiên cứu như MTEB Benchmark chỉ ra rằng Embedding models thường gặp khó khăn với Compositionality (tính kết hợp) - tức là hiểu được rằng "A hit B" khác hoàn toàn với "B hit A", dù vector của chúng rất giống nhau. Ví dụ thực tế: "Apple buys Disney" và "Disney buys Apple" có embedding gần như identical, nhưng ý nghĩa business hoàn toàn ngược nhau.

Case Study: Thảm họa "Retrieve-and-Filter"
Hãy xem xét một ví dụ thực tế mà Vector Search thường xuyên thất bại. Giả sử bạn có một cơ sở dữ liệu về phim ảnh và người dùng hỏi:
"Liệt kê 3 bộ phim được đánh giá cao nhất mà Steven Spielberg ĐẠO DIỄN?"
Hãy mổ xẻ cách Vector Search xử lý câu này:
- Truy vấn: Hệ thống biến câu hỏi thành vector $V_q$.
- Tìm kiếm: Hệ thống quét toàn bộ database để tìm các đoạn văn bản (chunks) có vector $V_c$ gần với $V_q$ nhất.
Nó sẽ tìm thấy gì? * Đoạn A: "Steven Spielberg là nhà sản xuất của phim Transformers..." (Có từ khóa "Spielberg", nhưng vai trò sai). * Đoạn B: "Phim Schindler's List đạt rating 9.0..." (Có rating cao, nhưng có thể đoạn văn này không nhắc đến tên đạo diễn ngay cạnh đó). * Đoạn C: "Steven Spielberg ăn trưa tại Hollywood..." (Có tên, nhưng không liên quan).
Vấn đề #1: Mất liên kết (Disconnected Information)
Thông tin "Tên phim", "Đạo diễn" và "Rating" thường nằm rải rác ở các câu khác nhau hoặc thậm chí các đoạn văn khác nhau. Vector Search không có cơ chế nào để "nhớ" rằng đoạn văn B (Rating) và đoạn văn A (Đạo diễn) đang nói về cùng một thực thể, trừ khi chúng nằm chung trong một chunk.
Vấn đề #2: Mù tịt về Logic (Logic Blindness)
Câu hỏi yêu cầu logic: FILTER (Role == Director) AND SORT (Rating DESC) AND LIMIT (3).
Vector Search không biết lọc, không biết sắp xếp, không biết đếm. Nó chỉ biết "giống nhau". Nó ném cho LLM một mớ hỗn độn các đoạn văn có chứa từ khóa liên quan, và hy vọng LLM đủ thông minh để tự lọc.
Nhưng LLM cũng bó tay nếu thông tin đầu vào bị thiếu hoặc nhiễu. Nếu đoạn văn A nói Spielberg sản xuất Transformers, LLM có thể nhầm lẫn và đưa Transformers vào danh sách đạo diễn. Đây chính là nguồn gốc của Hallucination (Ảo giác).
Phần 2: Knowledge Graph - Tái cấu trúc tư duy cho AI
GraphRAG không chỉ là việc thay database. Nó là việc thay đổi Mô hình tư duy (Mental Model) về dữ liệu.
Thay vì coi dữ liệu là một tập hợp các đoạn văn bản rời rạc (Documents), chúng ta coi dữ liệu là một mạng lưới các Thực thể (Entities) và Mối quan hệ (Relationships).
Trong Graph, câu chuyện của Spielberg trông như thế này:
(p:Person {name: "Steven Spielberg"})
-[:DIRECTED]-> (m1:Movie {title: "Schindler's List", rating: 9.0})
-[:PRODUCED]-> (m2:Movie {title: "Transformers", rating: 7.0})
-[:DIRECTED]-> (m3:Movie {title: "Jurassic Park", rating: 8.2})
Truy xuất tất định (Deterministic Retrieval)
Khi câu hỏi trên được đưa vào hệ thống GraphRAG, chúng ta không đoán mò. Chúng ta thực hiện một cuộc phẫu thuật chính xác.
Hệ thống (thông qua Text2Cypher - sẽ bàn ở bài sau) dịch câu hỏi thành truy vấn đồ thị:
- Tìm node
Personcó tên "Steven Spielberg". - Đi theo cạnh
:DIRECTED(bỏ qua cạnh:PRODUCED). - Đến các node
Movie. - Lấy thuộc tính
.rating, sắp xếp giảm dần. - Lấy top 3.
Kết quả trả về là chính xác tuyệt đối: 100%. Không có nhiễu, không có ảo giác.
Structured Context: Vũ khí chống quên
Một lợi ích to lớn khác của Graph là khả năng cung cấp Structured Context (Ngữ cảnh có cấu trúc).
Khi LLM cần trả lời một câu hỏi phức tạp, ví dụ: "Mối quan hệ giữa đạo diễn Christopher Nolan và diễn viên Cillian Murphy là gì?".
- Vector Search: Trả về 10 bài báo rời rạc, mỗi bài nhắc đến một phim họ hợp tác. LLM phải đọc hết và tự tổng hợp trong đầu.
- Graph Search: Trả về một Sub-graph (Đồ thị con):

Nhìn vào sub-graph này, LLM thấy ngay bức tranh toàn cảnh: "Họ là cộng sự lâu năm, hợp tác qua nhiều dự án lớn". Thông tin được nén (compressed) cực tốt, tiết kiệm token và tăng độ chính xác suy luận.
Phần 3: Kiến trúc Hybrid - Sự kết hợp hoàn hảo
Sau khi đọc đến đây, bạn có thể nghĩ: "Tuyệt, tôi sẽ xóa Vector DB và dùng Neo4j cho mọi thứ".
Dừng lại! Đó là một sai lầm kỹ thuật nghiêm trọng.
Cuốn sách nhấn mạnh rất rõ: Graph không thay thế Vector. Chúng bổ sung cho nhau.
Điểm yếu của Graph
Graph rất tệ trong việc xử lý sự mơ hồ (Ambiguity) và dữ liệu phi cấu trúc (Unstructured data).
Nếu người dùng hỏi: "Tìm những bộ phim có không khí u ám, buồn bã?".
Graph chịu chết. Trong Graph làm gì có node nào tên là "Không khí u ám"? Hay cạnh nào là :FEELS_SAD? Những khái niệm trừu tượng, cảm tính này không thể mô hình hóa cứng nhắc được.
Điểm mạnh của Vector
Đây lại là sân nhà của Vector. Embeddings bắt được sắc thái "u ám", "buồn bã" rất tốt qua ngữ nghĩa văn bản.
Kiến trúc Hybrid Search
Mô hình RAG tối ưu nhất hiện nay (và được đề xuất trong sách) là sự kết hợp 3 lớp:

- Keyword Search (BM25/Full-text):
- Nhiệm vụ: Tìm chính xác từ khóa đặc biệt (Tên riêng, Mã sản phẩm, Mã lỗi).
- Tại sao cần: Vector đôi khi "thông minh quá" lại hóa lú. Tìm "iPhone 14" nó có thể ra "iPhone 13" vì ngữ nghĩa giống nhau. BM25 giúp đảm bảo khớp chính xác từ khóa.
- Vector Search (Semantic):
- Nhiệm vụ: Tìm kiếm theo ý nghĩa, khái niệm rộng, mô tả cảm tính.
- Tại sao cần: Để bắt được những câu hỏi mà người dùng không nhớ chính xác từ khóa, hoặc hỏi về chủ đề trừu tượng.
- Graph Search (Structured):
- Nhiệm vụ: Xử lý logic, quan hệ, tổng hợp số liệu, nhảy cóc đa bước (multi-hop).
- Tại sao cần: Để đảm bảo độ chính xác (Factuality) và khả năng suy luận sâu.
Phần 4: Góc độ Kinh tế & Thực dụng (Business Value)
Chúng ta không chỉ làm kỹ thuật, chúng ta làm sản phẩm. Vậy bài toán kinh tế ở đây là gì?
- Chi phí lưu trữ (Storage Cost): Vector DB thường rẻ hơn và dễ scale hơn (nhờ các giải pháp như Pinecone, Weaviate). Graph DB (như Neo4j Aura) có chi phí cao hơn trên mỗi GB dữ liệu do tính phức tạp của cấu trúc index.
- Chi phí xây dựng (Setup Cost): Vector rất dễ: ném text vào là xong. Graph rất khó: phải thiết kế Schema, phải ETL sạch sẽ.
- ROI (Return on Investment):
- Nếu bạn làm chatbot hỏi đáp đơn giản (FAQ): Vector là đủ. Graph là lãng phí ("Over-engineering").
- Nếu bạn làm ứng dụng Y tế, Pháp lý, Tài chính (nơi sai một ly đi một dặm): Graph là bắt buộc. Chi phí sửa lỗi sai (do Vector hallucination) lớn gấp nhiều lần chi phí xây dựng Graph.
Kết luận: Graph-Enhanced RAG không phải là một "tính năng thêm vào" (nice-to-have). Với tôi, nó là bước tiến hóa bắt buộc của các hệ thống AI thế hệ tiếp theo yêu cầu độ tin cậy cao.
Tiếp theo trong series: Bài 2: Text2Cypher - Làm thế nào để biến ngôn ngữ tự nhiên thành truy vấn đồ thị một cách an toàn và chính xác.