Tại sao LLM lại 'ngu'? Ảo giác, Trí nhớ và Lời giải GraphRAG
LLM gặp 3 vấn đề chí mạng: Hallucination, Knowledge Cutoff, và mù dữ liệu nội bộ. Tại sao chúng ta cần GraphRAG thay vì tin tưởng mù quáng vào ChatGPT?
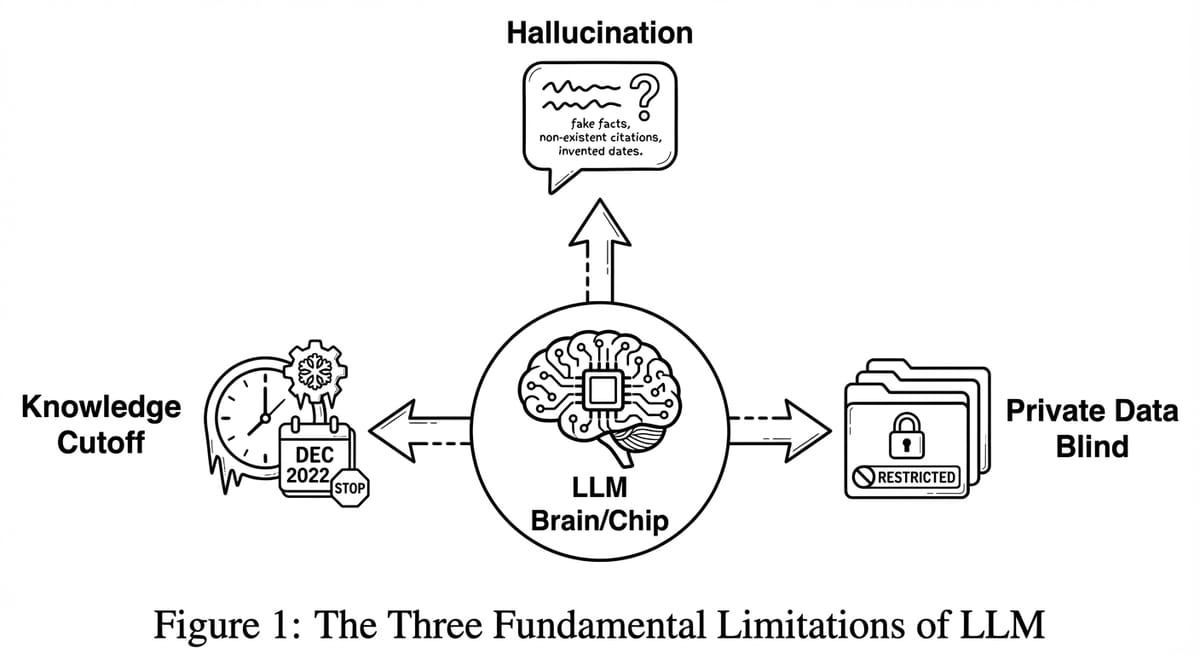
Tại sao LLM lại "ngu"? Ảo giác, Trí nhớ và Lời giải GraphRAG
(Bài 0/6 trong series "Làm chủ GraphRAG" - Phân tích chuyên sâu dựa trên cuốn Essential GraphRAG)
TL;DR
- Vấn đề: LLM không phải là kho tri thức, nó là máy nén dữ liệu có tổn hao (Lossy Compression). Nó gặp 3 lỗi chí mạng: Ảo giác (Hallucination), Lỗi thời (Knowledge Cutoff), và Mù thông tin nội bộ (Lack of Private Knowledge).
- Giải pháp cũ (Fine-tuning): Tốn kém, chậm chạp, khó cập nhật. Giống như bắt học sinh học thuộc lòng cả thư viện.
- Giải pháp mới (RAG): Cho phép LLM tra cứu tài liệu khi trả lời (Open Book Exam).
- Tầm nhìn: Để RAG hoạt động hiệu quả, chúng ta cần nâng cấp từ "Tra cứu từ khóa" (Vector) sang "Tra cứu tri thức" (Graph).
Series roadmap: Bài 0 (Nền tảng) → Bài 1: Vector vs Graph → Bài 2: Text2Cypher → Bài 3: Agentic RAG → Bài 4: Microsoft GraphRAG → Bài 5: ETL → Bài 6: Evaluation
Bạn đã bao giờ tự tin demo ChatGPT cho sếp, rồi nó bịa ra một thông tin hoàn toàn sai ngay trước mặt khách hàng chưa?
Tôi đã ở đó. Năm 2023, một luật sư ở New York tên Steven Schwartz đã dùng ChatGPT để nghiên cứu án lệ cho vụ kiện hãng hàng không. ChatGPT tự tin cite 6 vụ án - tất cả đều không tồn tại. Luật sư bị phạt 5,000 USD và trở thành trò cười của giới pháp lý toàn cầu. Cùng năm đó, chatbot của Air Canada bịa ra chính sách hoàn tiền tang lễ, khiến hãng phải bồi thường cho khách hàng theo đúng "chính sách ma" mà AI đã hứa.
Đây không phải lỗi của người dùng. Đây là bản chất của LLM.
Trước khi chúng ta lao vào viết code Cypher hay xây dựng Agent, hãy dừng lại một chút để trả lời câu hỏi căn bản nhất: Tại sao chúng ta lại cần GraphRAG? Tại sao không cứ dùng ChatGPT là xong?
Chương 1 của cuốn sách "Essential GraphRAG" không dạy code. Nó dạy tư duy. Nó bóc trần bản chất của LLM để chỉ ra rằng: Nếu bạn tin tưởng tuyệt đối vào trí nhớ của LLM, bạn đang xây lâu đài trên cát.

Trong bài viết mở đầu series này, tôi sẽ mổ xẻ cơ chế bên trong của LLM để giải thích tại sao nó lại hay "nói bậy", và tại sao GraphRAG chính là mảnh ghép còn thiếu để biến LLM thành một chuyên gia thực thụ.
Phần 1: Giải mã LLM - Máy đoán từ hay Kho tri thức?
Nhiều người lầm tưởng LLM (Large Language Model) là một bộ bách khoa toàn thư biết hết mọi thứ. Đây là một sai lầm nghiêm trọng. Về mặt kỹ thuật, LLM không phải là cơ sở dữ liệu - nó là một Mô hình xác suất (Probabilistic Model), một "máy đoán từ" cực kỳ tinh vi.
Khi bạn hỏi: "Thủ đô của Pháp là..."
LLM không "biết" Paris là thủ đô. Nó chỉ tính toán rằng: Dựa trên hàng tỷ văn bản nó đã đọc, từ có xác suất xuất hiện cao nhất tiếp theo là "Paris" (99.9%).
Parametric vs. Non-Parametric Memory
Các nhà nghiên cứu chia trí nhớ AI thành 2 loại:
1. Parametric Memory (Trí nhớ tham số): Kiến thức được "nung" (baked) vào trong các trọng số (weights) của mạng neural trong quá trình training. Đây là trí nhớ nội tại của LLM.
2. Non-Parametric Memory (Trí nhớ phi tham số): Kiến thức nằm ở nguồn dữ liệu bên ngoài (Database, Internet) mà model có thể tra cứu.
LLM thuần túy chỉ có Parametric Memory. Và trí nhớ này có 3 giới hạn vật lý không thể vượt qua.
Phần 2: Tam giác giới hạn của LLM

1. Ảo giác (Hallucination) - Sự sáng tạo không đúng lúc
Vì LLM là máy đoán từ, nên khi nó không biết câu trả lời, nó sẽ... đoán bừa. Nó ưu tiên sự lưu loát (Fluency) hơn là sự thật (Factuality). Điều đáng sợ là nó đoán bừa với giọng văn cực kỳ tự tin, khiến người dùng không có cách nào phân biệt được đâu là sự thật, đâu là bịa đặt.
Quay lại vụ luật sư Steven Schwartz mà tôi đề cập ở đầu bài: khi được hỏi về các án lệ, ChatGPT không trả lời "Tôi không biết". Thay vào đó, nó tự tin liệt kê tên vụ án, số hiệu, năm xét xử, thậm chí cả tóm tắt nội dung - tất cả đều hoàn toàn bịa đặt. Vụ "Varghese v. China Southern Airlines" nghe có vẻ rất thật, nhưng nó chưa bao giờ tồn tại trong lịch sử tư pháp Hoa Kỳ.
Đây không phải lỗi, đây là tính năng (Feature). Khả năng "sáng tạo" này giúp LLM làm thơ, viết truyện, brainstorm ý tưởng. Nhưng trong doanh nghiệp - nơi cần sự chính xác tuyệt đối - nó là thảm họa chờ xảy ra.
2. Lỗi thời (Knowledge Cutoff)
Mọi LLM đều có "ngày hết hạn" - thời điểm mà dữ liệu training dừng lại. Hôm nay bạn hỏi về tin tức tuần trước, giá cổ phiếu sáng nay, hay kết quả trận bóng tối qua - nó chịu chết. Tệ hơn, thay vì thừa nhận "Tôi không biết", nó có thể tự tin đưa ra thông tin cũ hoặc bịa đặt hoàn toàn.
Trí nhớ tham số là Tĩnh (Static). Một khi model được train xong, kiến thức của nó bị đóng băng. Muốn cập nhật? Bạn phải train lại toàn bộ - một quá trình tốn hàng triệu USD và nhiều tuần chạy GPU.
3. Mù thông tin nội bộ (Lack of Private Knowledge)
LLM được train từ dữ liệu Internet công khai. Điều này có nghĩa là nó hoàn toàn "mù" với mọi thông tin nội bộ của tổ chức bạn:
- Báo cáo tài chính quý vừa rồi của công ty bạn.
- Lịch sử giao dịch và email của khách hàng.
- Quy trình vận hành nội bộ và SOP của từng phòng ban.
- Kiến thức chuyên môn đặc thù của ngành (domain expertise).
Đây chính là lý do tại sao bạn không thể lấy ChatGPT "out of the box" và mong nó trở thành chuyên gia tư vấn cho doanh nghiệp của mình.
Phần 3: Giải pháp - Fine-tuning hay RAG?
Khi đối mặt với các giới hạn này, chúng ta có 2 con đường.
Con đường A: Fine-tuning (Học thêm)
Chúng ta lấy dữ liệu riêng, train tiếp model (Fine-tuning).
- Ẩn dụ: Bắt học sinh học thuộc lòng thêm 100 cuốn sách giáo khoa mới trước khi đi thi.
- Nhược điểm:
- Tốn kém: Train tốn GPU.
- Chậm: Mỗi khi có dữ liệu mới (ví dụ giá vàng đổi hàng ngày), lại phải train lại? Bất khả thi.
- Khó kiểm soát: Vẫn có thể bị ảo giác.
Con đường B: RAG (Retrieval-Augmented Generation) - Thi đề mở
Chúng ta không bắt model học thuộc. Chúng ta cho phép nó mang tài liệu vào phòng thi.
- Quy trình:
1. User hỏi.
2. Hệ thống tìm kiếm (Retrieve) tài liệu liên quan từ Database.
3. Hệ thống đưa tài liệu + câu hỏi cho LLM.
4. LLM trả lời dựa trên tài liệu đó.
Đây là giải pháp thắng thế hiện nay. Nó rẻ, nhanh, cập nhật thời gian thực (chỉ cần update DB), và minh bạch (có thể trích dẫn nguồn).
Phần 4: Tại sao RAG "thường" (Vector) vẫn chưa đủ?
Hầu hết các hệ thống RAG hiện nay dùng Vector Search - tìm kiếm dựa trên sự tương đồng ngữ nghĩa giữa câu hỏi và tài liệu. Nghe có vẻ thông minh, nhưng Vector Search có một giới hạn mà chúng ta sẽ phân tích kỹ ở Bài 1: hiện tượng "Làm phẳng ngữ nghĩa" (Semantic Flattening).
Nó giống như việc bạn tìm kiếm trong thư viện bằng cách... ngửi mùi sách. Bạn có thể tìm thấy những cuốn sách "có mùi giống nhau" (chủ đề liên quan), nhưng bạn không thể tìm thấy chính xác "cuốn sách màu đỏ nằm bên phải cuốn sách màu xanh".
Chúng ta cần một cấu trúc dữ liệu giữ được mối liên kết logic. Chúng ta cần Knowledge Graph.

Phần 5: Góc độ Kinh tế (Business Value)
Tại sao sếp bạn nên quan tâm đến chuyện này? Hãy để tôi nói bằng ngôn ngữ mà C-level hiểu: tiền và rủi ro.
Chi phí đào tạo vs. Chi phí truy xuất:
Fine-tuning một model như Llama-2-70B tốn hàng nghìn đến hàng chục nghìn USD tiền GPU, mất vài ngày đến vài tuần, và phải làm lại mỗi khi có dữ liệu mới. Trong khi đó, xây dựng hệ thống RAG với vector database hoặc knowledge graph có chi phí khởi tạo thấp hơn nhiều, và quan trọng hơn - dễ dàng cập nhật theo thời gian thực.
Rủi ro pháp lý - Những bài học đắt giá:
- Air Canada (2024): Chatbot của hãng bịa ra chính sách hoàn tiền cho khách hàng có người thân qua đời. Khi khách hàng yêu cầu được áp dụng chính sách này, Air Canada từ chối với lý do "chatbot là một thực thể pháp lý riêng biệt". Tòa án British Columbia không chấp nhận và buộc hãng phải bồi thường. Bài học: Công ty chịu trách nhiệm cho những gì AI của họ nói.
- Luật sư New York (2023): Như đã đề cập, luật sư bị phạt 5,000 USD vì cite án lệ do ChatGPT bịa ra. Đây chỉ là tiền phạt - thiệt hại về uy tín nghề nghiệp còn lớn hơn nhiều.
GraphRAG giảm thiểu rủi ro như thế nào?
Thay vì để LLM "sáng tạo" câu trả lời, GraphRAG ép buộc nó phải bám sát vào các sự thật (Facts) đã được kiểm chứng trong Knowledge Graph. Mỗi câu trả lời đều có thể truy xuất nguồn gốc (traceable), giúp doanh nghiệp audit và chịu trách nhiệm cho thông tin mà AI cung cấp.
Lời kết
Bài 0 này là nền tảng tư duy cho cả series.
Chúng ta không dùng GraphRAG vì nó "thời thượng". Chúng ta dùng nó vì đó là cách duy nhất để khắc phục những khiếm khuyết sinh học của các "bộ não điện tử" LLM.
- LLM cần Trí nhớ (Memory).
- RAG cung cấp Sách vở (Documents).
- Graph cung cấp Mục lục và Logic (Structure).
Hãy cùng bắt đầu hành trình xây dựng bộ não hoàn chỉnh này. Hẹn gặp lại các bạn ở Bài 1, nơi chúng ta sẽ đi sâu vào sự khác biệt kỹ thuật giữa Vector và Graph.