Bench LLM trên DGX Spark: khi memory mới là bottleneck, không phải compute
54 cell benchmark thật trên GB10 128GB. MoE thắng dense 2.5x throughput, long-input giết server, KV cache là constraint thực sự - và 5 điều mình không đoán trước được khi mở terminal.
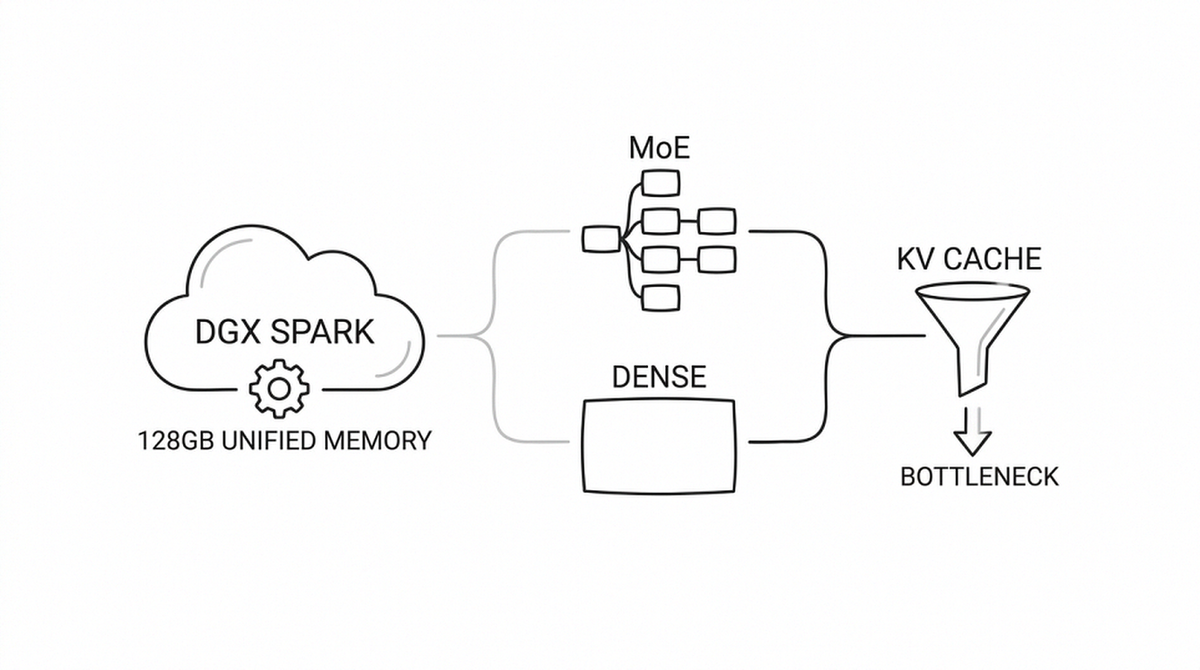
Cuối tuần trước mình ngồi đọc lại một cái bench cell mới chạy xong. Workload tên random - tức là input synthetic 6000 token, output 512 token, ép vào server với 64 user đồng thời. Trên dòng p99_ttft_ms mình thấy một con số: 299610.
Mình tự đọc lại lần thứ hai. 299 nghìn 610. Đó là mili giây. Tức là 300 giây - 5 phút - để user thấy token đầu tiên hiện ra trên màn hình.
Hardware đang bench không phải con máy đời tống. Nó là NVIDIA DGX Spark - một thiết bị 128 GB unified memory, GB10 Grace Blackwell, driver 580.142, CUDA 13. Chạy vLLM phiên bản 26.04 với model Qwen3.6-27B FP8. Trên giấy tờ là một con máy "production-ready". Trong thực tế, ép nó 64 user với prompt 6K input thì user đợi 5 phút mới thấy chữ đầu.
Mình đã chạy 54 cell benchmark trên thiết bị này trong vài ngày. Cuối quá trình, có một điều mình tin gần như chắc chắn: DGX Spark không phải là "AI PC mini". Nó là một thiết bị memory-rich, compute-modest - và nếu bạn deploy LLM trên nó theo cách bạn deploy trên A100, bạn đang tối ưu cho hardware sai.
Bài này là cuộc đo đó. Mình sẽ kể lại 5 thứ mình không đoán trước được, kèm theo những con số đủ cụ thể để bạn có thể chất vấn nếu thấy chỗ nào không hợp lý.
Trước khi đi vào số: hiểu cái máy này thực sự là gì
DGX Spark trông như một cái Mac mini. Bên trong là một con SoC tên là GB10 Grace Blackwell - một CPU ARM Grace + một GPU Blackwell + 128 GB LPDDR5X unified memory. Cả CPU và GPU đều truy cập cùng một pool RAM, không có PCIe transfer giữa hai bên.
Điều này nghe rất tiện - bạn load một model 30B FP8 (~30 GB weights) vào, vẫn còn gần 100 GB cho KV cache. Trên một con A100 80GB, bạn phải tính từng GB. Trên Spark, dường như bạn có thoải mái dư.
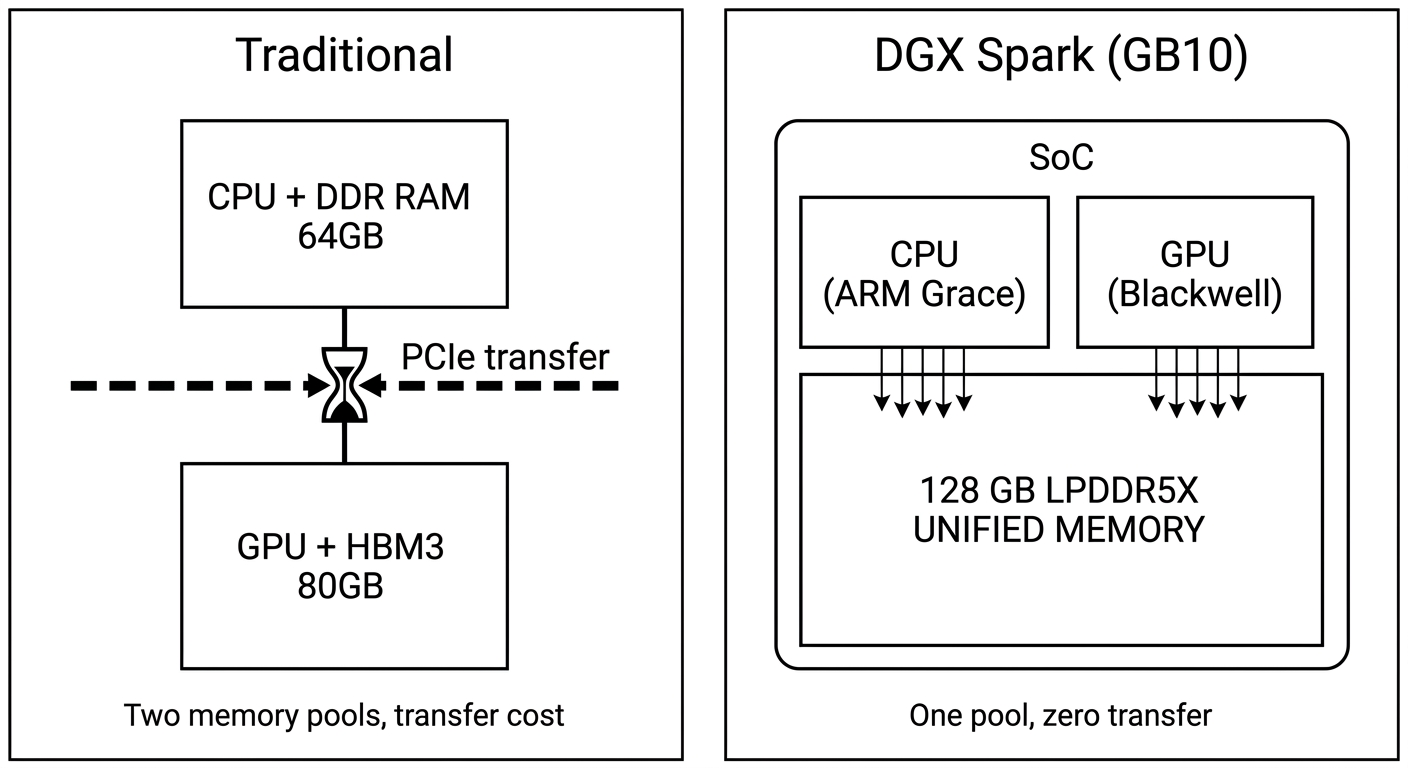
Nhưng đây là chỗ mình hiểu sai từ đầu. Unified memory không có nghĩa là compute mạnh. GB10 dùng GDDR/LPDDR thay vì HBM3. Memory bandwidth thấp hơn HBM một bậc, và compute throughput cũng thuộc tier "workstation" chứ không phải "data center". Trong toàn bộ benchmark dưới đây, compute peak thực tế đo được chỉ khoảng 1100 token/giây tổng (cả prefill lẫn decode) - đó là điểm sát hạch.
Để dễ hình dung, theo các public benchmark, một H100 SXM5 đơn lẻ trên model tương đương đẩy được vài nghìn tok/s tổng - tức là gấp khoảng 3-5 lần Spark. Đổi lại, Spark giá rẻ hơn ~30 lần, kích thước nhỏ hơn 50 lần, và tiêu thụ điện ~140W thay vì 700W.
Đây là một thiết bị "đủ dùng cho team nhỏ" chứ không phải "thay thế data center". Phần lớn các bất ngờ mình gặp khi bench đều xuất phát từ chỗ mình quên mất chi tiết này.
Cái mình bench: 3 model, 7 workload, 54 cell
Stack chạy như sau:
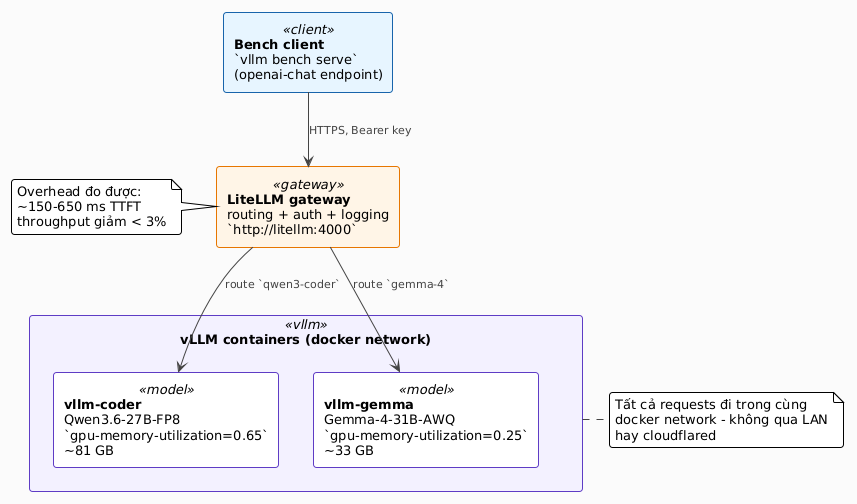
3 model được bench:
| Model | Loại | Kích thước weights | Active params | Quantization |
|---|---|---|---|---|
| Qwen3.6-27B-FP8 | Dense | 27B | 27B | FP8 |
| Qwen3-Coder-30B-A3B AWQ | MoE | 30B | 3B | AWQ (INT4) |
| Gemma-4-31B AWQ | Dense | 31B | 31B | AWQ (INT4) |
7 workload, mô phỏng 7 dạng traffic khác nhau:
| Tag | Input shape | Output shape | Đại diện gì |
|---|---|---|---|
sharegpt |
200-512 tok | 256 tok | Chat ngắn, Q&A |
balanced1k1k |
1024 tok | 1024 tok | RAG, long-form |
random |
6000 tok | 512 tok | Code completion, repo-question |
longout |
128 tok | 2048 tok | Creative writing, agent reply |
longin |
8192 tok | 256 tok | Document summarization |
sharegpt-think |
giống sharegpt | 1024 tok | Chat có bật reasoning |
sustained-c32 |
sharegpt @ c=32 | 300 prompt | Stability check |
Mỗi workload chạy với concurrency 1, 4, 8, 16, 32, 64 (cộng thêm 2, 12, 24, 48 cho cell fine-grained). 54 cell tổng.
Số đo mình quan tâm: - TTFT (Time To First Token) - bao lâu user thấy token đầu - ITL (Inter-Token Latency) - khoảng cách giữa 2 token liên tiếp khi đang stream - Output throughput - tổng token/giây output (KPI chính) - E2E latency - tổng thời gian một request
Và đây là chỗ bài này bắt đầu thú vị.
Phép đo 1: Shape của workload, không phải size của model, mới quyết định throughput
Cùng một model (Qwen3.6-27B FP8). Cùng một server. 5 workload khác nhau. Đây là throughput output:
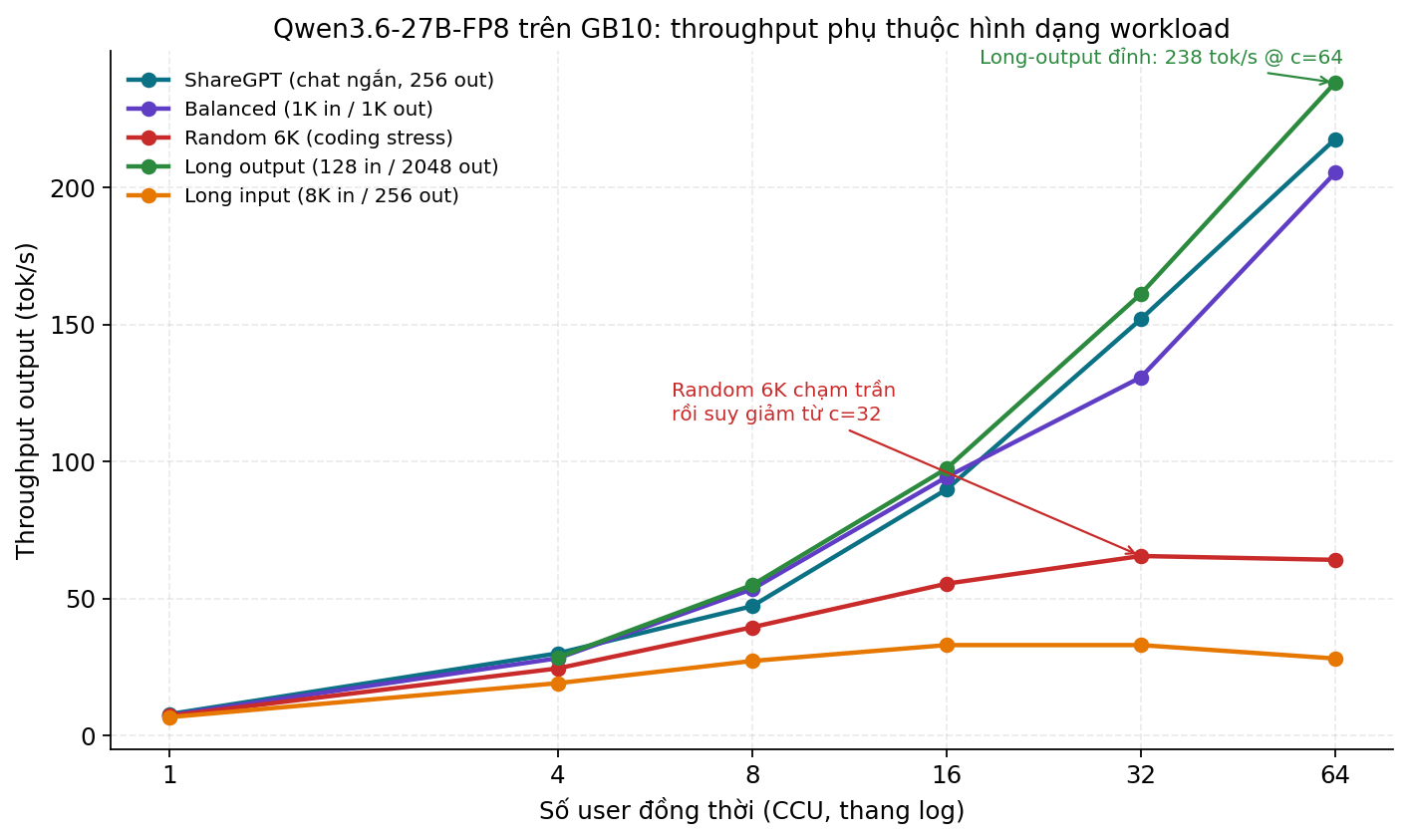
Đọc kỹ cái biểu đồ này một chút. Tại c=32 (số user đồng thời): - Long output (input 128, output 2048): 161 tok/s - ShareGPT (input 200-512, output 256): 152 tok/s - Balanced (input 1K, output 1K): 131 tok/s - Random 6K (input 6K, output 512): 65 tok/s - Long input (input 8K, output 256): 33 tok/s
Cùng phần cứng, cùng số user, chênh lệch gần 5 lần giữa workload tốt nhất và tệ nhất.
Để bạn không phải tin lời mình, đây là raw JSON output gốc cho cell ShareGPT c=64. Tất cả con số 217 tok/s và TTFT p99 11.8s trong bài này đều lấy từ file này, không có chỉnh sửa:
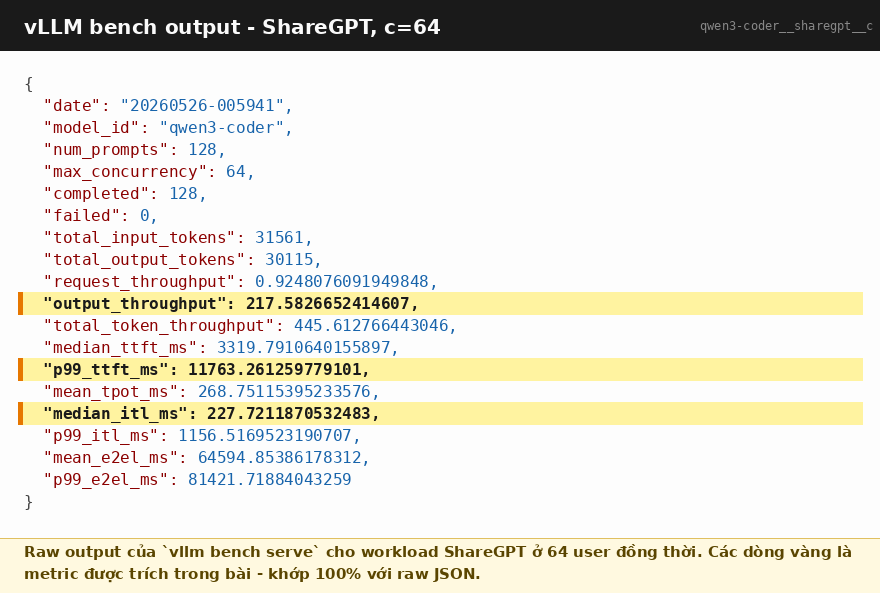
Mình tưởng throughput của một LLM server phụ thuộc vào model size và CCU. Hoá ra không. Throughput phụ thuộc gần như tuyệt đối vào tỉ lệ input/output của workload, vì:
- Prefill (xử lý prompt) là compute-bound, scale tuyến tính với độ dài input.
- Decode (sinh token) là memory-bandwidth-bound, scale với batch size.
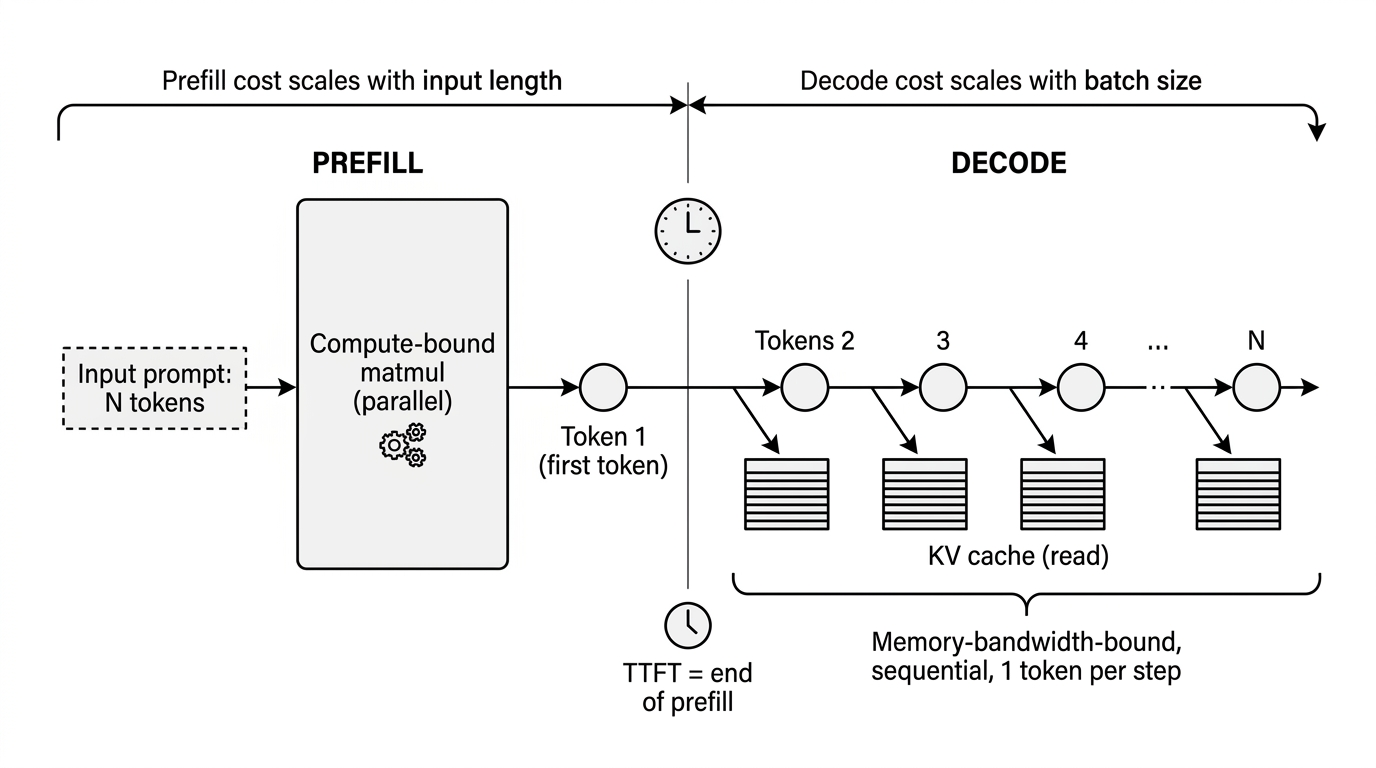
Workload có input dài (random 6K, long-input 8K) đốt phần lớn compute vào prefill. Workload có output dài (long-output 2048) hầu như chỉ làm decode - và decode là cái GB10 làm tốt hơn (vì memory unified, KV cache đọc nhanh).
Hệ quả vận hành: nếu nói "DGX Spark serve được X user" thì câu nói đó vô nghĩa. Phải hỏi: serve loại traffic nào. Một con server serve 64 chat-bot ngắn thoải mái, đẩy nó vào RAG với prompt 8K thì 16 user là gãy.
Phép đo 2: Long input là kẻ giết throughput thực sự
Phép đo này là cú sốc lớn nhất với mình. Nhìn TTFT p99 - tức là thời gian user thấy token đầu tiên, ở mức percentile 99 (1% user xấu nhất):
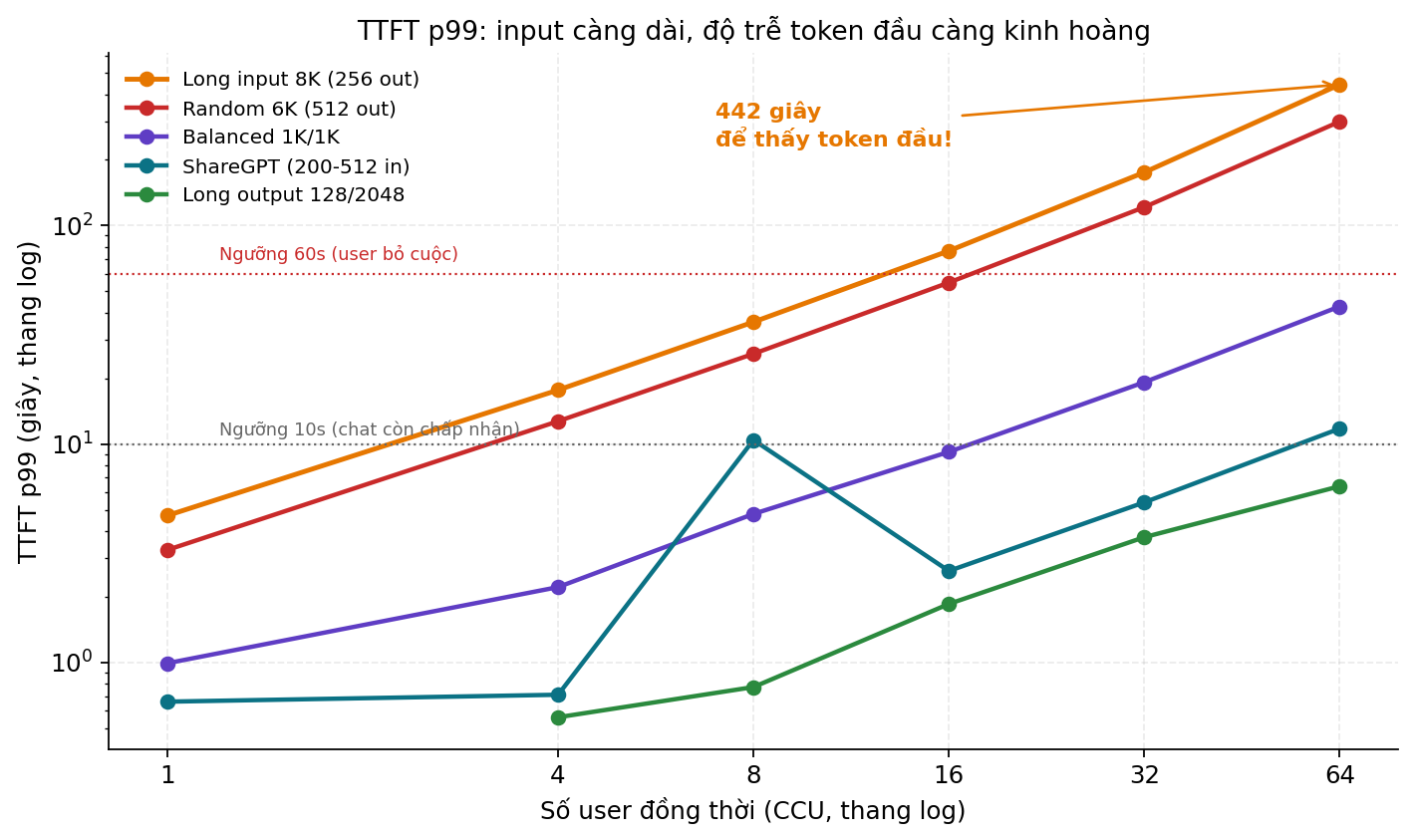
Tại c=64: - ShareGPT (input ngắn): 11.8 giây - khó chịu nhưng còn chấp nhận - Long output (input 128): 6.4 giây - tốt nhất trong nhóm - Balanced (input 1K): 43 giây - đã không ổn - Random 6K: 300 giây - 5 phút - Long input 8K: 442 giây - 7 phút 22 giây
7 phút 22 giây để user thấy token đầu tiên. Không một user thực nào chấp nhận điều này.
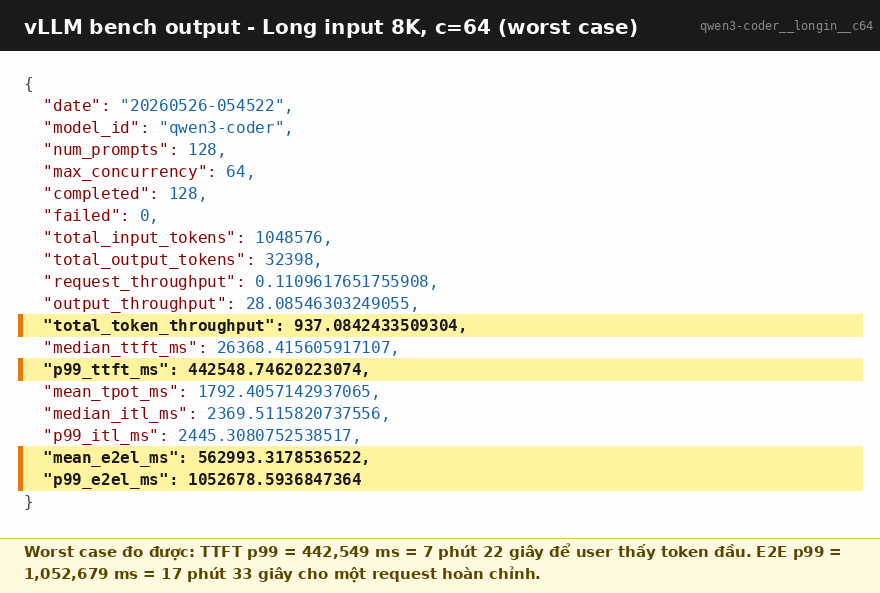
Vì sao? Vì prefill là compute-bound và không tránh được. Khi 64 user gửi prompt 8K cùng lúc, server phải xử lý 64 × 8192 = 524 288 token input. Với throughput tổng peak khoảng 1100 tok/s, riêng prefill batch đầu tiên đã mất ~8 phút.
Đây không phải bug của vLLM. Đây là vật lý của hardware. Spark đơn giản không có đủ compute để prefill song song 64 prompt dài như vậy. Bạn phải xếp hàng, và cái hàng đó dài bằng phút.
Implication: nếu service của bạn có long-context (RAG với 8K prompt, code review nguyên file), capacity thực tế của Spark thấp hơn nhiều so với khi bạn benchmark bằng chat ngắn. Mình sẽ không tin một con số "Spark serve được X user" nếu người nói không kèm theo distribution input length.
Phép đo 3: MoE thắng dense 2.5x - nhưng có một cái deal Faustian
Trong report có một thí nghiệm thú vị: sau khi bench Qwen3.6-27B-FP8 (dense), team rollback route qwen3-coder về một model khác - Qwen3-Coder-30B-A3B-Instruct AWQ. Đây là MoE: 30B param tổng, nhưng chỉ 3B active mỗi forward pass (8 expert trong tổng số ~128, mỗi token chỉ kích hoạt 8 cái).
Cùng workload balanced 1024/1024. Cùng hardware. Đây là kết quả:
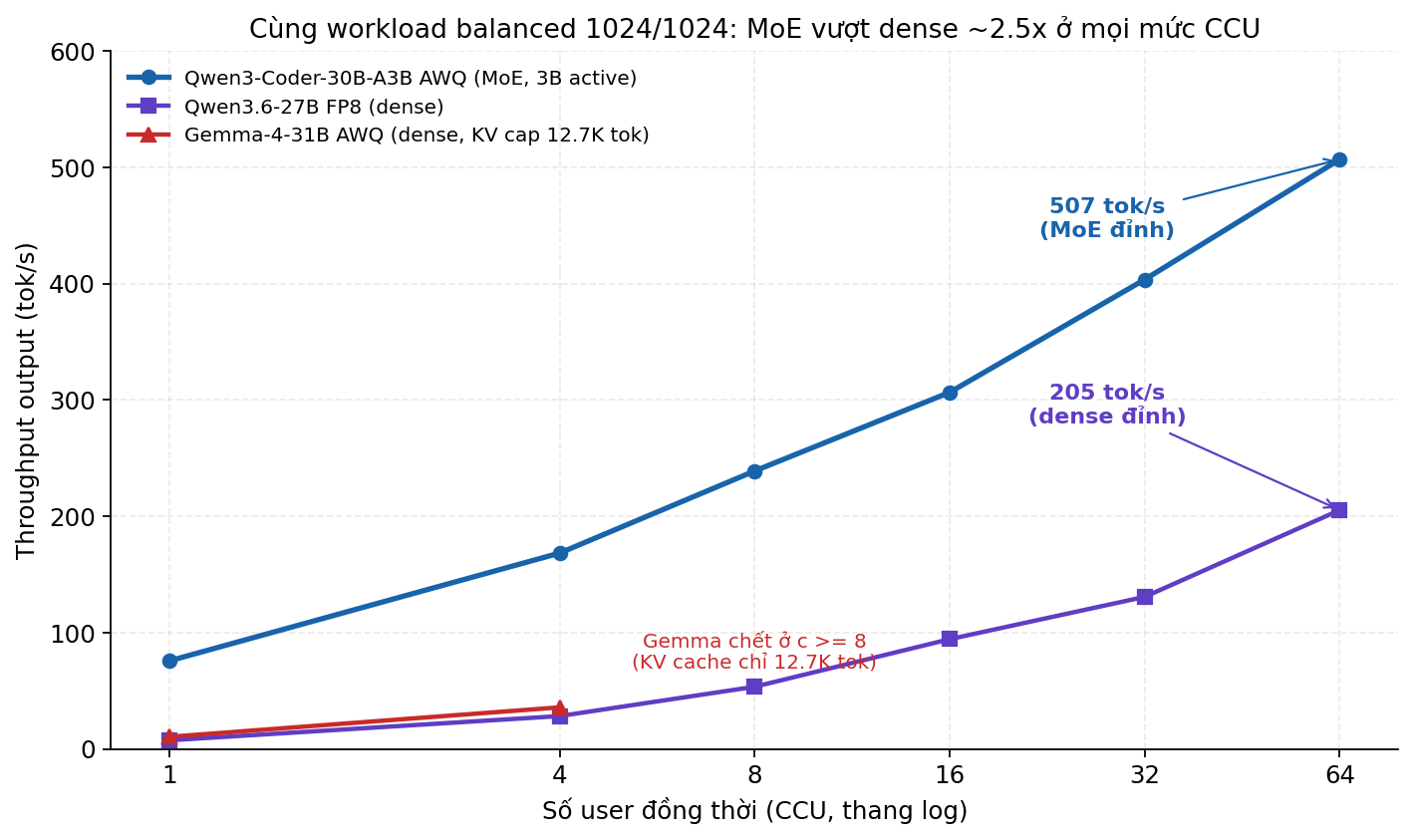
Tại c=64: - Dense FP8: 205 tok/s output. TPOT 297ms. E2E mean 302 giây. - MoE AWQ: 507 tok/s output. TPOT 123ms. E2E mean 127 giây.
507/205 = 2.47x throughput. TPOT giảm 58%. E2E giảm 58%. User thấy response xong nhanh hơn 2.5 lần.

Lý do thì hợp logic: mỗi forward pass dense phải activate toàn bộ 27B parameter. MoE chỉ activate 3B (8 expert). Compute giảm khoảng 9 lần trên giấy tờ - và Spark, vốn compute-modest, hưởng lợi nhiều hơn so với một H100 nơi compute thừa thãi.
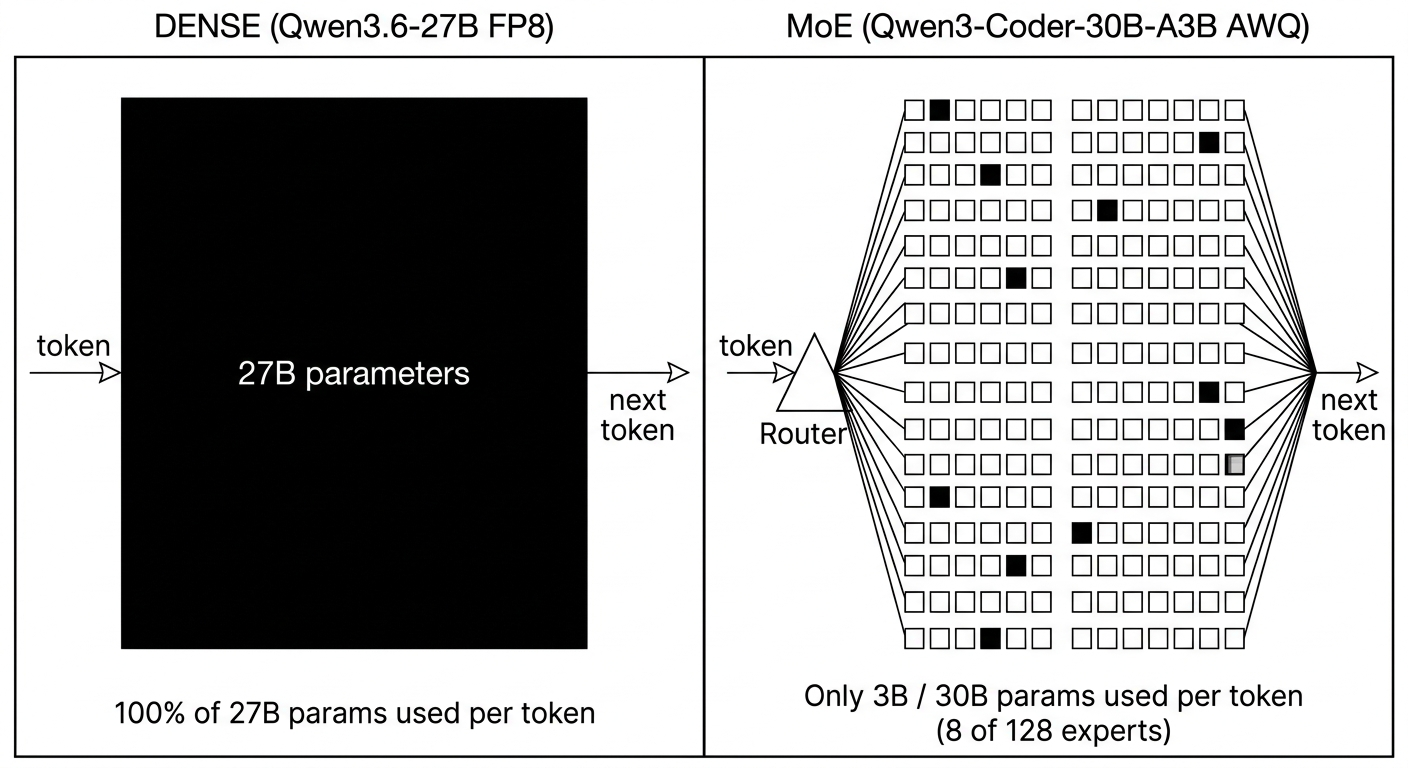
Đây là điểm mình thấy đẹp nhất của bench này: trên hardware compute-modest, MoE không chỉ là "model architecture mới", nó là kiến trúc bắt buộc nếu muốn throughput tử tế.
Nhưng có một cái catch mà mình không thể bỏ qua. Theo model card của hai con này: - Qwen3.6-27B FP8: SWE-bench ~77 - Qwen3-Coder-30B-A3B AWQ: SWE-bench ~65
Quality chênh 16% trên task coding khó. Nếu bạn dùng nó cho code review của một codebase production, 16% sai số là không nhỏ.
Đây là một deal Faustian thực sự. Throughput 2.5x đổi lấy quality -16%. Không có câu trả lời "tốt hơn" tuyệt đối - tuỳ workload. Cho chat-bot phổ thông hoặc autocomplete đơn giản: MoE thắng dễ. Cho code review nghiêm túc hoặc reasoning phức tạp: dense vẫn xứng đáng với cost của nó.
Mình tin rằng MoE sẽ tiếp tục là default cho self-hosted LLM trên hardware modest trong 2026. Nhưng ai đó cần cảnh báo user về cái 16% đó.
Phép đo 4: Gemma chết không phải vì compute, mà vì KV cache
Trong list 3 model mình bench, có một con không xuất hiện ở bảng so sánh ở trên: Gemma-4-31B AWQ. Lý do là vì nó chết trước khi mình có thể bench đầy đủ.
Cụ thể: ở c=8 ShareGPT, container Gemma exit. Không phải crash, không phải OOM kill, không panic. Exit code 0 - "graceful shutdown". Docker auto-restart, mất 110 giây để re-load weights, lúc đó sweep đã chuyển sang cell tiếp theo.
Đây là log boot sau restart:
GPU KV cache size: 12,752 tokens
Maximum concurrency for 32,768 tokens per request: 2.41x
12,752 tokens. Đó là toàn bộ KV cache budget của Gemma.
Để dễ hình dung: một request balanced 1K/1K cần 2048 token KV. 12,752 / 2048 = 6 request đồng thời. Một request random 6K input cần ~6500 token. 12,752 / 6500 = gần đúng 2 request.
Khi c=8 ShareGPT ăn vào ~4-6K token (8 user × 500-768 tok/req), Gemma chạm trần, vLLM trigger preemption, và engine tự shutdown. Đây không phải bug. Đây là budget đã được set bởi gpu-memory-utilization=0.25.
Vì sao chỉ 0.25? Vì cả 3 model phải chia sẻ 128 GB unified memory:
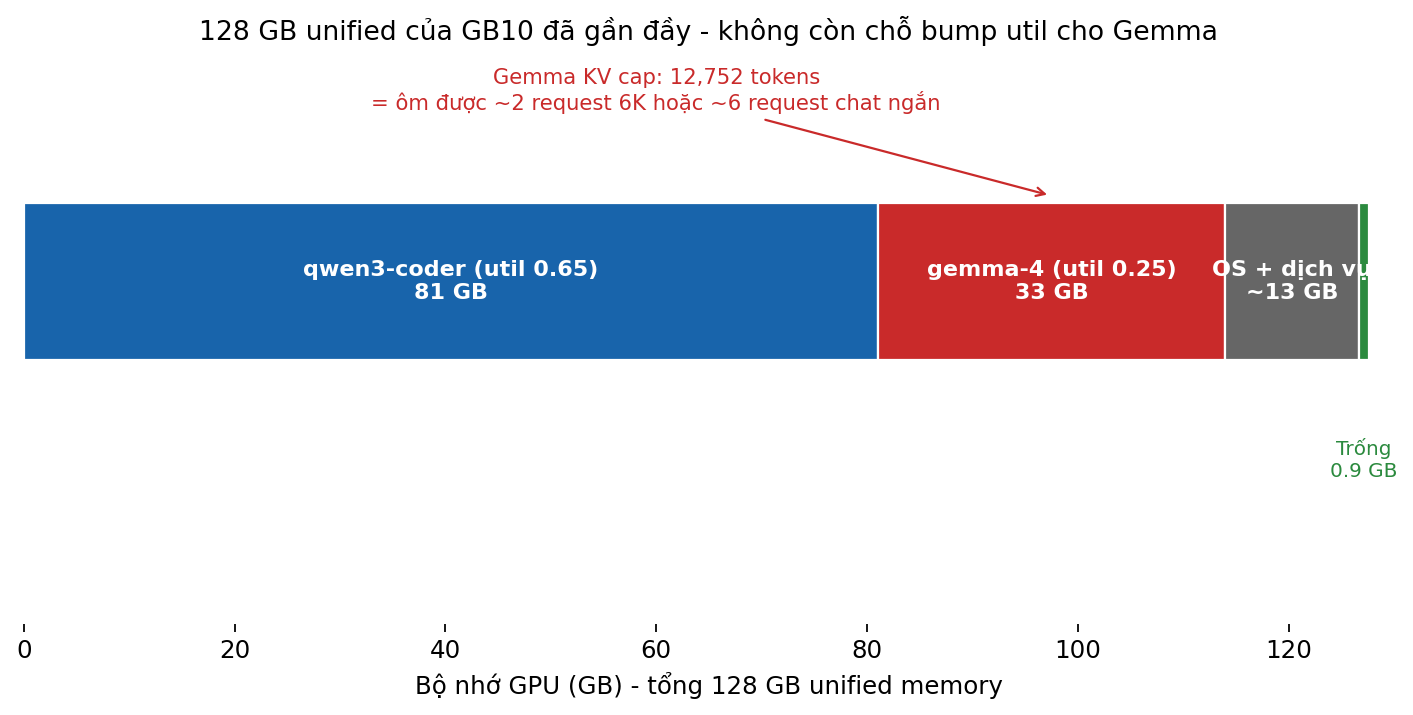
81 GB cho qwen3-coder, 33 GB cho gemma, ~13 GB cho OS + docker + services khác. Còn lại 0.9 GB free. Muốn bump Gemma từ 0.25 lên 0.45 cần thêm 25 GB - không tồn tại.
Đây là một sự thật ít người nói: trên thiết bị "memory-rich" như Spark, KV cache budget mới là constraint thật sự, không phải compute và không phải weights. Một con MoE 30B chỉ active 3B param vẫn cần KV cache đầy đủ cho 30B param × số layer × seq_len - và đó là chỗ memory đi.
Khi bạn benchmark một LLM server, đừng chỉ hỏi "model size bao nhiêu". Hỏi: với gpu-memory-utilization này, KV cache cap là bao nhiêu token? Và bao nhiêu request đồng thời thì chạm trần?
Đó là con số quyết định Gemma chạy được 4 CCU hay 40 CCU. Trên Spark hiện tại, câu trả lời là 4.
Phép đo 5: Thinking mode ăn 4x compute - mà bạn không thấy được
Qwen3 có cái flag enable_thinking=true - bật thì model sẽ sinh ra một đoạn chain-of-thought (CoT) ẩn trước, rồi mới sinh response thực sự cho user. CoT đi qua field reasoning_content trong OpenAI streaming, không phải content.
Mình bench cả hai mode trên cùng workload ShareGPT 256 out. Kết quả:
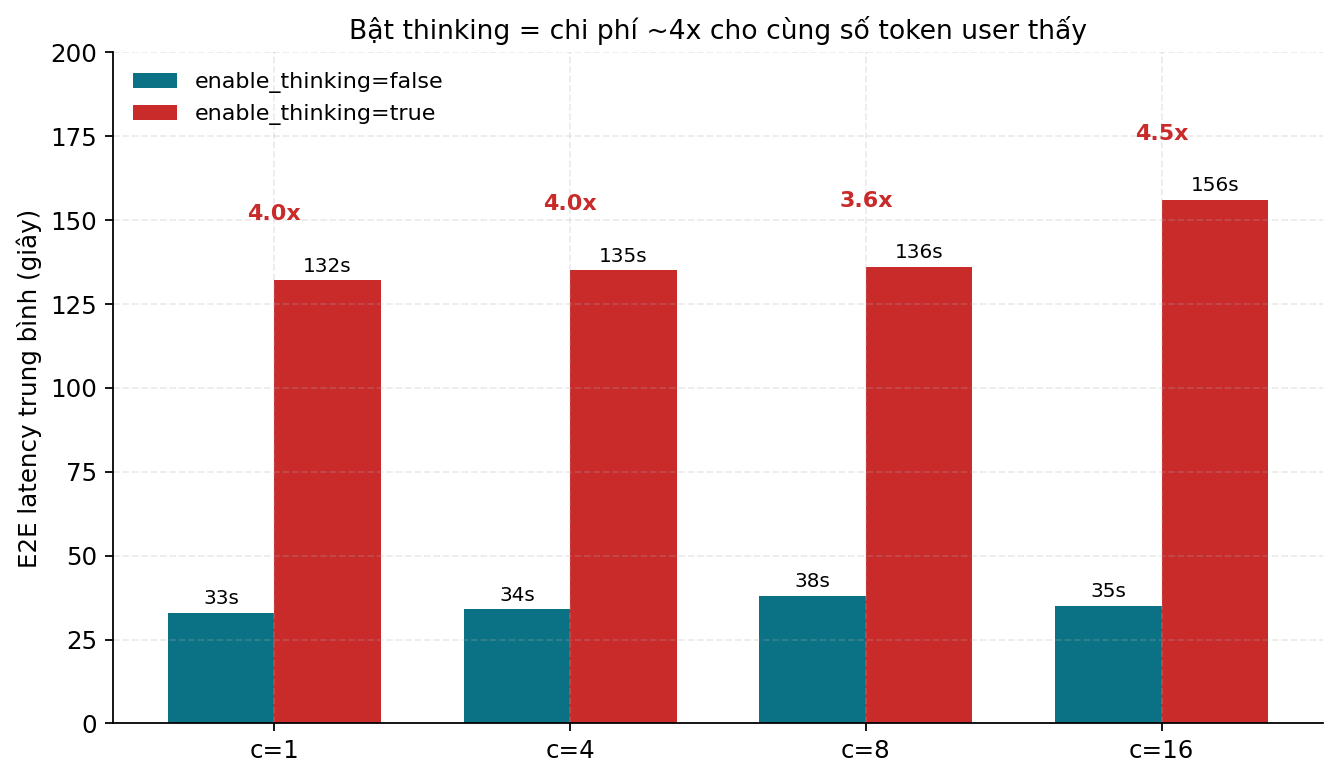
E2E mean ở c=1: - enable_thinking=false: 33 giây - enable_thinking=true: 132 giây
4x latency. Cho cùng số token mà user nhìn thấy.
Tại sao? Vì model thực sự sinh ra ~1000 token CoT + 256 token response = ~1256 token tổng cho mỗi request. ITL không thay đổi (vẫn 128-136ms). Model không chậm hơn. Nó chỉ phải sinh nhiều hơn.
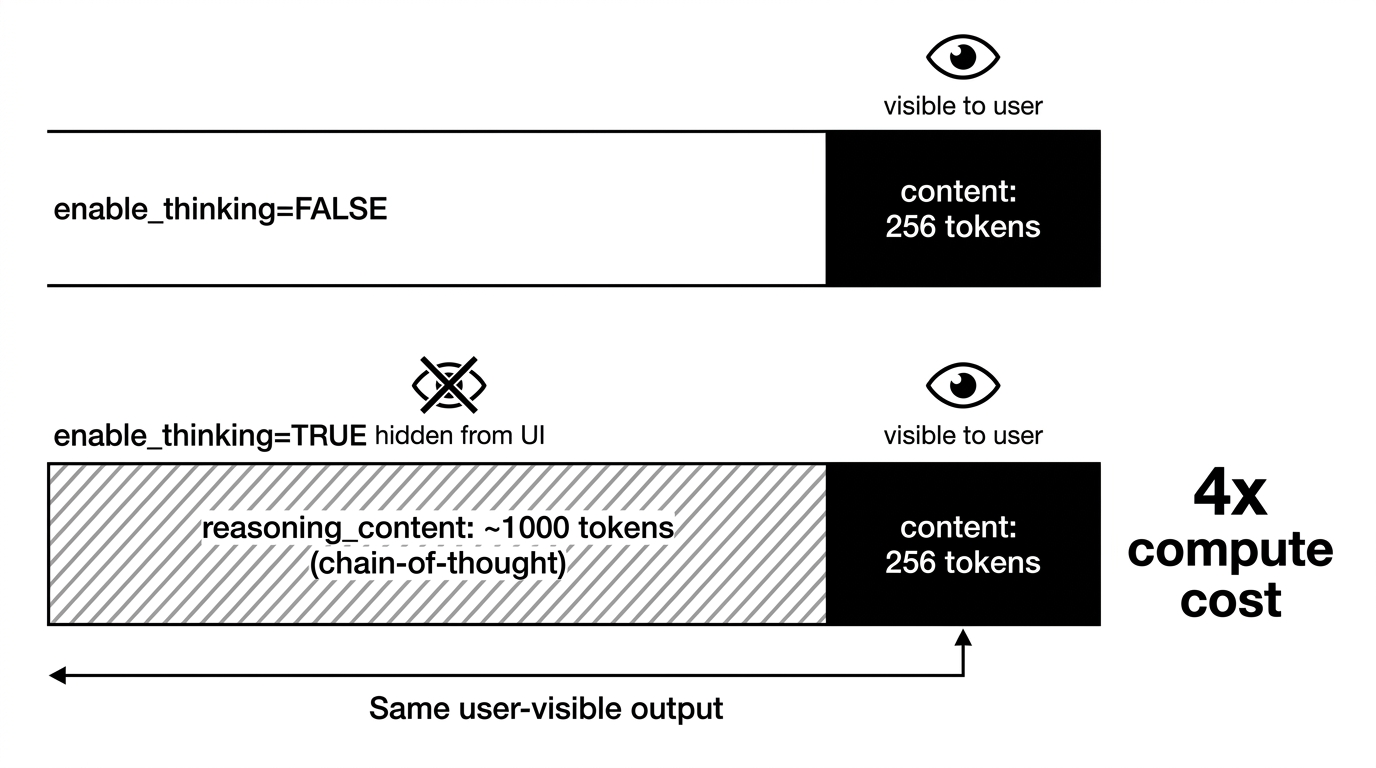
Đây là cái mình nghĩ nhiều product không gọi tên rõ. Khi user toggle "Thinking mode" trên UI, họ không nhận thức là họ vừa giảm capacity của server xuống 1/4. Nếu trước đó server serve được 64 CCU, bật thinking thì chỉ còn 16. Latency p99 nhảy từ 12 giây lên gần 1 phút.
Mình nghĩ UI nên hiện một cái warning kiểu "Thinking mode = chậm hơn 4x. Bạn vẫn muốn bật không?" Không phải để giáo dục user về kiến trúc. Mà để user không tưởng server bị lag.
Phép đo 6 (bonus): mỗi user lẻ chậm dần, nhưng tổng vẫn tăng
Đây là phép đo mình thấy đẹp nhất về mặt mental model. Bench ShareGPT fine-grained với 10 mức concurrency (c=1, 2, 4, 8, 12, 16, 24, 32, 48, 64):
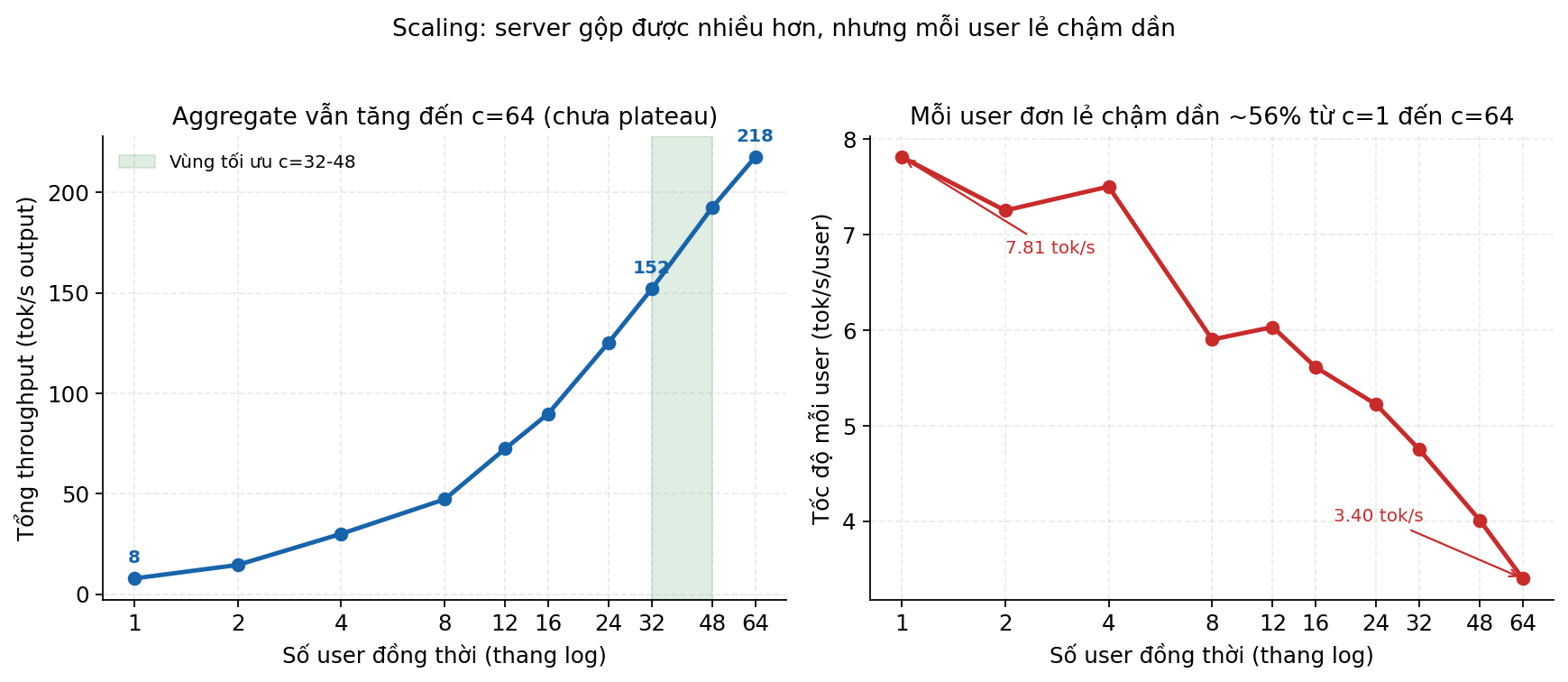
Bên trái: tổng throughput đi từ 7.8 tok/s (c=1) lên 218 tok/s (c=64). Tăng 28 lần.
Bên phải: tốc độ mỗi user lẻ đi từ 7.81 tok/s (c=1) xuống 3.40 tok/s (c=64). Giảm 56%.
Đây là hai sự thật cùng tồn tại: 1. Server gộp được nhiều user hơn khi tăng concurrency (batching efficiency). 2. Nhưng mỗi user cảm thấy chậm hơn vì phải chia sẻ slot trong batch.
Sweet spot trên đường cong này là c=32-48. Sau c=48, mỗi 1% throughput đổi lấy 2-3% per-user latency. Knee point thực sự.
Đây là chỗ mà phần lớn các "capacity plan" sai lầm. Người ta nhìn aggregate và bảo "server chịu được 64 user". Người ta quên rằng ở c=64, mỗi user nhận stream chậm hơn 56% so với c=1. User đầu tiên thấy 7.8 tok/s ("nhanh!"), user thứ 64 thấy 3.4 tok/s ("như chat với GPT-3 hồi 2022"). Cùng một server.
Lesson: capacity của LLM server không phải một con số đơn. Nó là một đường cong, và bạn phải đặt cả người dùng và CFO của bạn ở đâu đó trên đường cong đó - không phải ở 2 đầu.
Cấu hình sau khi đo: ai chạy được gì, không chạy được gì
Tổng kết nhanh, từ góc nhìn vận hành:
| Workload | Backend khuyến nghị | CCU "thoải mái" | CCU "stretch" |
|---|---|---|---|
| Chat ngắn (Q&A 256 out) | Qwen3-Coder AWQ MoE | 32-48 | 64 |
| RAG balanced (1K in / 1K out) | Qwen3-Coder AWQ MoE | 32 | 64 |
| Code completion (6K in) | Qwen3.6 dense FP8 hoặc MoE | 8-16 | 32 |
| Creative long output | bất kỳ Qwen | 32 | 64 |
| Document summary (8K in) | Qwen3.6 dense | 8 | 16 |
| Thinking mode bật | bất kỳ Qwen | 1-4 | 16 |
| Production gemma-4 | (chỉ side model) | ~4 | n/a |
Và một số kết luận mà mình nghĩ là transferable:
- LiteLLM gateway gần như miễn phí - overhead ~150-650 ms TTFT, throughput giảm <3%. Lợi ích routing + logging + auth lớn hơn cost.
- Sustained load c=32 stable hoàn toàn - 300 prompt liên tục, không drift, không degradation. TTFT p50 thậm chí cải thiện so với cell ngắn (warm batch tốt hơn cold-start).
- Bench script luôn luôn nói dối nếu không kèm distribution của input/output length - đây là điều mình sẽ áp dụng cho mọi LLM bench sau này.
- 128 GB unified không có nghĩa là dư memory - khi load 2-3 model song song, mỗi GB của KV cache là cuộc chiến.
Kết: cái la bàn mới mình mang ra khỏi cuộc bench này
Mình bắt đầu cuộc đo này với một câu hỏi đơn giản: "Spark có serve được production traffic LLM không?"
Mình tưởng câu trả lời là yes/no. Hoá ra câu trả lời thực sự là "câu hỏi sai".
Câu hỏi đúng có 3 phần: - Workload shape của bạn thế nào? (input/output distribution) - Quality vs throughput, bạn chọn phía nào? (MoE vs dense) - KV cache budget của bạn có đủ cho CCU dự kiến không? (memory layout)
Trả lời được 3 câu đó, bạn có capacity number. Không trả lời được, mọi con số "X CCU" đều là noise.
Cá nhân mình, sau khi xong cuộc đo, sẽ deploy Spark như sau: một model MoE chính (Qwen3-Coder AWQ) chiếm 60-65% memory, một model dense backup nhỏ hơn cho task quality-critical, gemma là "side model" cho low-volume use case không cần concurrency cao. Cấu hình hiện tại của team mình gần với pattern này, và bench confirm rằng nó hoạt động trong phạm vi 30-60 CCU cho traffic chat ngắn.
Nếu bạn đang cân nhắc Spark cho team mình - hoặc bất kỳ thiết bị "AI workstation" nào tương tự - mình muốn nói một điều: đừng tin spec sheet. Hãy chạy 5 workload cơ bản (sharegpt, balanced, longout, longin, random) trên một sweep concurrency 1-64. Mất nửa ngày. Và bạn sẽ biết thiết bị đó thật sự là gì, thay vì cái mà marketing nói nó là.
Đó là tất cả cái mình đã làm. Và đó là cái mình tin một team kỹ thuật nào cũng nên làm trước khi commit production traffic lên một hardware mới.
Nếu bạn cũng đang bench hoặc đã bench LLM trên hardware lạ - mình muốn nghe bạn đo được gì, đặc biệt là chỗ nào bạn ngạc nhiên. Hardware tier modest đang trở thành mainstream nhanh hơn mình dự đoán, và mình tin càng nhiều người chia sẻ data bench thật, càng ít người sau này phải đoán mò.

Bình