Harness Engineering - Buzzword Mới Hay Thật Sự Quan Trọng?
Từ Prompt Engineering đến Harness Engineering - mình mệt với buzzword mới. Nhưng trước khi chửi, mình ngồi đào. Đây là những gì mình tìm được.
Thật ra mình đã cố bỏ qua cái từ này.
Cách đây khoảng ba tuần, mình bắt đầu thấy "Harness Engineering" xuất hiện trên newsfeed - LinkedIn, Twitter, một vài Slack communities mình ở trong đó. Ban đầu mình scroll qua, như thường lệ. Vì mình đã quen với pattern này rồi: ai đó coin một cái tên mới, influencers nhảy vào tung hô, FOMO tràn lan, rồi khoá học mọc lên như nấm sau mưa, mỗi khoá $297 kèm theo certificate và một Discord server "exclusive".
Mình đã sống qua đủ vòng như vậy. Software Engineering. AI Engineering. Vibe Coding. AI Augmented Development. Agentic Software Development. Và bây giờ là Harness Engineering. Mỗi từ đều được đóng gói với một promise rằng đây là kỹ năng của tương lai, rằng ai không học sẽ bị bỏ lại phía sau, rằng chỉ cần $297 kia là bạn đã đi trước đám đông.

Nhưng lần này có gì đó khiến mình không scroll qua được. Một post của LangChain, không phải từ influencer, mà từ team kỹ thuật, chia sẻ kết quả benchmark: chỉ thay harness - không đổi model - và coding agent của họ nhảy từ 52.8% lên 66.5% trên TerminalBench 2.0. Từ Top 30 lên Top 5 trên leaderboard. Cùng một LLM. Chỉ thay phần bọc quanh nó.
Con số đó đủ để khiến mình tạm dừng. Và mình ngồi đào.
Thesis của mình, trước khi đi vào chi tiết
Mình muốn nói thẳng ngay từ đầu để bạn biết bài này đang đi về đâu: Harness Engineering không phải concept mới - nó là systems engineering đã tồn tại từ lâu, được đặt tên lại trong context của AI agents. Nhưng cái concept đằng sau cái tên đó thì thật sự quan trọng, và quan trọng theo cách mà phần lớn các khoá học "$297" sẽ không giải thích cho bạn.
Và cái con số 52.8% → 66.5% kia không phải marketing. Đó là data thật, có thể verify được, và nó phản ánh một insight cốt lõi mà mình sẽ giải thích bên dưới.
Harness là gì - giải thích qua một flow cụ thể
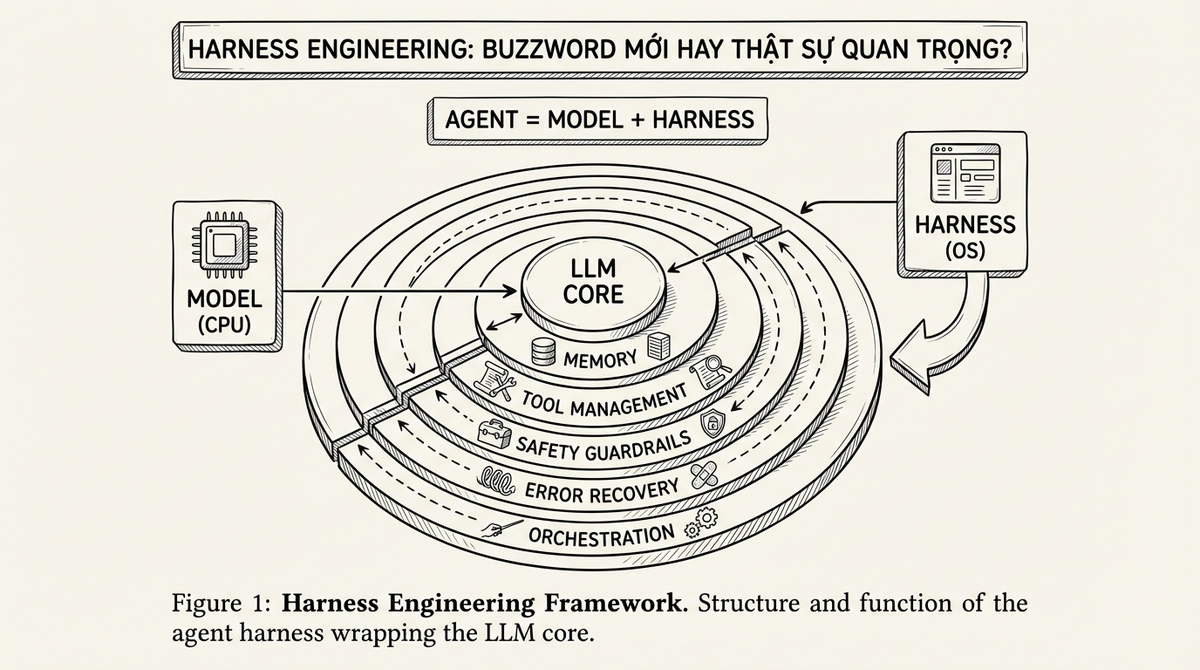
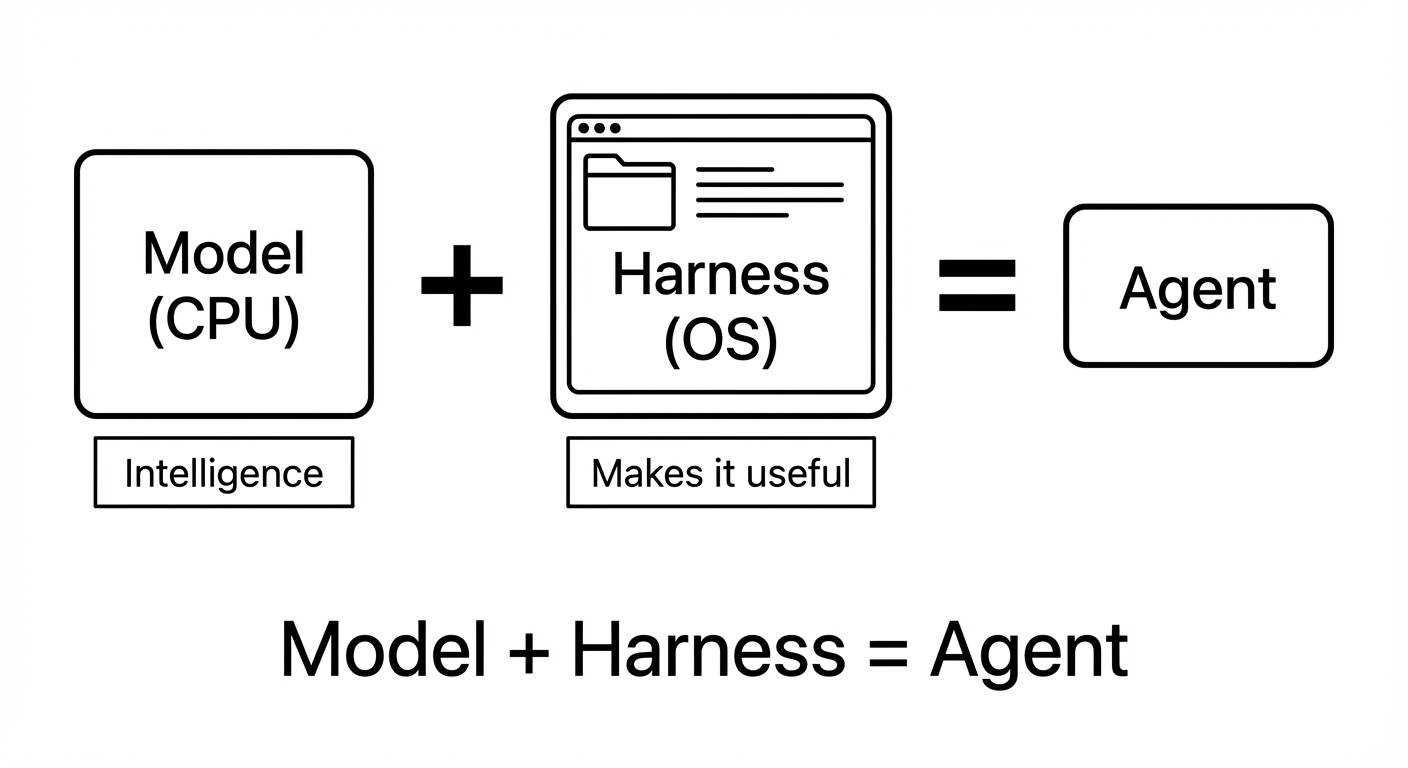
Công thức cơ bản mà LangChain và Anthropic đều dùng là: Agent = Model + Harness.
Model là phần bạn quen thuộc - LLM, cái bộ máy generate text, cái thứ "thông minh". Harness là mọi thứ còn lại, toàn bộ infrastructure bọc quanh model để biến nó thành một agent có thể làm việc thật sự trong thế giới thật.
Một analogy mà mình thấy hữu ích: model là CPU, còn harness là hệ điều hành. CPU mạnh đến mấy, nếu không có OS quản lý memory, schedule processes, handle I/O, cấp phát permissions - CPU đó chỉ là silicon đắt tiền nằm không. Cái sức mạnh của CPU chỉ được hiện thực hóa thông qua OS. Tương tự, cái intelligence của model chỉ được hiện thực hóa thông qua harness.
Để hiểu harness làm gì cụ thể, hãy theo dõi một flow thực tế: bạn gõ "refactor hàm này để thêm error handling" vào Claude Code. Đây là những gì xảy ra - và phần nào là harness, phần nào là model.
Orchestration Layer quyết định flow thực thi. Không phải model tự nghĩ ra "tôi nên đọc file trước, rồi edit, rồi verify". Đó là harness đã encode một agent loop: gather context → take action → verify results, chạy lặp lại cho đến khi task hoàn thành hoặc bị time out. Model generate từng bước trong loop đó, nhưng cái loop là do harness thiết kế.
Context Management quyết định model được nhìn thấy gì. Context window có giới hạn - 200k tokens nghe có vẻ nhiều, nhưng một codebase trung bình đã đủ để làm nổ tung giới hạn đó. Harness quyết định file nào relevant để đọc vào context, compact conversation history khi quá dài, dùng prompt caching để tránh re-process những phần đã đọc rồi. Nếu harness chọn sai, model nhìn vào context không có đủ thông tin và hallucinate. Nếu harness chọn đúng, model làm được việc. Chất lượng của context selection là một trong những yếu tố phân biệt agent giỏi và agent dở - không phải model size.
Tool Management là lớp trung gian giữa model và thế giới thật. Model không thực sự "đọc file" hay "chạy command" - model generate text kiểu read_file("src/main.py"), và harness intercept cái text đó, thực sự đọc file, rồi inject output vào context. Harness maintain một registry các tools, validate parameters trước khi execute (để model không accidentally xoá production database), và sandbox execution để tránh side effects không mong muốn.
Memory Systems giải quyết vấn đề continuity. Model không có memory native - mỗi conversation bắt đầu từ đầu. Harness implement các lớp memory khác nhau: CLAUDE.md là persistent memory được load vào mọi conversation (đó là lý do tại sao Claude Code "nhớ" conventions của project bạn), conversation context là working memory trong session hiện tại, và dynamic retrieval cho phép agent kéo thông tin cũ khi cần. Không có harness thiết kế tốt, agent của bạn bị amnesia mỗi 10 phút.
Safety Guardrails là permission pipeline ngăn agent làm điều sai. Model đề xuất action - "tôi muốn chạy rm -rf /tmp/*" - nhưng harness quyết định có cho phép không, thông qua ba lớp: input validation (có gì bất thường không?), tool permission checks (allow list / deny list / ask list), và output sanitization (kết quả trả về có leak gì không?). Đây là lý do Claude Code hỏi permission trước khi chạy bash commands nguy hiểm - không phải model "biết" phải hỏi, mà là harness enforce behavior đó.
Error Recovery xử lý khi mọi thứ không đi theo kế hoạch. Tool call fail? Harness retry với params khác. API timeout? Route sang fallback. Agent chạy vòng lặp không tiến triển (stuck loop, một pattern phổ biến)? Circuit breaker dừng lại và report lỗi thay vì tiếp tục đốt tokens vô ích.

Sáu components này - orchestration, context management, tool management, memory, safety, error recovery - là harness. Và như bạn thấy, không cái nào liên quan đến việc model "thông minh" hơn. Tất cả là systems engineering.
Bằng chứng: harness thay đổi kết quả thật sự
Quay lại con số 52.8% → 66.5% mà mình đề cập ở đầu. LangChain publish chi tiết trong bài "Improving Deep Agents with Harness Engineering" đầu 2026.
Họ build một framework gọi là Deep Agents trên LangGraph, với một middleware system có 6 hooks intercept execution ở mọi stage của agent loop. Thay đổi quan trọng nhất là LLMToolSelectorMiddleware: thay vì để main model tự quyết định dùng tool nào (vốn rất tốn context), họ dùng một LLM nhỏ hơn và nhanh hơn để pre-filter danh sách tools relevant trước khi gọi main model. Kết quả là main model nhận được một context sạch hơn, ít noise hơn, và ra quyết định chính xác hơn.
Cùng một model. Chỉ thay harness. Từ Top 30 lên Top 5 trên TerminalBench 2.0.

Anthropic publish findings tương tự trong tài liệu về "Effective harnesses for long-running agents": pattern 3-agent harness - planning agent, generation agent, và evaluation agent tách biệt - cho long-running tasks. Điểm quan trọng mà Anthropic nhấn mạnh là việc tách evaluator khỏi executor là "strong lever" để improve quality, vì model đóng vai executor sẽ bị confirmation bias khi tự đánh giá output của mình.
Và OpenAI, đầu 2026, tiết lộ rằng một internal product của họ - với hơn 1 triệu dòng code, zero human-written - được build hoàn toàn trên agent infrastructure. Thesis của họ sau quá trình đó: "Agents aren't hard; the harness is hard."
Có một timeline rõ ràng ở đây nếu bạn nhìn lại vài năm qua. 2022-2024 là giai đoạn Prompt Engineering - cộng đồng đổ công sức vào tối ưu input cho model, tìm cách viết prompts tốt hơn để model trả lời chính xác hơn. 2025 là Context Engineering - chú ý chuyển sang tối ưu context window, RAG pipelines, memory systems. 2026 là Harness Engineering - tối ưu toàn bộ infrastructure bọc quanh model, không chỉ input. Mỗi giai đoạn là một bước mở rộng phạm vi tối ưu hóa, từ input → context → toàn bộ system. Theo nghĩa đó, "Harness Engineering" là tên gọi cho một sự dịch chuyển có thật trong cách industry tiếp cận AI agents.
Stripped of the buzzword, còn lại gì?
Mình đã cố làm một mental exercise: bỏ hết cái từ "Harness Engineering" đi, nhìn vào danh sách kỹ năng cần thiết. Routing logic. Caching strategy. Error handling và retry logic. Permission models. State management. Observability. Circuit breakers. Middleware patterns.
Đây là systems engineering. Đây là những thứ backend engineers và platform engineers đã làm từ trước khi ChatGPT ra đời, từ trước khi "AI Engineering" là một job title.

Có một irony đáng suy nghĩ ở đây: kỹ năng quan trọng nhất trong "AI Engineering" năm 2026 không phải hiểu transformer architecture, không phải biết fine-tuning, không phải có kinh nghiệm với GPU clusters. Mà là biết thiết kế systems. Message queues. Retry policies. Permission systems. State machines. Những thứ mà software engineers đã làm từ rất lâu, và đã làm tốt.
Tin tốt, đặc biệt nếu bạn là developer đang lo lắng rằng mình không có background ML để làm AI work: bạn không cần PhD để contribute vào AI agent infrastructure. Nếu bạn đã từng design một permission system, implement dead letter queue, hoặc viết retry logic với exponential backoff - bạn đã có foundation mà nhiều "AI Engineers" đang thiếu.
Mình cũng muốn thành thật về phần ngược lại: việc đặt tên cho một discipline không hoàn toàn vô nghĩa. "Harness Engineering" như một label giúp identify rằng đây là area cần đầu tư, thay vì cứ focus vào model selection và prompt tuning. Nó giúp mọi người communicate rõ hơn - "chúng ta cần cải thiện harness" cụ thể hơn "chúng ta cần làm agent tốt hơn". Đó là giá trị thật của naming, tách biệt khỏi toàn bộ noise xung quanh nó.
Nhưng naming không phải là khoá học $297. Và đó là điều mình vẫn mệt.
Mình bắt đầu bài này với frustration, và sau khi đào xong, mình vẫn còn một chút frustration - nhưng đối tượng đã thay đổi.
Frustration ban đầu là với cái từ mới. Frustration bây giờ là với pattern xung quanh nó: người thật sự build Claude Code và LangChain publish detailed technical findings về harness design, trong khi phần lớn noise trên internet là "Top 5 harness engineering tips to 10x your agents" từ người chưa bao giờ debug một agent loop. Khoảng cách giữa chất lượng của primary sources và chất lượng của discourse xung quanh nó ngày càng lớn, và cái pattern này không phải chỉ với Harness Engineering.
Concept đằng sau Harness Engineering thì thật sự quan trọng - model không phân biệt agent giỏi và agent dở, harness làm điều đó. Cái tên mới là marketing repackaging của systems engineering. Hai điều này đều đúng cùng lúc, và mình nghĩ người đọc xứng đáng được nghe cả hai thay vì chỉ một.
Có lẽ thứ mình cần không phải một keyword mới để follow. Mà là ngồi xuống đọc code thật: Claude Code source code, LangGraph architecture, cách họ thiết kế harness từng layer. Đó là cách học mà không khoá học nào replace được - và cũng là cách học mà mình muốn làm trong vài tuần tới.
Nếu bạn đang nghĩ tương tự, mình muốn nghe bạn đang đào gì.
Bài này được viết khi mình ... đi bệnh viện và ngồi đợi ...
Bình